
DeepMind联创Suleyman创办的Inflection AI近日发布Inflection-1大模型。
Inflection-1在一个非常大的数据集上使用数千个NVIDIA H100 GPU进行训练。我们的团队已经能够利用我们的端到端管道来开发一些专有技术进步,从而实现这些结果。本技术备忘录总结了我们的评估,并将我们的绩效与其他大模型进行了比较。
论文地址:https://inflection.ai/assets/Inflection-1.pdf
资讯地址:https://inflection.ai/inflection-1
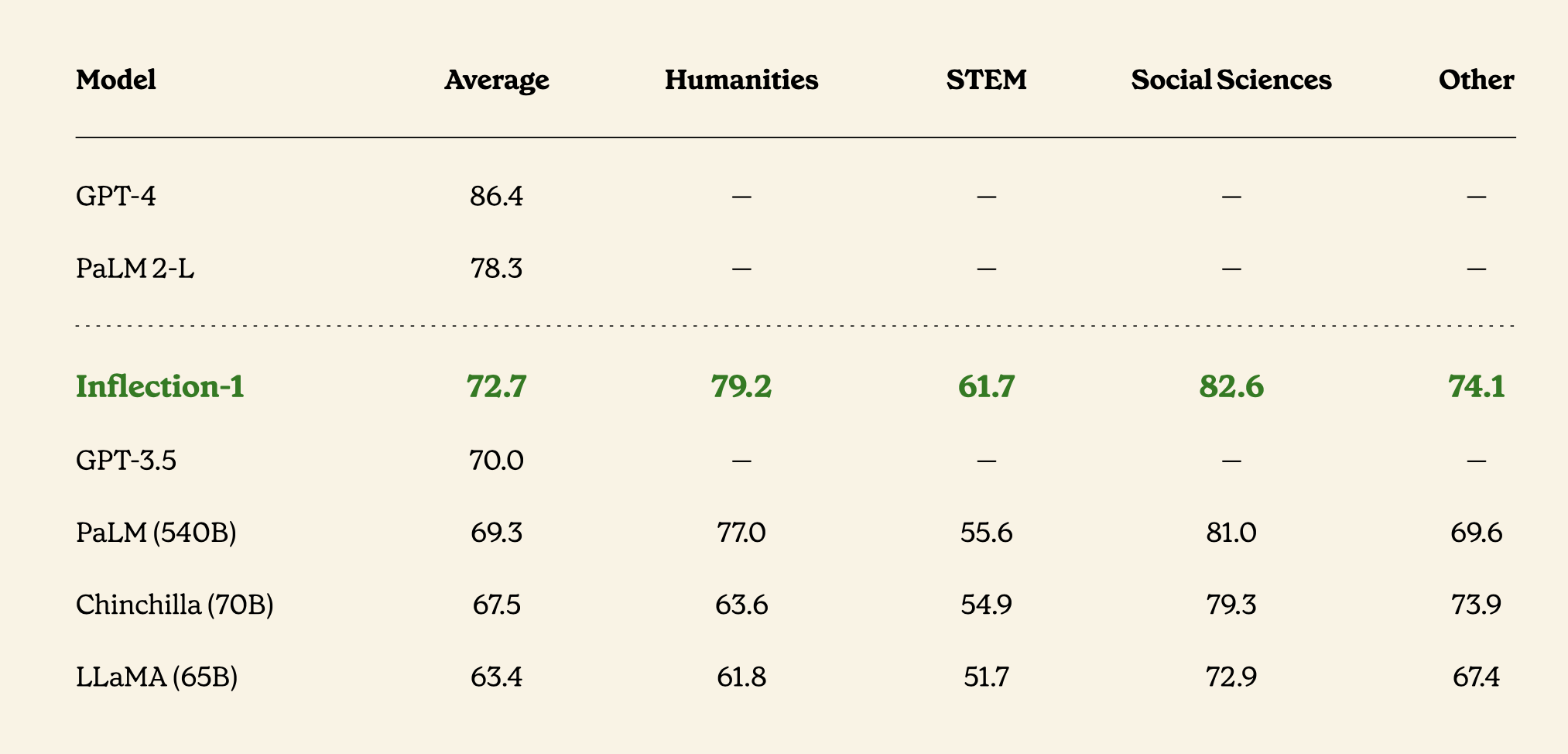
Inflection-1是其计算类中最好的模型,其性能优于GPT-3.5、LLAMA、Chinchilla和PaLM-540B。我们还将发布一份技术备忘录,详细介绍我们与PaLM-2和GPT-4在同一计算类中的模型之一。
在琐事风格的问题回答方面,我们的模型的表现远远优于LLAMA,并与谷歌最近的旗舰型号PaLM 2-L具有竞争力。对于TriviaQA,我们展示了两个不同的评估拆分,使我们能够与LLAMA、Chinchilla和PaLM进行比较。
我们认为,在创造高质量、安全和有用的人工智能体验方面,预培训与微调一样重要。这就是为什么我们开始开发自己的最先进的LLM。作为一个垂直集成的人工智能工作室,我们为人工智能培训和推理做一切:从数据摄取,到模型设计,再到高性能基础设施。
为了为我们的用户提供卓越的质量和速度,我们需要开发一个既能在生产中扩展的模型,又比广泛部署的LLM(如GPT-3.5和LLAMA)更强大。我们很高兴地分享,我们现在已经实现了这一目标。
Inflection-1在一个非常大的数据集上使用数千个NVIDIA H100 GPU进行训练。我们的团队已经能够利用我们的端到端管道来开发一些专有技术进步,从而实现这些结果。
备忘录显示,Inflection-1是其计算类中最好的模型,在通常用于比较LLM的广泛基准上,其性能优于GPT-3.5、LLAMA、Chinchilla和PaLM-540B。我们还将发布一份技术备忘录,详细介绍我们与PaLM-2和GPT-4在同一计算类中的模型之一。
这是一项我们引以为豪的成就,一年多前刚刚开始Inflection。随着我们继续扩大规模和创新,以完成我们的使命,构建数百万用户可访问的最强大、最安全的人工智能产品,我们预计未来几个月将出现巨大的改进。
评估结果摘要
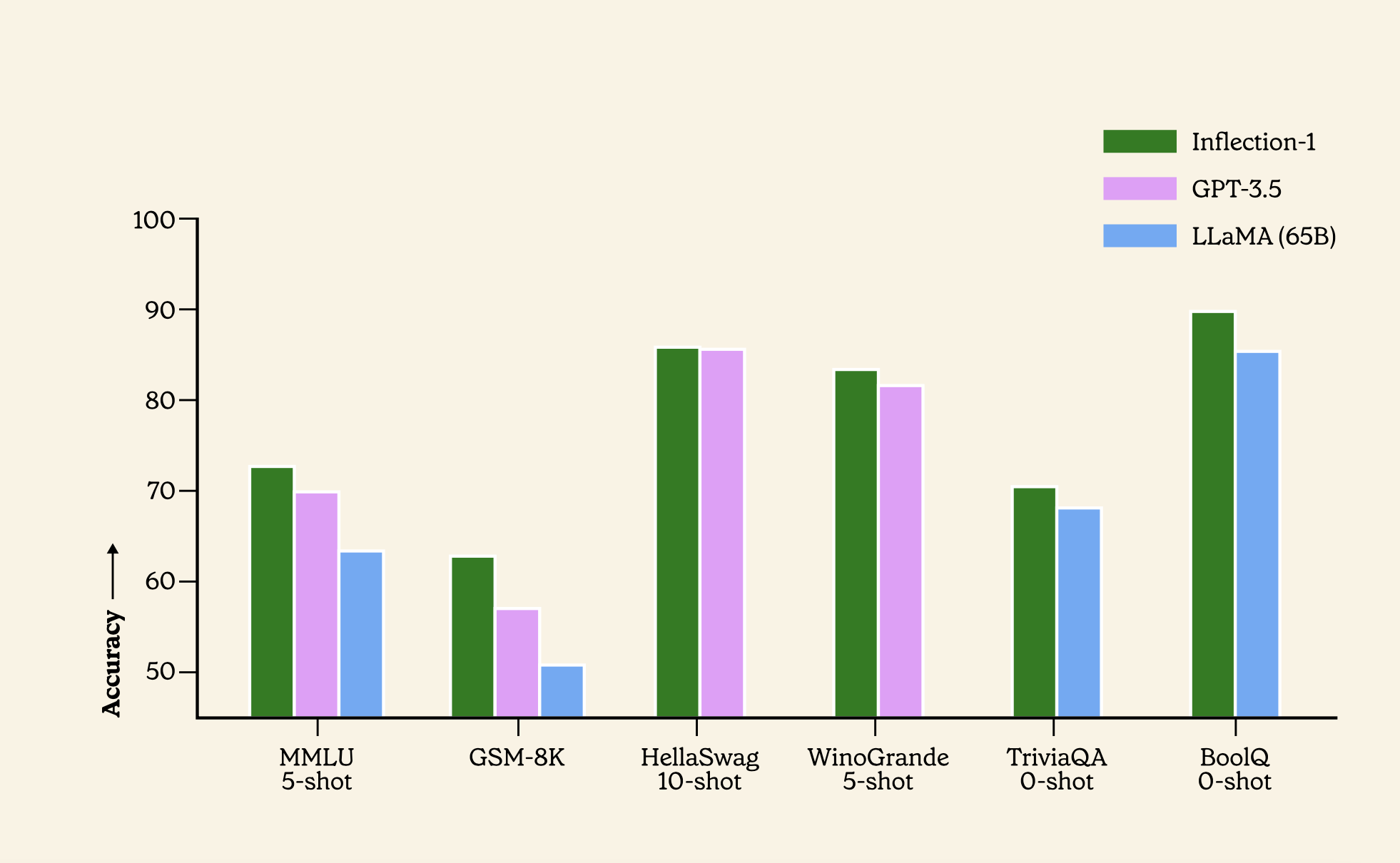
我们针对同一计算类中的模型在广泛的基准上评估了Inflection-1,定义为最多使用PaLM-540B的FLOP训练的模型。以下是六个最受欢迎的基准的摘要。
Inflection-1在MMLU上设定了新标准
大规模多任务语言理解(MMLU)是一个常用的基准,用于测试非常广泛的学术知识。该基准包括57个不同类别的考试,从高中和大学到专业水平的难度。
在这个基准上,我们的模型是同类中表现最好的基础模型,优于Meta的LLAMA、OpenAI的GPT 3.5和谷歌的PaLM 540B。
Inflection-1在所有57个任务中平均达到72.7%,在5个不同任务上的准确率超过90%。在15个任务中,Inflection-1实现了超过85%的准确率。相比之下,人类专家的平均得分为89.8%,而人类评分者的平均得分为34.5%。
我们将Inflection-1与MMLU基准上的许多模型进行比较。我们的模型优于我们计算类中的所有模型,包括GPT-3.5和LLAMA。
Inflection-1在琐事问题上要好得多
在TriviaQA和Natural Questions上,衡量语言模型的封闭式书题回答能力的两个基准,Inflection-1的表现优于LLAMA、Chinchilla和PaLM 540B,将LLAMA的TriviaQA性能提高了2.1%。在自然问题上,我们的模型比PaLM 540B高出8.6%,LLA高出6%。事实上,我们的型号与谷歌最新的旗舰型号PaLM 2-L具有竞争力。

在琐事风格的问题回答方面,我们的模型的表现远远优于LLAMA,并与谷歌最近的旗舰型号PaLM 2-L具有竞争力。对于TriviaQA,我们展示了两个不同的评估拆分,使我们能够与LLAMA、Chinchilla和PaLM进行比较。
值得注意的是,我们在备忘录中介绍的结果是Inflection-1基础模型的结果,该模型没有经过任何微调或对齐。Pi由Inflection-1提供动力,Inflection-1已通过专有适应过程进一步转型,成为有用且安全的个人人工智能。我们计划在未来的技术备忘录中发布我们安全方法的更多细节。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢