
LaVIN-lite:在一个具有竞争力性能的GPU上训练您自己的多模态大语言模型。
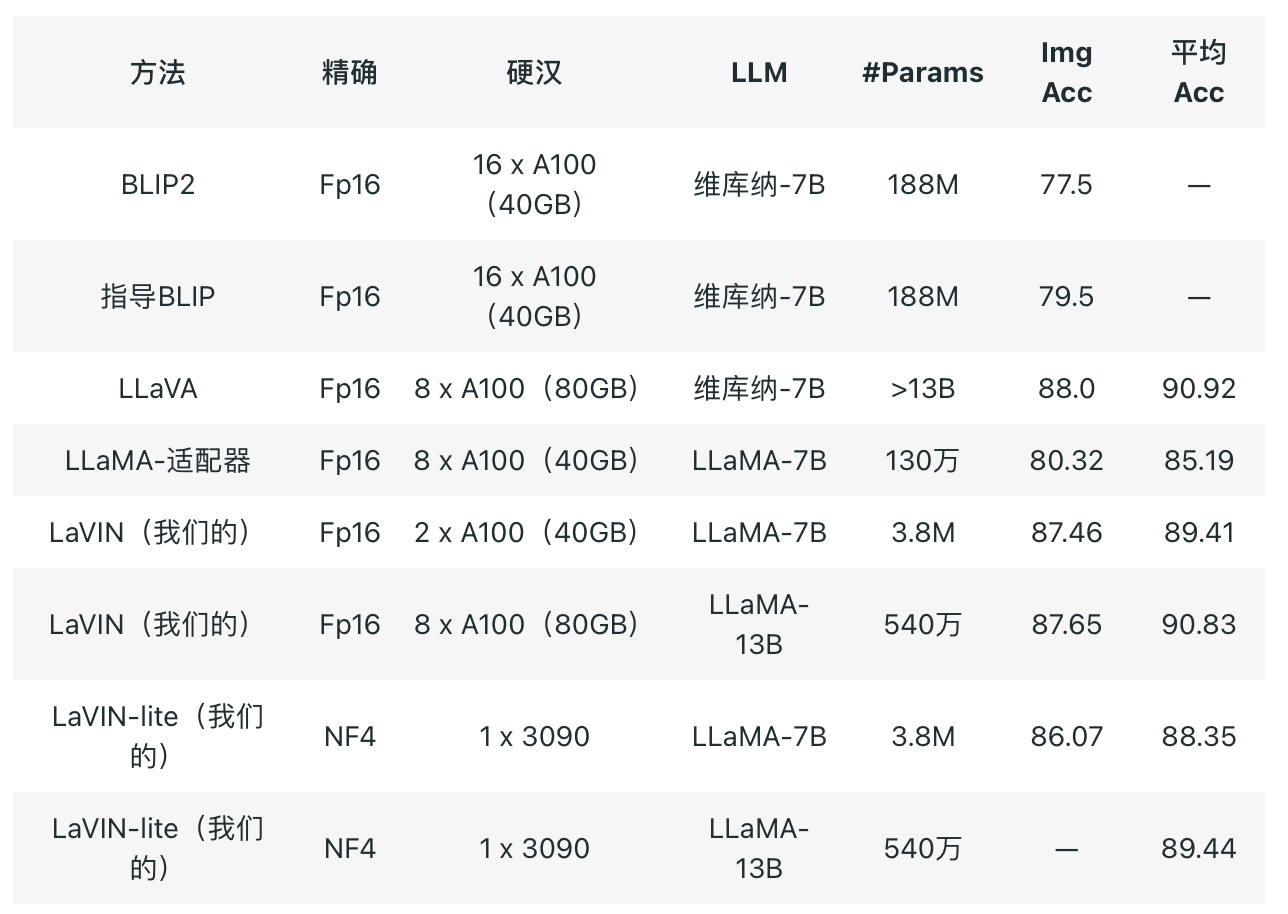
LaVIN-lite的性能仍然远远超过参数高效方法LLA-Adapter,但与LaVIN的16位训练相比,性能略有下降。我们推测原因可能是在4位培训期间需要插入更多的适配器进行适应。我们欢迎每个人根据这个基线进一步探索和比较。

经过一些技术优化后,LaVIN只需要额外的3-5M参数和最低的8G GPU内存成本,即可将LLaMA扩展到多模态任务,完成图像文本问题回答、对话和纯文本任务等任务。
技术细节摘要
新提出的参数高效调优方法(请参阅LaVIN的论文):降低大量GPU内存成本
4位量化调优:减少约3~8GB的内存使用量
梯度累积+梯度检查点:减少约一半的GPU内存使用量
分页优化器
大型多模态法学硕士的高效参数调整。
我们在LaVIN中提出了一种新的参数高效调谐方法。当整个LLM参数被冻结时,可以实现:
大型多式联运LLM的高效参数调整(只需额外花费3-6M参数)
高效的端到端培训(将培训时间减少2/3)
在单模态(仅文本输入)和多模态任务(文本和图像输入)之间自动切换。
通过这种方式,我们在ScienceQA上实现了接近最先进的性能,同时适应了文本模式和图像文本模式。
这种参数高效的训练方法实际上节省了大部分GPU内存。与LLaVA相比,在完全微调大型模型的情况下,LLaVA-13B将耗尽A100(80G)上的GPU内存。相比之下,LaVIN-13B只需要大约55G的GPU内存开销。考虑到LLaVA也使用梯度检查点,LaVIN-13B至少节省了一半的GPU内存开销(估计),训练速度会更快。与现有的参数效率方法相比,我们的解决方案在性能和适应性方面具有显著优势,有关具体情况,请参阅本文,此处没有详细说明。然而,由于深度速度似乎不支持参数高效的训练方法,实际的GPU内存开销与完全优化的LLAVA相似,甚至略多。
4位量化训练
4位量化训练主要指qlora。简而言之,qlora将LLM的重量量化为4位进行存储,同时在训练过程中将它们量化为16位,以确保训练精度。这种方法显著减少了训练期间的GPU内存开销(训练速度应该不会有太大变化)。这种方法非常适合与参数效率高的方法相结合。然而,原始论文是为单模态LLM设计的,代码已经包装在HuggingFace的库中。因此,我们从HuggingFace的库中提取了核心代码,并将其迁移到LaVIN的代码中。主要原理是将LLM中的所有线性层替换为4位量化层。有兴趣的人可以参考我们在quantization.py和mm_adaptation.py中的实现,这大约是十几行代码。
经过4位量化训练后,当批处理大小(bs)大于1时,GPU内存的减少不是很明显。LaVIN-7B减少了大约4-6G,但这种固定内存减少实际上非常有价值。此时,我们很好奇qlora是如何将模型安装在单个GPU上的,此时LaVIN-7B的GPU内存开销仍然在36+G左右。在检查他们的代码后,我们找到了以下关键设置。
梯度累积+梯度检查点
这里的关键是用时间换取空间。使用1 +梯度累积和梯度检查点的批处理大小(bs)可以大大减少GPU内存开销。这也是qlora训练的核心元素(实际上,仅仅通过量化训练实现极端的内存压缩是相当具有挑战性的)。我们的实验结果大致如下:LaVIN-7B,当从bs=4更改为批处理大小(bs)=1 +梯度累积时,将GPU内存减少到25G左右。应用梯度检查点后,内存减少到9-10G左右。此时,内存从数百GB压缩到10G左右,这是相当可观的。然而,这一步骤的成本是训练速度的显著放缓,这实际上类似于qlora的原始论文中报告的速度下降。与根本无法进行培训的原始情况相比,这些额外的时间成本可以忽略不计。
分页优化器
Paged Optimizer的目的是在GPU内存即将耗尽时将优化器中的一部分权重迁移到CPU,从而确保训练的正常进度。在实际使用中,没有太大的明显区别。我们怀疑,当GPU内存开销非常接近GPU内存容量时,此设置可以提供快速修复。在正常情况下,这似乎没有多大帮助。有兴趣的人可以尝试8位优化器,这可能会带来更明显的好处。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢