
我们知道,将激活、权重和梯度量化为 4-bit 对于加速神经网络训练非常有价值。但现有的 4-bit 训练方法需要自定义数字格式,而当代硬件不支持这些格式。在本文中,清华朱军等人提出了一种使用 INT4 算法实现所有矩阵乘法的 Transformer 训练方法。
模型训练得快不快,这与激活值、权重、梯度等因素的要求紧密相关。神经网络训练需要一定计算量,使用低精度算法(全量化训练或 FQT 训练)有望提升计算和内存的效率。FQT 在原始的全精度计算图中增加了量化器和去量化器,并将昂贵的浮点运算替换为廉价的低精度浮点运算。
对 FQT 的研究旨在降低训练数值精度,同时降低收敛速度和精度的牺牲。所需数值精度从 FP16 降到 FP8、INT32+INT8 和 INT8+INT5。FP8 训练通过有 Transformer 引擎的 Nvidia H100 GPU 完成,这使大规模 Transformer 训练实现了惊人的加速。
最近训练数值精度已被压低到 4 位( 4 bits)。Sun 等人成功训练了几个具有 INT4 激活 / 权重和 FP4 梯度的当代网络;Chmiel 等人提出自定义的 4 位对数数字格式,进一步提高了精度。然而,这些 4 位训练方法不能直接用于加速,因为它们需要自定义数字格式,这在当代硬件上是不支持的。
在 4 位这样极低的水平上训练存在着巨大的优化挑战,首先前向传播的不可微分量化器会使损失函数图不平整,其中基于梯度的优化器很容易卡在局部最优。其次梯度在低精度下只能近似计算,这种不精确的梯度会减慢训练过程,甚至导致训练不稳定或发散的情况出现。
本文为流行的神经网络 Transformer 提出了新的 INT4 训练算法。训练 Transformer 所用的成本巨大的线性运算都可以写成矩阵乘法(MM)的形式。MM 形式使研究人员能够设计更加灵活的量化器。这种量化器通过 Transformer 中的特定的激活、权重和梯度结构,更好地近似了 FP32 矩阵乘法。本文中的量化器还利用了随机数值线性代数领域的新进展。
论文地址:https://arxiv.org/pdf/2306.11987.pdf
研究表明,对前向传播而言,精度下降的主要原因是激活中的异常值。为了抑制该异常值,研究提出了 Hadamard 量化器,用它对变换后的激活矩阵进行量化。该变换是一个分块对角的 Hadamard 矩阵,它将异常值所携带的信息扩散到异常值附近的矩阵项上,从而缩小了异常值的数值范围。
对反向传播而言,研究利用了激活梯度的结构稀疏性。研究表明,一些 token 的梯度非常大,但同时,其余大多数的 token 梯度又非常小,甚至比较大梯度的量化残差更小。因此,与其计算这些小梯度,不如将计算资源用于计算较大梯度的残差。
结合前向和反向传播的量化技术,本文提出一种算法,即对 Transformer 中的所有线性运算使用 INT4 MMs。研究评估了在各种任务上训练 Transformer 的算法,包括自然语言理解、问答、机器翻译和图像分类。与现有的 4 位训练工作相比,研究所提出的算法实现了相媲美或更高的精度。此外,该算法与当代硬件 (如 GPU) 是兼容的,因为它不需要自定义数字格式 (如 FP4 或对数格式)。并且研究提出的原型量化 + INT4 MM 算子比 FP16 MM 基线快了 2.2 倍,将训练速度提高了 35.1%。
实验结果
研究在各种任务中评估了 INT4 训练算法,包括语言模型微调、机器翻译和图像分类。研究使用了 CUDA 和 cutlass2 实现了所提出的 HQ-MM 和 LSS-MM 算法。除了简单地使用 LSQ 作为嵌入层外,研究用 INT4 替换了所有浮点线性运算符,并保持最后一层分类器的全精度。并且,在此过程中,研究人员对所有评估模型采用默认架构、优化器、调度器和超参数。
收敛模型精度。下表 1 展示了收敛模型在各任务上的精度。
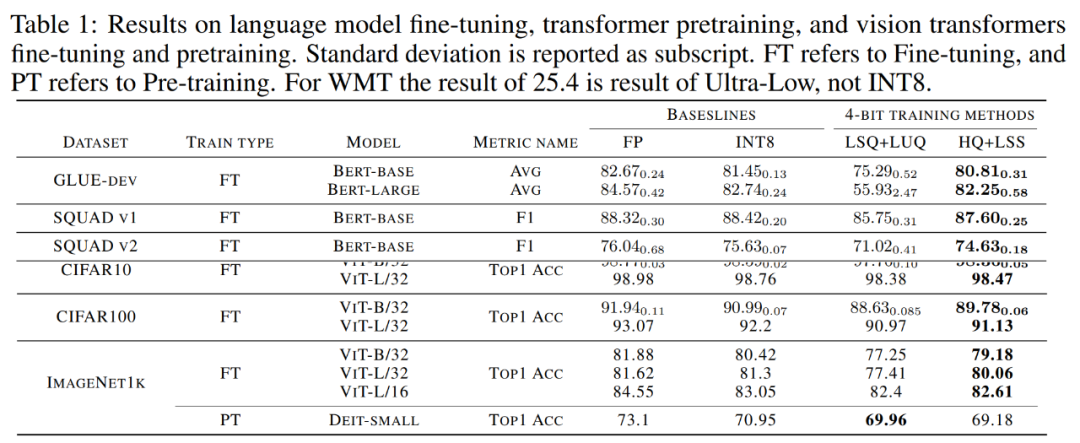
语言模型微调。与 LSQ+LUQ 相比,研究提出的算法在 bert-base 模型上提升了 5.5% 的平均精度、,在 bert-large 模型上提升了 25% 的平均精度。
研究团队还展示了算法在 SQUAD、SQUAD 2.0、Adversarial QA、CoNLL-2003 和 SWAG 数据集上进一步展示了结果。在所有任务上,与 LSQ+LUQ 相比,该方法取得了更好的性能。与 LSQ+LUQ 相比,该方法在 SQUAD 和 SQUAD 2.0 上分别提高了 1.8% 和 3.6%。在更困难的对抗性 QA 中,该方法的 F1 分数提高了 6.8%。在 SWAG 和 CoNLL-2003 上,该方法分别提高了 6.7%、4.2% 的精度。
机器翻译。研究还将所提出的方法用于预训练。该方法在 WMT 14 En-De 数据集上训练了一个基于 Transformer 的 [51] 模型用于机器翻译。
HQ+LSS 的 BLEU 降解率约为 1.0%,小于 Ultra-low 的 2.1%,高于 LUQ 论文中报道的 0.3%。尽管如此,HQ+LSS 在这项预训练任务上的表现仍然与现有方法相当,并且它支持当代硬件。
图像分类。研究在 ImageNet21k 上加载预训练的 ViT 检查点,并在 CIFAR-10、CIFAR-100 和 ImageNet1k 上对其进行微调。
与 LSQ+LUQ 相比,研究方法将 ViT-B/32 和 ViT-L/32 的准确率分别提高了 1.1% 和 0.2%。在 ImageNet1k 上,该方法与 LSQ+LUQ 相比,ViT-B/32 的精度提高了 2%,ViT-L/32 的精度提高了 2.6%,ViT-L/32 的精度提高了 0.2%。
研究团队进一步测试了算法在 ImageNet1K 上预训练 DeiT-Small 模型的有效性,其中 HQ+LSS 与 LSQ+LUQ 相比仍然可以收敛到相似的精度水平,同时对硬件更加友好。
消融研究
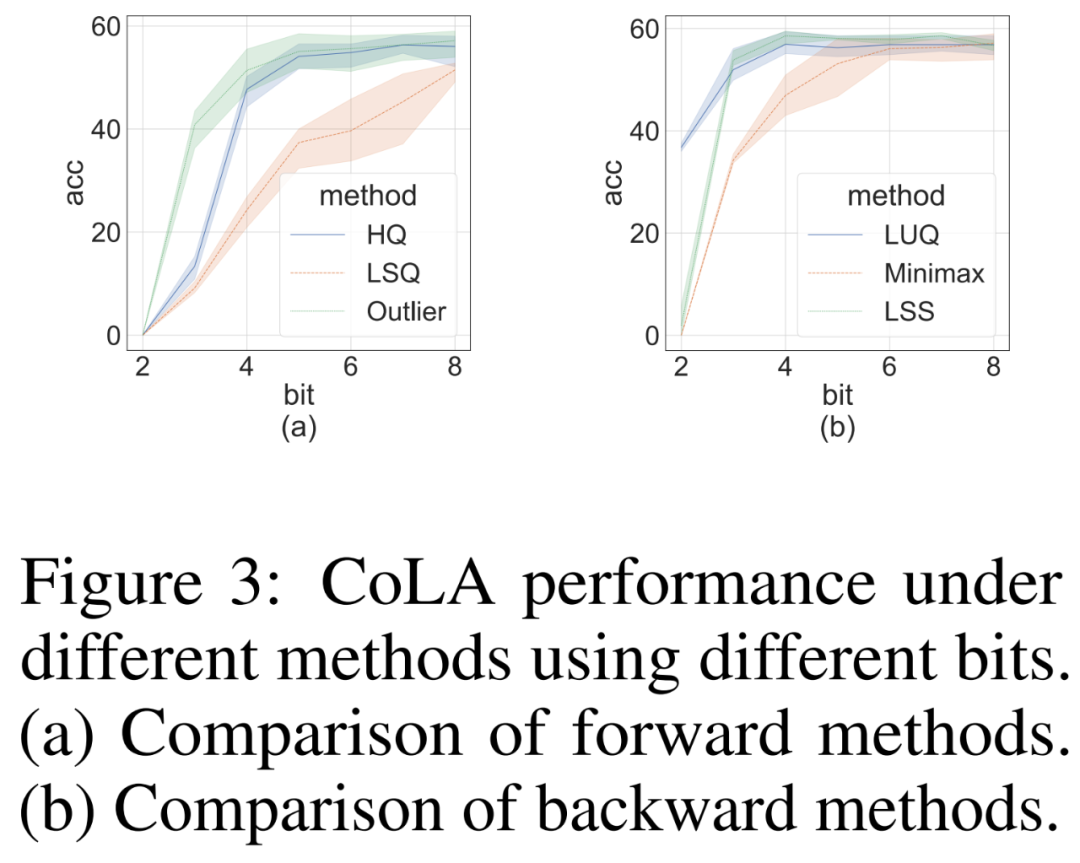
研究者进行消融研究,以独立地在挑战性 CoLA 数据集上展示前向和反向方法的有效性。为了研究不同量化器对前向传播的有效性,他们将反向传播设置为 FP16。结果如下图 3 (a) 所示。
对于反向传播,研究者比较了简单的极小极大量化器、LUQ 和他们自己的 LSS,并将前向传播设置为 FP16。结果如下图 3 (b) 所示,虽然位宽高于 2,但 LSS 取得的结果与 LUQ 相当,甚至略高于后者。
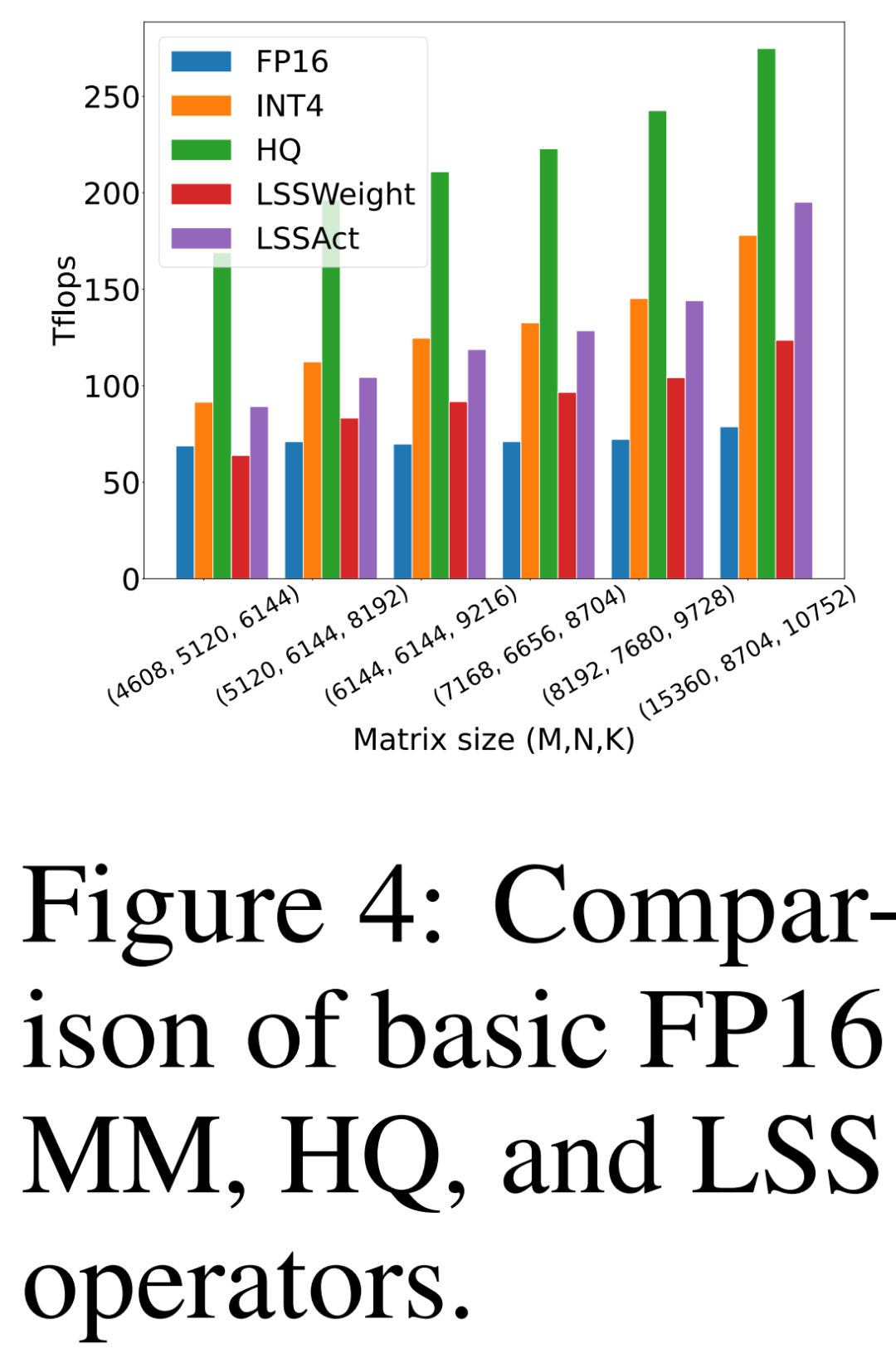
计算和内存效率
研究者比较自己提出的 HQ-MM (HQ)、计算权重梯度的 LSS(LSSWeight)、计算激活梯度的 LSS(LSSAct)的吞吐量、它们的平均吞吐量(INT4)及下图 4 中英伟达 RTX 3090 GPU 上 cutlass 提供的基线张量核心 FP16 GEMM 实现(FP16),它的峰值吞吐量为 142 FP16 TFLOPs 和 568 INT4 TFLOPs。
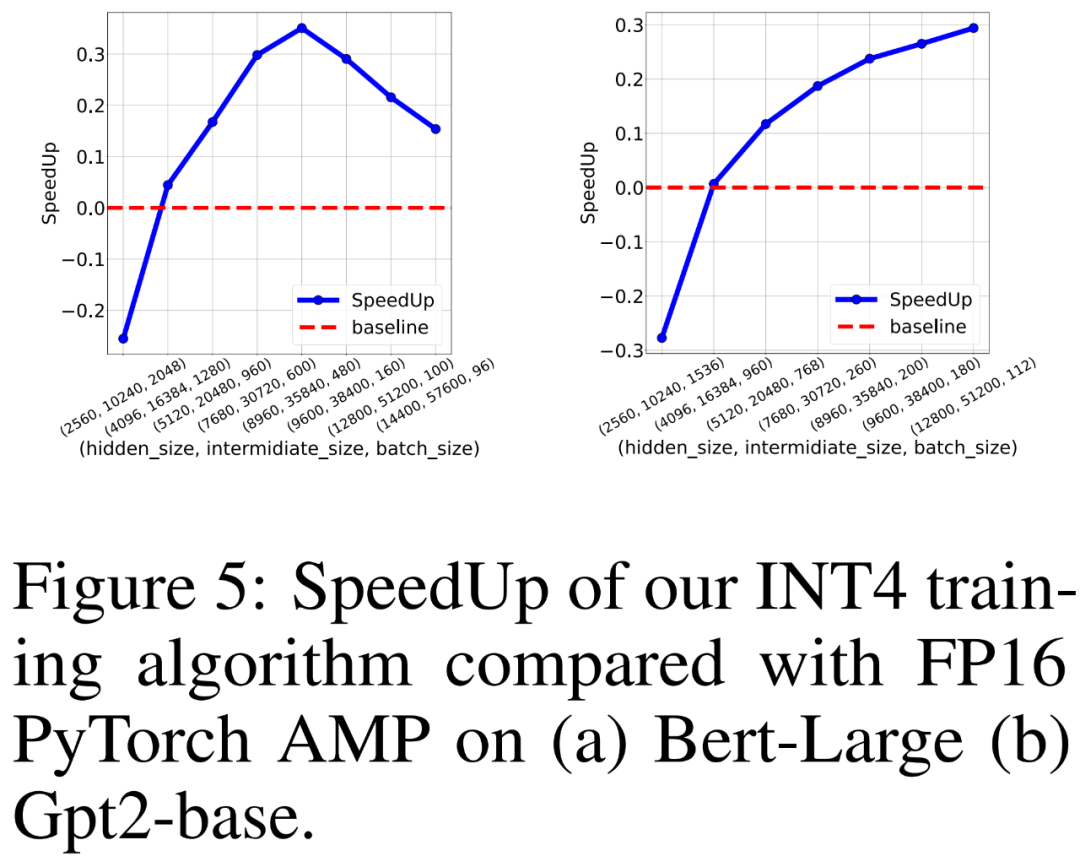
研究者还比较 FP16 PyTorch AMP 以及自己 INT4 训练算法在 8 个英伟达 A100 GPU 上训练类 BERT 和类 GPT 语言模型的训练吞吐量。他们改变了隐藏层大小、中间全连接层大小和批大小,并在下图 5 中绘制了 INT4 训练的加速比。
结果显示,INT4 训练算法对于类 BERT 模型实现了最高 35.1% 的加速,对于类 GPT 模型实现了最高 26.5% 的加速。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢