
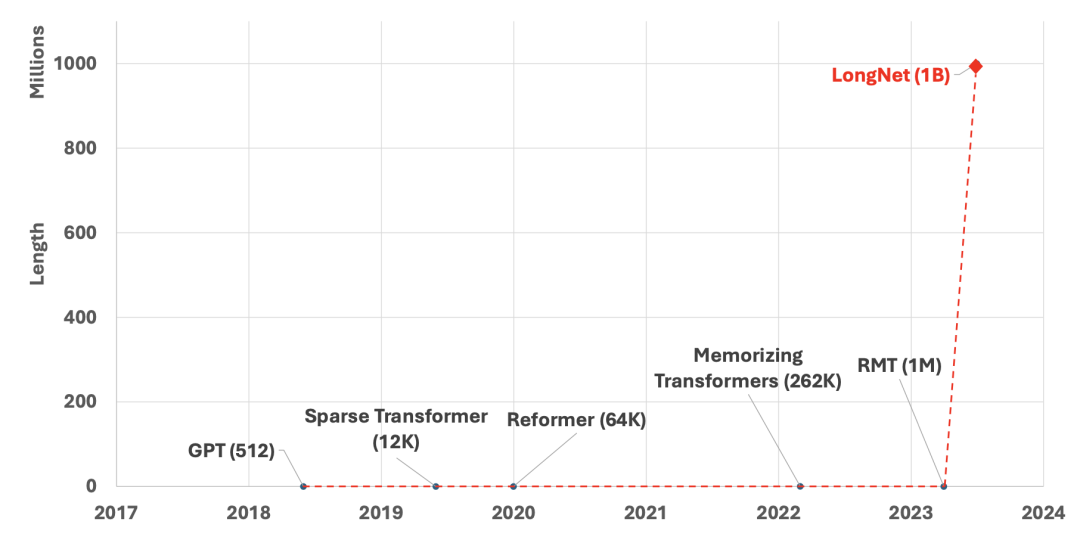
Transformer处理长序列时较为吃力。因为global attention的存在,模型的时间复杂度是序列长度的2次方级。为了建模更长的上下文,人们也提出了各种稀疏注意力机制。而这次,微软卷到家了,提出了LongNet网络,可以将Transformers的上下文范围(几乎)无限扩充,并给出了序列长度达到10亿的实验数据。
论文题目:
LONGNET: Scaling Transformers to 1,000,000,000 Tokens
论文链接:
https://arxiv.org/pdf/2307.02486.pdf
LongNet注意力结构
LongNet网络和标准Transformer差别不大,主要提出了一种名为dilated attention的注意力模式。如下图所示,其实和稀疏注意力模式很像,但借鉴了线段树的思想。整体而言,随着节点相对距离的增加节点之间的交互对数级地较小,以此来实现时间复杂度随输入序列长度线性增加。
例如,如上图所示,结构可以类比一颗以4叉树为基础的线段树。在段长为4,扩展率为1的部分(蓝色),距离为4以内的点直接计算注意力;加上在段长为16,扩展率为4的部分(蓝色+橙色),节点之间最多通过2次注意力机制(绿色+蓝色)。这样算来,BERT-base 12层的网络,允许2^24=16M的上下文进行交互。
多卡分布式计算
对于大规模语言模型等transformers的应用场景,因为模型参数量很大,多卡分布式计算必不可少。而LongNet允许更长的上下文范围,也会带来显存使用量的提升。下图是多卡分布式计算的方式的示意图。以2卡为例,可以将输入序列截断为2部分,2块显卡分别计算注意力机制的Q、K、V向量,与Segment Length比较小的部分的注意力机制(深蓝、浅蓝部分)。然后,汇聚计算结果,计算Segment Length比较大的部分的注意力交互(灰色)。因为Segment Length比较大时,Dilated rate也较大,注意力较为稀疏,因此可以单卡计算。
实验结果
十亿序列长度的时间消耗
下图对比的前馈网络的时间消耗。可以看到,标准transformers随着序列长度增加,时间消耗2次方增长(橙色),而基于Diated attention的网络结构时间消耗随输入序列长度线性增加(蓝色)。
语言模型建模能力
实验基于base-size的MAGNETO[1]结构(12层、12头、768隐层维度)和XPOS[2]相对位置编码。采用Stack数据集[3],一个源代码数据集。采用tiktoken分词器[4],训练了300K个steps,并采用FlashAttention[5]优化方式。
LongNet采用的segment lengths范围为{2048,4096,8192,16384,32768},对应到dilated ratios为{1,2,4,6,12}。
从下面两张图中可以看到,LongNet的PPL分数明显低于标准Transformer。在相同建模序列长度中,LongNet表现均优于Sparse Transformer。相对于标准Transformer而言,LongNet可以用更小的计算量,建模更长的上下文范围,取得更好的表现。
构建大语言模型的潜力
如下图左所示,增加模型参数从1.2亿到27亿,随着LongNet的计算量增加,在测试集上的PPL也随之降低。这体现出,LongNet同样满足scaling law。训练更大的语言模型可能能取得更好的表现。
之前的工作曾指出,大语言模型无法超越监督学习任务,经常是因为上下文建模长度有限,in context learning只能支撑小样本学习。而如下图右所示,在语言模型任务上,以上文作为prompt。随着上下文长度的增加,prompt的长度变长,LongNet在语言模型能够取得更好的表现。说明LongNet的注意力机制能够利用较远的上下文信息,展现未来prompt learning上的潜力。
本文引入了LongNet,可以以较低的成本引入更长的上下文范围。虽然没有直接在大语言模型(LLM)上做尝试,但也展现了令人瞩目的潜力。更长的上下文范围也意味着prompt tuning可能将迎来全监督学习年代。具体未来会如何呢?让我们拭目以待。
https://github.com/openai/tiktoken
https://github.com/HazyResearch/flash-attention/tree/main
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢