

Mixture-of-Experts Meets Instruction Tuning:A Winning Combination for Large Language Models
S Shen, L Hou, Y Zhou, N Du, S Longpre, J Wei, H W Chung, B Zoph...
[Google & UC Berkeley & MIT]
混合专家与指导微调相结合的大型语言模型
-
动机:随着大型语言模型(LLM)的规模和计算需求的快速增长,训练效率、内存占用和部署成本等方面的挑战也随之增加。因此,开发可扩展的技术,以在不产生过高计算开销的情况下利用这些模型的能力,成为了迫切的需求。 -
方法:提出一种结合稀疏混合专家(MoE)和指令微调的方法。MoE模型基于语言模型可以被分解为专注于输入数据不同方面的较小、专门化的子模型(即"专家")的观察,从而实现更有效的计算和资源分配。指令微调是一种训练LLM遵循指令的技术。 -
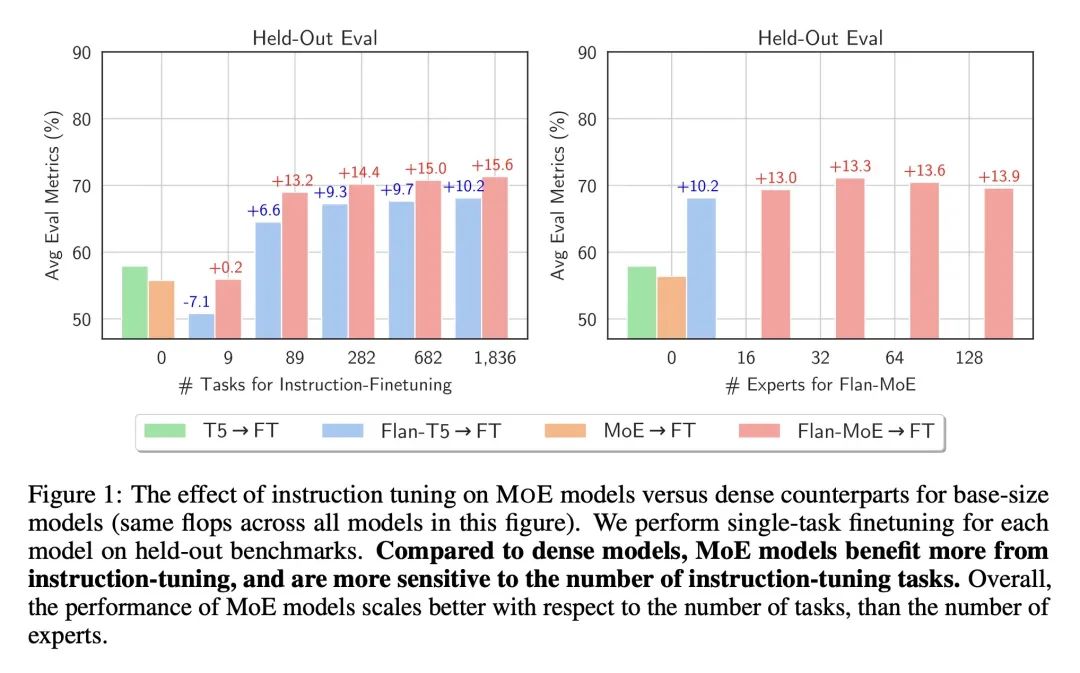
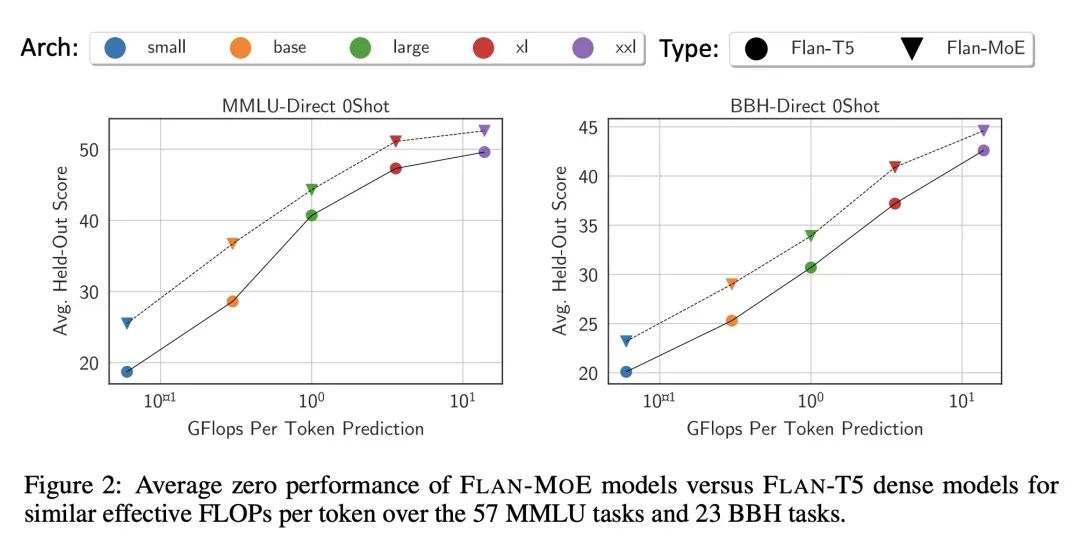
优势:与稠密模型相比,MoE模型从指令微调中获益更多。特别是,在三种实验设置中进行了实证研究,发现在引入指令微调(独立使用或与任务特定微调结合使用)后,MoE模型的性能显著提高。
通过结合稀疏混合专家(MoE)和指令微调,本文提出了一种有效提升大型语言模型(LLM)性能的方法,尤其是在引入指令微调后,MoE模型的性能显著提高。
https://arxiv.org/abs/2305.14705
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢