
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, Enhong Chen
[USTC & Tencent YouTu Lab]
A Survey on Multimodal Large Language Models
-
动机:探索和总结多模态大型语言模型(MLLM)的最新进展。MLLM是一个新兴的研究热点,它使用强大的大型语言模型(LLM)作为大脑来执行多模态任务。MLLM的出现,如基于图像编写故事和无需OCR的数学推理等惊人的能力,是传统方法中罕见的,这表明了通向人工通用智能的潜在路径。
-
方法:介绍了MLLM的公式化和相关概念,讨论了关键技术和应用,包括多模态指令调整(M-IT)、多模态上下文学习(M-ICL)、多模态思维链(M-CoT)和LLM辅助视觉推理(LAVR)。最后,讨论了现有的挑战并指出了有前景的研究方向。
-
优势:详细地追踪和总结了MLLM的最新进展。收集了最新的论文,对于研究者来说是一个宝贵的资源。
详细地追踪和总结了多模态大型语言模型(MLLM)的最新进展,包括其标准化、关键技术、应用和存在的挑战,为人工智能研究者提供了宝贵的参考。
论文:
https://arxiv.org/abs/2306.13549
我们将MLLM定义为“由LLM扩展而来的具有接收与推理多模态信息能力的模型”,该类模型相较于热门的单模态LLM具有以下的优势:
-
更符合人类认知世界的习惯。人类具有多种感官来接受多种模态信息,这些信息通常是互为补充、协同作用的。因此,使用多模态信息一般可以更好地认知与完成任务。
-
更加强大与用户友好的接口。通过支持多模态输入,用户可以通过更加灵活的方式输入与传达信息。
-
更广泛的任务支持。LLM通常只能完成纯文本相关的任务,而MLLM通过多模态可以额外完成更多任务,如图片描述和视觉知识问答等。
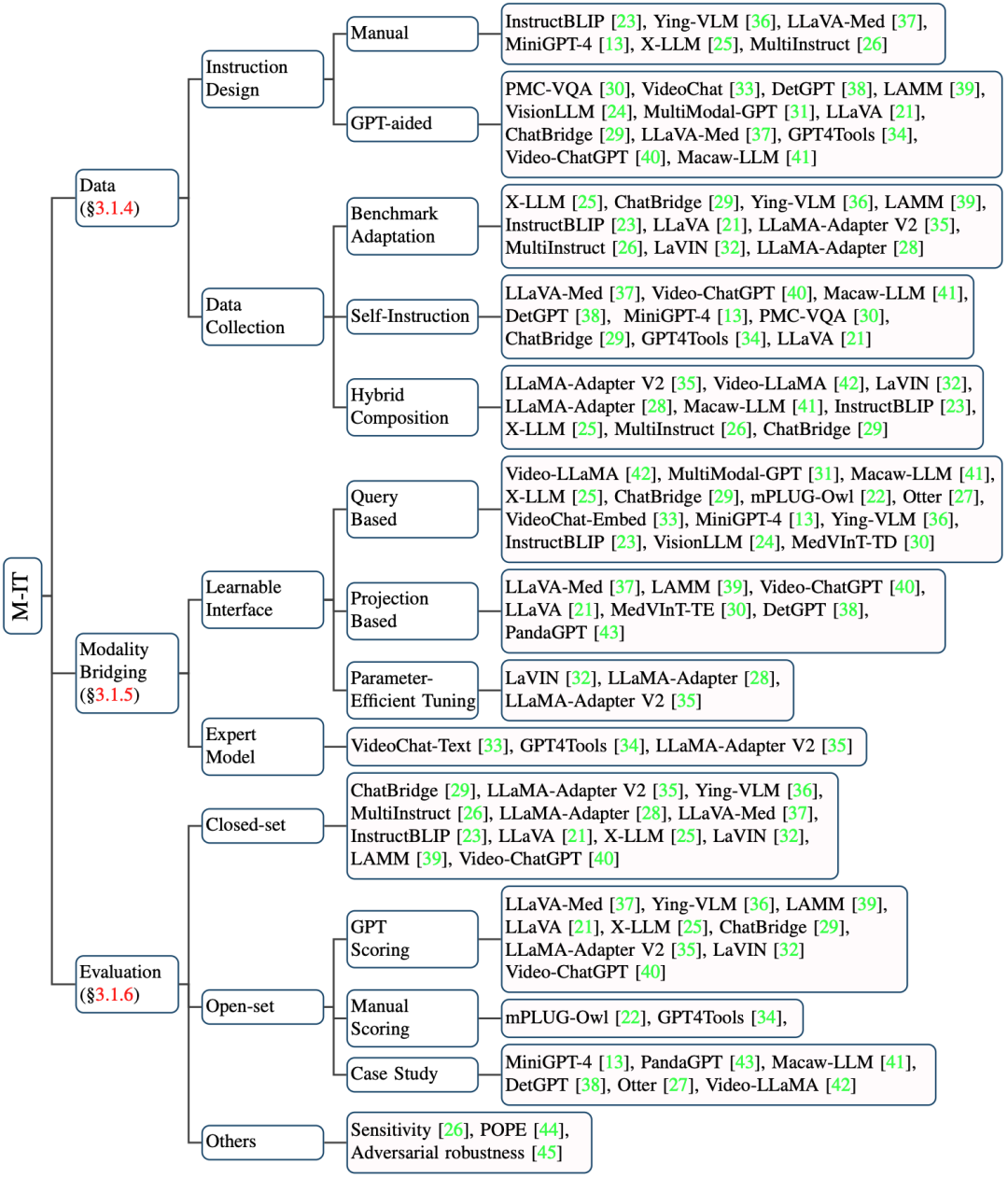
该综述主要围绕MLLM的三个关键技术以及一个应用展开,包括:
-
多模态指令微调(Multimodal Instruction Tuning,M-IT)
-
多模态上下文学习(Multimodal In-Context Learning,M-ICL)
-
多模态思维链(Multimodal Chain of Thought,M-CoT)
-
LLM辅助的视觉推理(LLM-Aided Visual Reasoning,LAVR)
前三项技术构成了MLLM的基础,而最后一个是以LLM为核心的多模态系统。三项技术作为LLM的代表性能力在NLP领域已有广泛研究,但扩展到多模态领域时会出现许多新的特点与挑战。LLM辅助的视觉推理系统涉及几种典型的设计思路,即将LLM作为控制器、决策器或语义修饰器。
CVPR2023最佳论文Visual Programming 即采用了将LLM作为控制器的设计思路。本文将对前述的几个方面以及相关挑战做简单的概览,更丰富的内容请参考原文。
项目地址:https://mp.weixin.qq.com/s/uuKi0cuX1uaZ3GEY27d39A
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢