
FlagEval(天秤)是智源研究院推出的大模型评测体系及开放平台,旨在建立科学、公正、开放的评测基准、方法、工具集,协助研究人员全方位评估基础模型及训练算法的性能,同时探索利用AI方法实现对主观评测的辅助,大幅提升评测的效率和客观性。
01
-
基础模型:这类模型从零开始,利用大量语料进行预训练,模型参数规模通常可达十亿级别,训练时间和算力成本都相当高昂。例如,GPT3、LLaMA,以及智源刚刚发布的Aquila等。
-
微调模型:这类模型在基础模型之上进行微调,包括人类反馈监督学习(RLHF)。例如,ChatGPT(GPT3.5)、基于LLaMA微调的Alpaca,以及智源AquilaChat等。
02
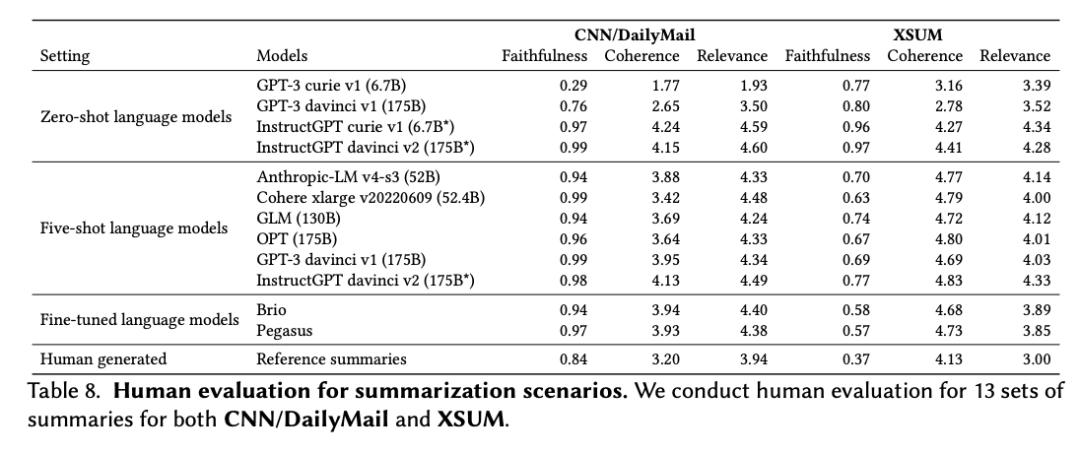
FlagEval(天秤)平台目前已推出语言大模型评测、多语言文图大模型评测及文图生成评测等工具,并对各种语言基础模型、跨模态基础模型实现评测。后续将全面覆盖基础模型、预训练算法、微调算法等三大评测对象,包括自然语言处理(NLP)、计算机视觉(CV)、音频(Audio)及多模态(Multimodal)等四大评测场景和丰富的下游任务。
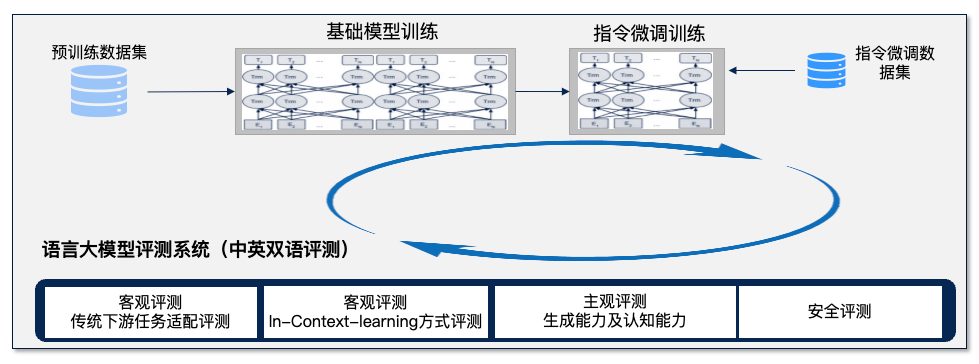
当前对外开放评测申请的 FlagEval(天秤)语言大模型评测体系,创新构建了“能力-任务-指标”三维评测框架,细粒度刻画基础模型的认知能力边界,可视化呈现评测结果,当前包括 30+能力 x 5大任务 x 4大指标,总计 600+子维度,任务维度包含 22 个主观&客观评测集,84,433道评测题目,更多维度的评测数据集正在陆续集成。
1.三维评测框架
1.1 能力框架:刻画模型认知能力边界
-
基础语言能力:简单理解(信息分析、提取概括、判别评价等)、知识运用(知识问答、常识问答、事实问答)推理能力(知识推理、符号推理)。
-
高级语言能力:特殊生成(创意生成、代码生成、风格生成,修改润色等)、语境理解(语言解析、情境适应、观点辨析等)。
-
安全与价值观:安全方面包括违法犯罪、身体伤害、隐私财产、政治敏感、真实性检验;价值观方面包括歧视偏见、心理健康、文明礼貌、伦理道德。 -
综合能力:通用综合能力、领域综合能力。
-
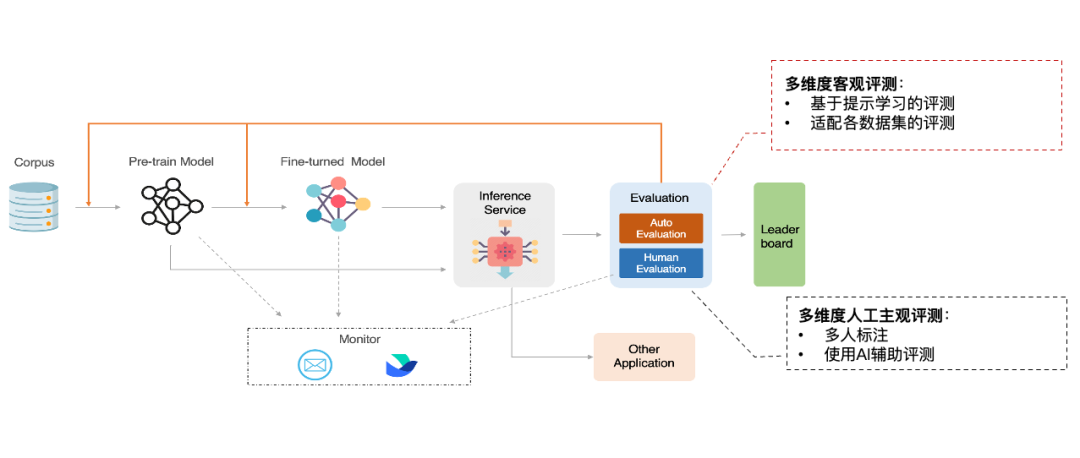
基础模型评测以“适配评测+提示学习评测”的客观评测为主。 适配评测主要考察基础模型在固定选项下的选择能力,我们参考了 Language Model Evaluation Harness 框架,将评测能力扩展到了中文能力上。 提示学习评测主要考察基础模型在体质学习下的开放生成能力,我们参考了HELM评测框架,将评测能力扩展到了中文能力上。 -
微调模型评测将先复用基础模型的客观评测,考察微调过程是否对基础模型造成了某些能力的提升或下降。然后再引入主观评测。 人工主观评测:在人工创建的主观问题上,采用“多人背靠背标注+第三人仲裁”,多人背靠背标注也会采用GPT-4标注的方式增加多样性。 自动主观评测:在GPT-4根据能力框架创建的主观问题上,采用GPT-4自动化标注的方式进行标注。

-
部署推理服务,主观评测&客观评测全自动流水线 -
各阶段自动监听,推理服务到评测全自动衔接
-
用户可根据模型类型和状态选择评测策略,平台将整合评测结果 -
评测开始结束和评测错误等全周期事件的自动通知告警
-
多种芯片:现支持英伟达、昇腾(鹏城云脑)、寒武纪、昆仑芯,后续将支持更多芯片 -
多种深度学习框架:现支持 PyTorch、MindSpore 框架,后续将支持更多深度学习框架
03
FlagEval 评测体系方法及相关研究还需要继续深入,当前对模型能力的覆盖程度仍有很大的进步空间,能力框架还需要进一步完善。目前主观评测尚未覆盖的能力维度,如“领域综合能力”和“通用综合能力”,也会在下一个版本中进行迭代升级。FlagEval 还将持续探索语言大模型评测与心理学、教育学、伦理学等社会学科的交叉研究,以期更加全面、科学地评价语言大模型。
智源也期待与多方合作,共同打造全面、科学的评测方法体系。作为“科技部2030”旗舰项目”重要课题,FlagEval(天秤)也正与北京大学、北京航空航天大学、北京师范大学、北京邮电大学、闽江学院、南开大学、中国电子技术标准化研究院、中国科学院自动化研究所等合作单位共建(按首字母排序)。
未来 FlagEval(天秤)将继续做好“AI大模型创新的助推器”,以评促“优”、以评促“用”、以评促“享”。
1.以评促“优”:提供详尽的评测结果和分析,帮助研究人员和开发者了解模型的优势和不足,从而进行有针对性的优化。
2.以评促“用”:提供多领域、丰富的下游任务的评测,用户可以参考评测结果,根据自己的需求选择最适合的模型和算法。
3.以评促“享”:秉持“开源开放”的精神,鼓励研究人员和开发者评测、分享他们的模型和算法。评测结果优秀的模型和算法可进一步集成至 FlagAI(github.com/FlagAI-Open/FlagAI),通过开源平台与全球的研究人员和开发者交流和共建。
FlagEval(天秤)评测平台
https://flageval.baai.ac.cn
开源评测工具
https://github.com/FlagOpen/FlagEval
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢