
The Inductive Bias of Flatness Regularization for Deep Matrix Factorization
Khashayar Gatmiry, Zhiyuan Li, Ching-Yao Chuang, Sashank Reddi, Tengyu Ma, Stefanie Jegelka
[MIT & Stanford University & Google]
深度矩阵分解中平坦正则化的归纳偏差
要点:
-
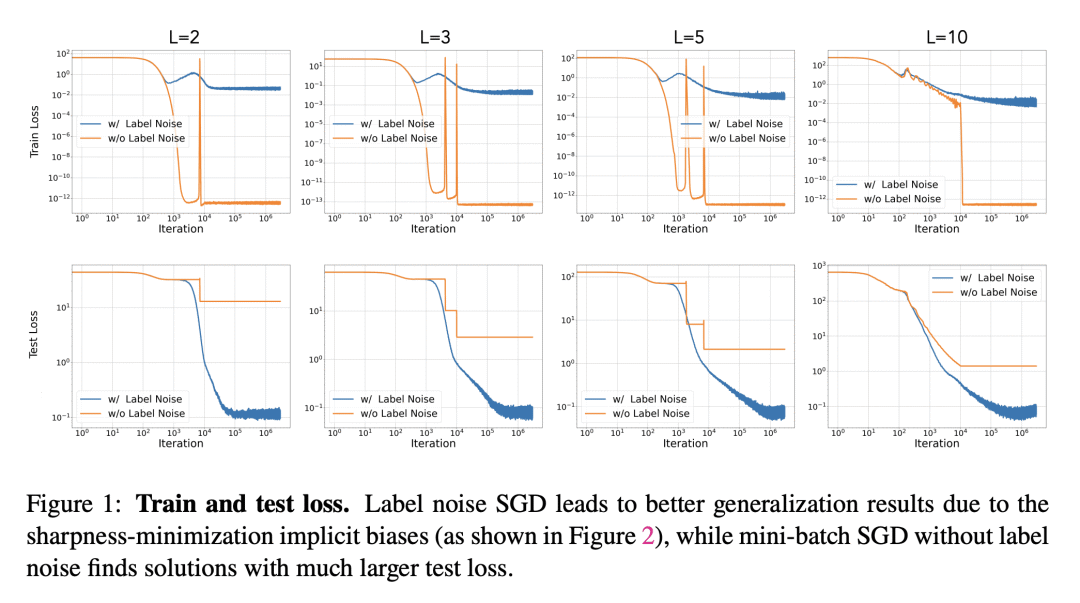
动机:试图理解深度矩阵分解中最小Hessian迹解的归纳偏差,这是一个重要的理论深度学习设置。尽管过参数化的神经网络具有巨大的模型容量,但它们在使用随机梯度下降(SGD)或其变体进行训练时却能很好地泛化。最近的研究提出了SGD的隐式偏差作为可能的解释。 -
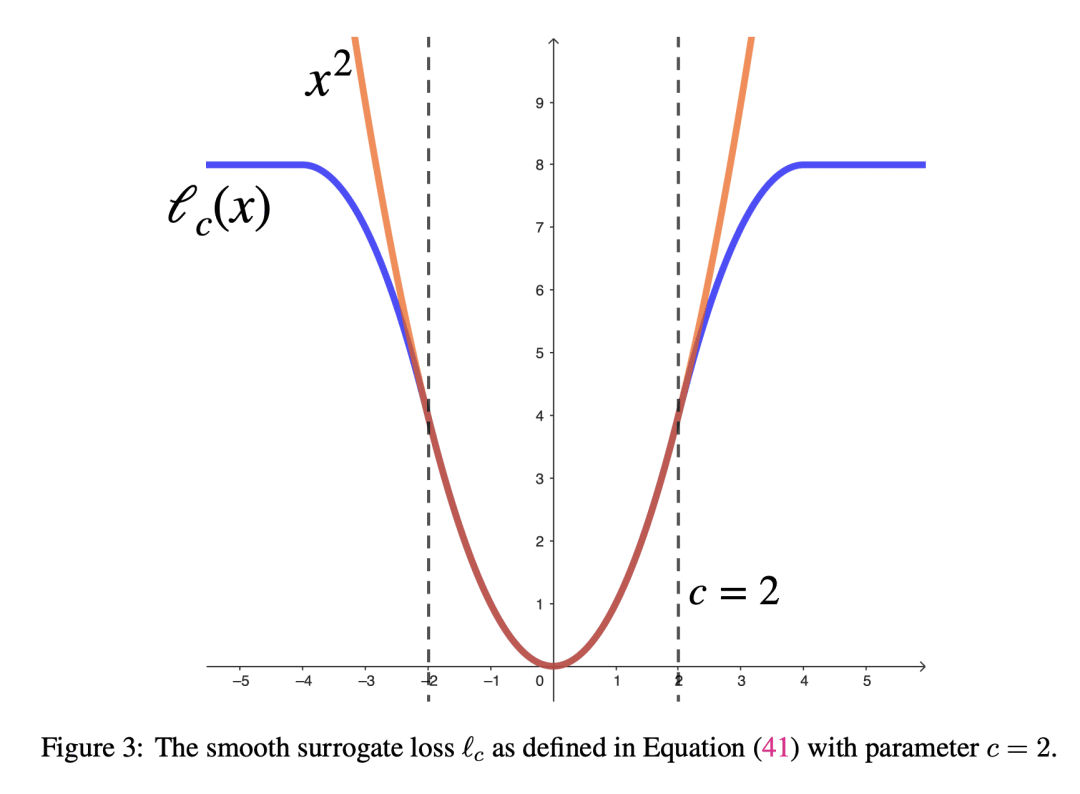
方法:首先定义了诱导正则化器,该正则化器是在给定端到端参数M的情况下,最小化Hessian迹的训练损失。证明了在满足RIP属性的数据下,诱导正则化器的性质。此外,还为以下两种情况推导出了诱导正则化器的闭合形式:(1)深度L等于2;(2)只有一个测量,即n=1。利用诱导正则化器的这种特性,得出了关于泛化界的一些结果。 -
优势:揭示了在满足RIP属性的数据下,最小Hessian迹解的归纳偏差与端到端矩阵的核范数最小化有关。这为理解和利用深度学习模型的泛化性能提供了新的视角。
研究了深度矩阵分解中最小Hessian迹解的归纳偏差,揭示了其与端到端矩阵的核范数最小化的关系,为理解和利用深度学习模型的泛化性能提供了新的视角。
https://arxiv.org/abs/2306.13239
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢