

Supervised Pretraining Can Learn In-Context Reinforcement Learning
Jonathan N. Lee, Annie Xie, Aldo Pacchiano, Yash Chandak, Chelsea Finn, Ofir Nachum, Emma Brunskill
[Stanford University & Microsoft Research & Google DeepMind]
监督预训练可学习进行上下文强化学习
-
动机:大型Transformer模型在多样化的数据集上进行训练,已经展示出了显著的在上下文学习的能力,能在没有明确训练解决的任务上实现高效的少样本性能。本文研究了Transformer在决策问题中的在上下文学习能力,即对于bandits和马尔可夫决策过程的强化学习(RL)。 -
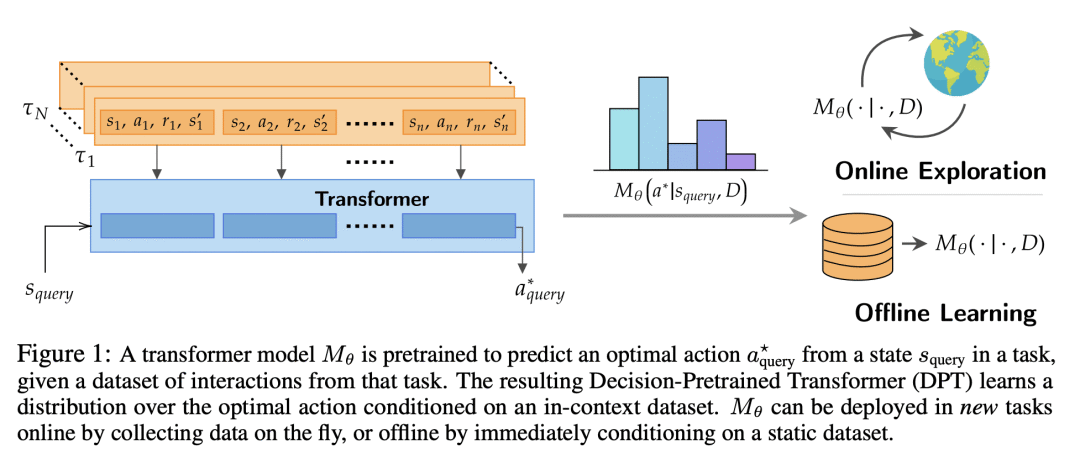
方法:引入并研究了决策预训练Transformer(DPT),一种监督预训练方法,其中Transformer预测给定查询状态和在上下文中的交互数据集的最优行动,跨越多样的任务集。这个过程虽然简单,但产生了一个具有几项惊人能力的模型。 -
优势:发现预训练的Transformer可以用来在上下文中解决一系列的RL问题,展示出在线探索和离线保守的特性,尽管没有明确训练去做这些。模型还能超越预训练分布,适应新任务,并自动适应其决策策略以适应未知结构。从理论上,本文展示了DPT可以被视为贝叶斯后验抽样的有效实现,这是一个可证明的样本高效的RL算法。
提出一种名为决策预训练Transformer(DPT)的方法,通过监督预训练,使Transformer能预测给定查询状态和在上下文中的交互数据集的最优行动,从而在上下文中解决一系列的强化学习问题。
https://arxiv.org/abs/2306.14892
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢