
GKD: Generalized Knowledge Distillation for Auto-regressive Sequence Models
R Agarwal, N Vieillard, P Stanczyk, S Ramos, M Geist, O Bachem
[Google DeepMind]
GKD:用于自回归序列模型的广义知识蒸馏
-
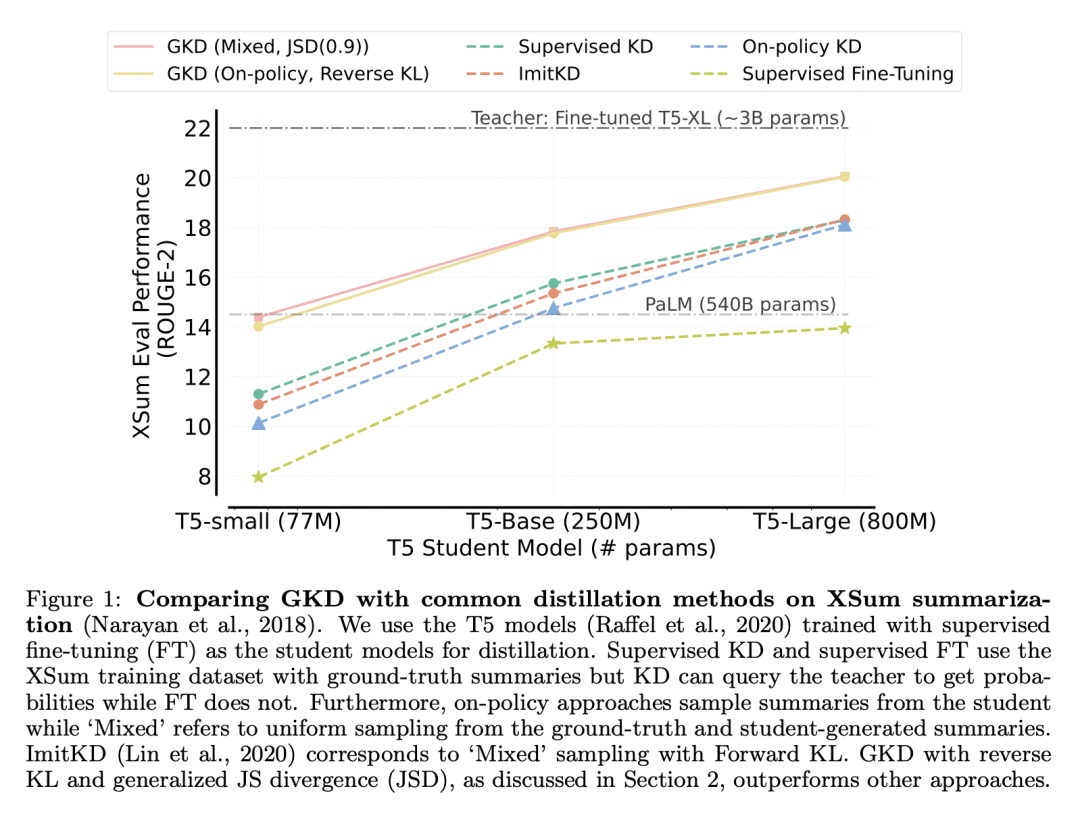
动机:当前的自回归模型知识蒸馏方法存在两个关键问题:1.训练期间的输出序列与学生在部署期间生成的序列之间的分布不匹配;2.模型规格不足,即学生模型可能无法表达教师的分布。为了解决这些问题,本文提出广义知识蒸馏(GKD)。 -
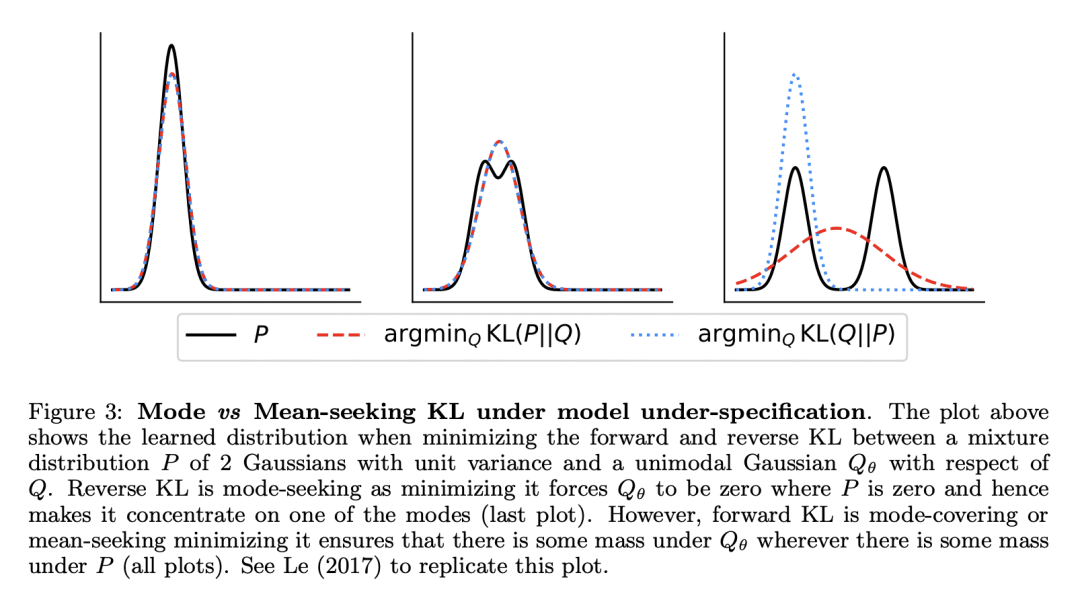
方法:通过在训练期间从学生中采样输出序列来缓解分布不匹配。此外,GKD通过优化替代差异,如反向KL,这些差异专注于生成来自学生的样本,这些样本在教师的分布下可能。本文证明GKD在摘要、机器翻译和算术推理任务上超越了常用的LLM蒸馏方法。 优势:所提出方法在自然语言生成任务上的表现一直优于更常用的知识蒸馏基线。进一步展示了该方法可以与强化学习结合,以优化序列级奖励,除了蒸馏大型教师模型的知识。
提出一种名为广义知识蒸馏(GKD)的方法,可以解决自回归模型在知识蒸馏过程中面临的分布不匹配和模型规格不足的问题,在自然语言生成任务上的表现一直优于更常用的知识蒸馏基线。
https://arxiv.org/abs/2306.13649
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢