

【论文速读】是OpenBMB发起的大模型论文学习栏目,用 高效的思维导图 形式,带领大家在 10min 内快速掌握一篇 前沿经典 论文。我们邀请来自清华大学自然语言处理实验室以及各大高校、科研机构的 学术达人 作为主讲人分享 大模型领域论文。
本期论文速读带大家回顾首个交互式搜索中文问答开源模型——WebCPM: Interactive Web Search for Chinese Long-form Question Answering (ACL 2023),由论文作者之一、面壁智能实习生严澜进行领读。
01 作者信息
-
Yujia Qin, Zihan Cai, Dian Jin, Lan Yan, Shihao Liang, Kunlun Zhu, Yankai Lin, Xu Han, Ning Ding, Huadong Wang, Ruobing Xie, Fanchao Qi, Zhiyuan Liu, Maosong Sun, Jie Zhou
-
论文作者均来自THUNLP实验室
02 论文简介
01 长篇问答(Long-formQA)
-
目标:以详细的、段落长度的回应回答的开放式问题
-
范式:信息检索和信息合成
-
传统范式的缺点:常依赖非交互式的检索方法
02 人类的交互式网页搜索(Interactive Web Search)
-
功能:实时与搜索引擎互动
-
方法:分解复杂问题,顺序提问,通过相关信息提高主题理解,提出后续问题优化搜索
-
WebGPT 构建了一个由 Bing 支持的 Web 搜索界面,然后招募标注员收集信息以回答问题。之后,他们对 GPT-3 进行微调,以模仿人类在 Web 搜索和信息综合方面的行为
-
缺点:界面、数据集和训练模型不公开
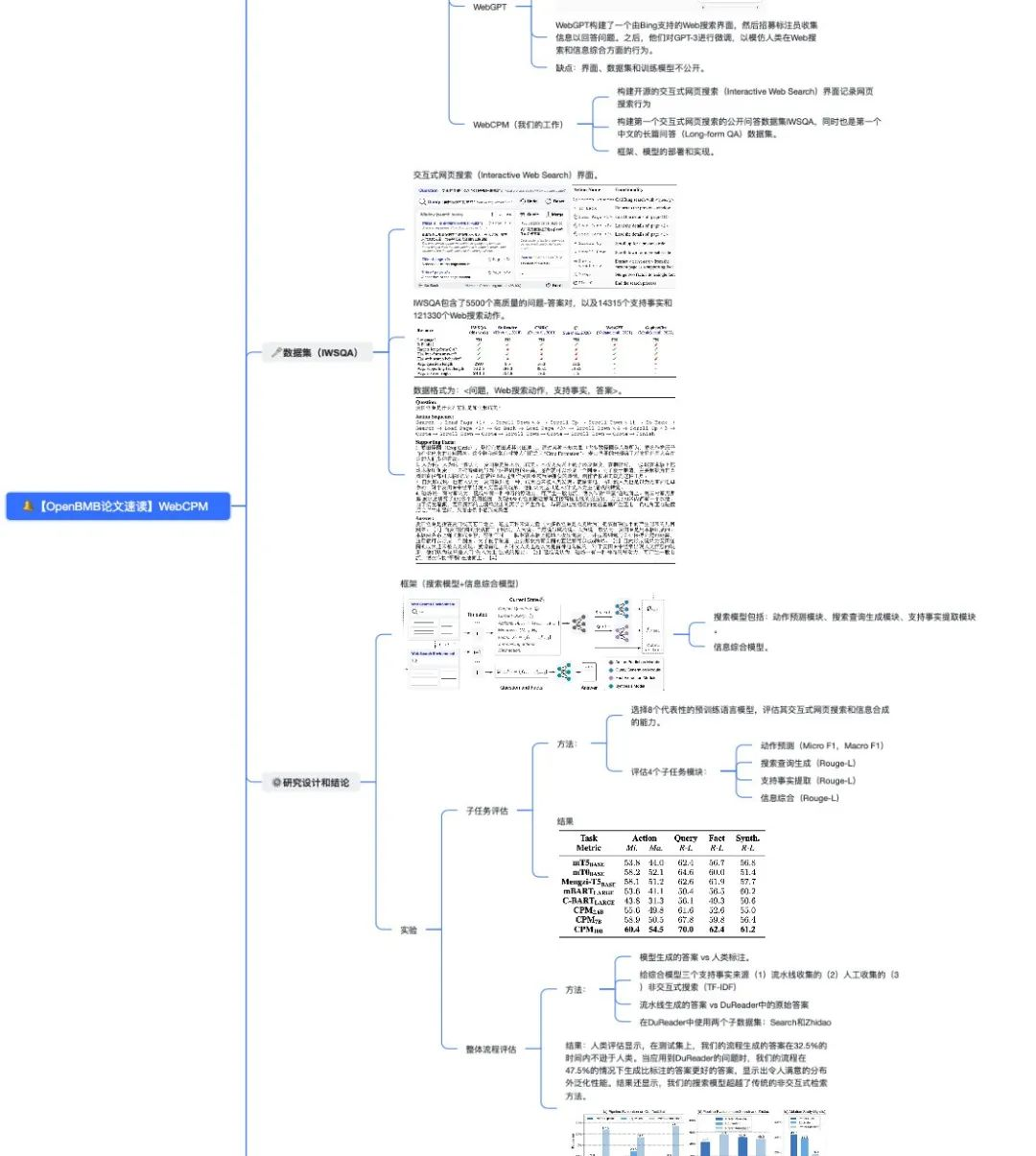
04 WebCPM(我们的工作)
-
构建 开源的 交互式网页搜索 (Interactive Web Search) 界面记录网页搜索行为
-
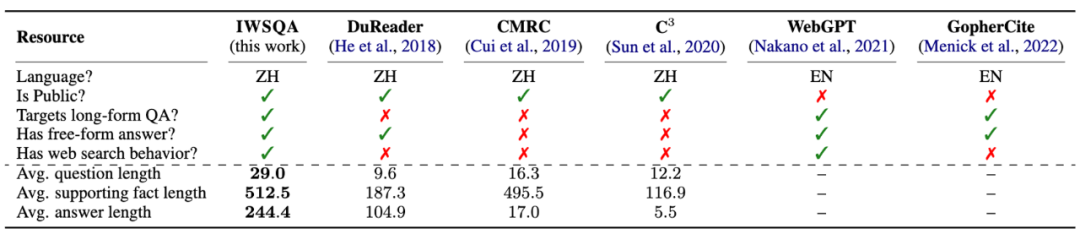
构建 第一个 交互式网页搜索的公开问答数据集 IWSQA,同时也是 第一个 中文的长篇问答 (Long-formQA) 数据集
-
框架、模型的部署和实现
03 数据集(IWSQA)
👇 交互式网页搜索(Interactive Web Search)界面
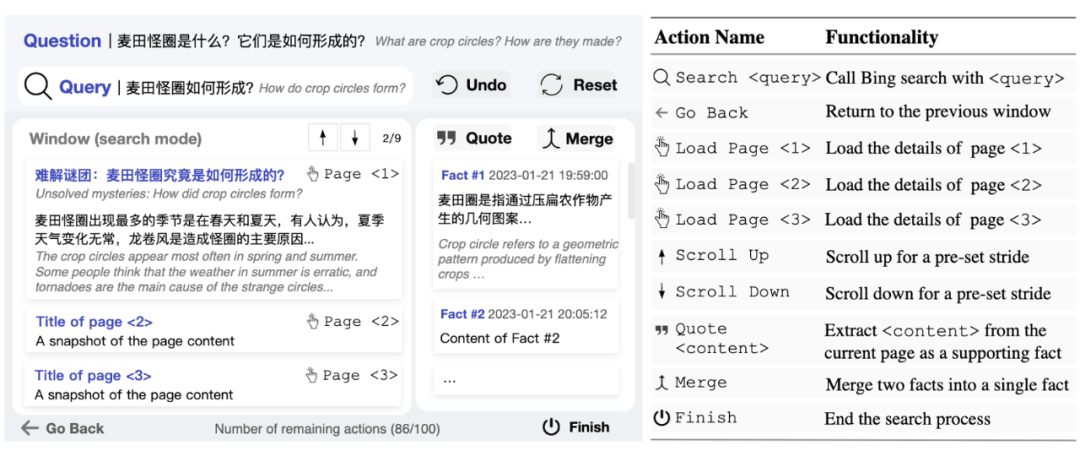
IWSQA 包含了 5500 个高质量的问题-答案对,以及 14315 个支持事实和 121330 个 Web 搜索动作。
数据格式为:<问题,Web搜索动作,支持事实,答案>。

04 研究设计和结论
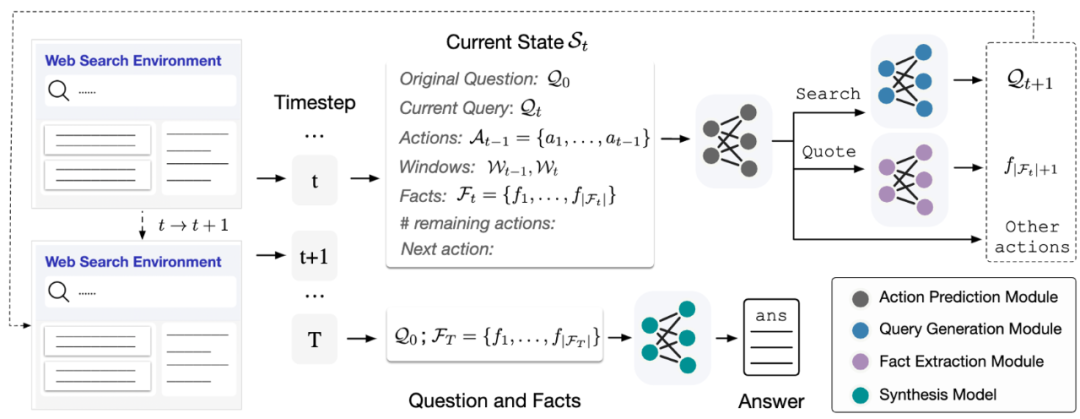
实验及结果
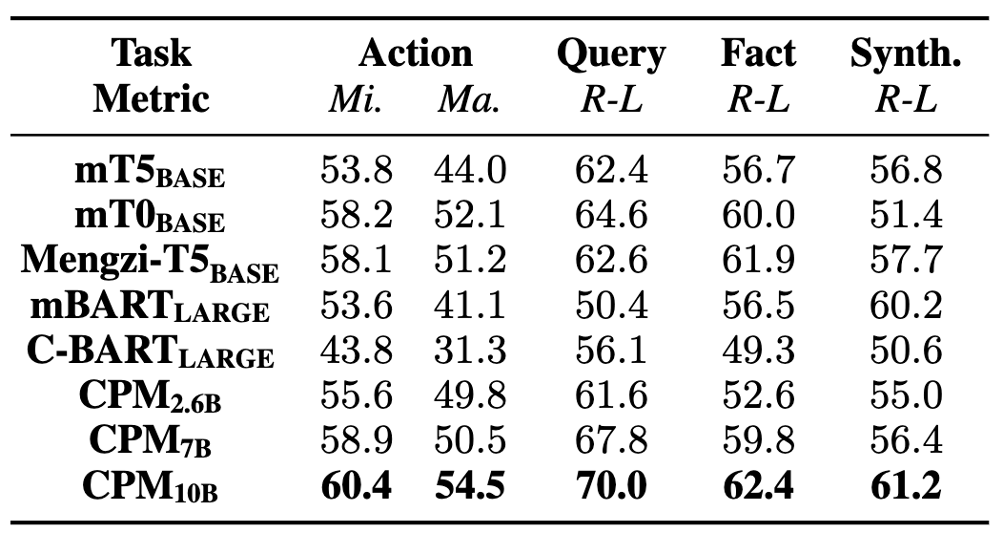
A. 子任务评估
方法:
-
选择 8 个代表性的预训练语言模型,评估其交互式网页搜索和信息合成的能力
-
评估 4 个子任务模块
-
动作预测 (MicroF1,MacroF1)
-
搜索查询生成 (Rouge-L)
-
支持事实提取 (Rouge-L)
-
信息综合 (Rouge-L)
B. 整体流程评估
方法:
-
模型生成的答案 vs 人类标注
-
给综合模型三个支持事实来源(1)流水线收集的(2)人工收集的(3)非交互式搜索(TF-IDF)
-
流水线生成的答案 vs DuReader中的原始答案
-
在DuReader中使用两个子数据集:Search和Zhidao
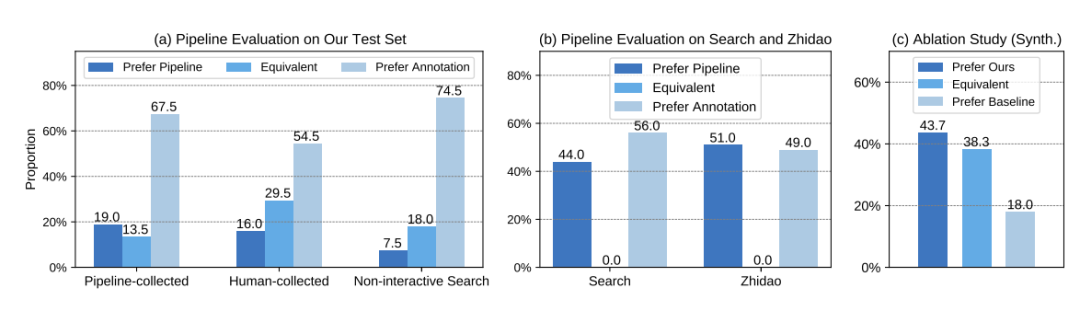
人类评估显示,在测试集上,我们的流程生成的答案在 32.5% 的时间内不逊于人类。当应用到 DuReader 的问题时,我们的流程在 47.5% 的情况下生成比标注的答案更好的答案,显示出令人满意的分布外泛化性能。结果还显示,我们的搜索模型超越了传统的非交互式检索方法。
05 论文贡献
在本论文中,我们为中文长文本问答构建了一个交互式网页搜索基准,并提供了开源的界面。我们将长文本问答任务分解为 4 个子任务,并设计了一套模块化的流程。各个模块中,对代表性 LLM 进行微调,对每个模块和整个流程进行了评估。
我们的流程生成的答案在 32.5% 的时间内不逊于人类;当应用到 DuReader 的问题时,我们的流程在 47.5% 的情况下生成比标注的答案更好的答案,显示出令人满意的分布外泛化性能。
🔗 https://arxiv.org/abs/2305.06849
我们为读者准备了一份高清思维导图,包括了论文中的重点亮点以及直观的示意图。点击下方名片 关注 OpenBMB ,后台发送“论文速读” ,即可领取论文学习高清思维导图和 FreeMind !
本期论文速读视频版已发布于 视频号 和 B站 (视频讲解比文字阅读更加详细易懂),欢迎大家评论和分享~
➤ 加社群/ 提建议/ 有疑问


长期开放招聘|含实习
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢