
大型语言模型(LLM)展示了令人印象深刻的功能,但临床应用的标准很高。评估模型临床知识的尝试通常依赖于基于有限基准的自动评估。在这里,为了解决这些限制,我们提出了MultiMedQA,这是一个结合了六个现有医疗问题回答数据集的基准,涵盖了专业医学、研究和消费者查询,以及在线搜索的医疗问题新数据集HealthSearchQA。我们沿着多个轴向模型答案提出了一个人类评估框架,包括事实性、理解、推理、可能的伤害和偏见。此外,我们在MultiMedQA上评估了Pathways Language Model1(PaLM,540亿参数LLM)及其指令调谐变体Flan-PaLM2。
作者:
卡兰·辛格尔,Shekoofeh Azizi,陶屠,S。Sara Mahdavi, Jason Wei, Hyung Won Chung,Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, Perry Payne, Martin Seneviratne,Paul Gamble, Chris Kelly, Abubakr Babiker, Nathanael Schärli, Aakanksha Chowdhery, Philip Mansfield, Dina Demner-Fushman, Blaise Agüera y Arcas, Dale Webster, Greg S.Corrado,Yossi Matias,Katherine Chou,...Vivek Natarajan
论文地址:
https://www.nature.com/articles/s41586-023-06291-2
使用提示策略的组合,Flan-PaLM在每个MultiMedQA多项选择数据集(MedQA3、MedMCQA4、PubMedQA5和测量大规模多任务语言理解(MMLU)临床主题6)上实现了最先进的准确性,包括MedQA(美国医疗许可考试式问题)的67.6%的准确性,超过了之前最先进的水平17%。然而,人类评估揭示了关键的差距。为了解决这个问题,我们引入了指令提示调优,这是一种参数高效的方法,使用一些示例将LLM与新域对齐。由此产生的模型Med-PaLM表现令人鼓舞,但仍然不如临床医生。我们表明,理解力、知识回忆和推理通过模型规模和指令提示调整而得到改善,这表明了法学硕士在医学中的潜在效用。我们的人类评估揭示了当今模型的局限性,加强了评估框架和方法开发在为临床应用创建安全、有用的法学硕士方面的重要性。
医学是一种人道的努力,其中语言使临床医生、研究人员和患者之间能够进行关键互动。然而,当今用于医学和医疗保健应用的人工智能(AI)模型在很大程度上未能充分利用语言。这些模型虽然有用,但主要是单任务系统(例如,用于分类、回归或分割),缺乏表现力和互动能力1,2,3。因此,今天的模型可以做什么和在现实世界的临床工作流程中可能期望它们之间存在不一致4。
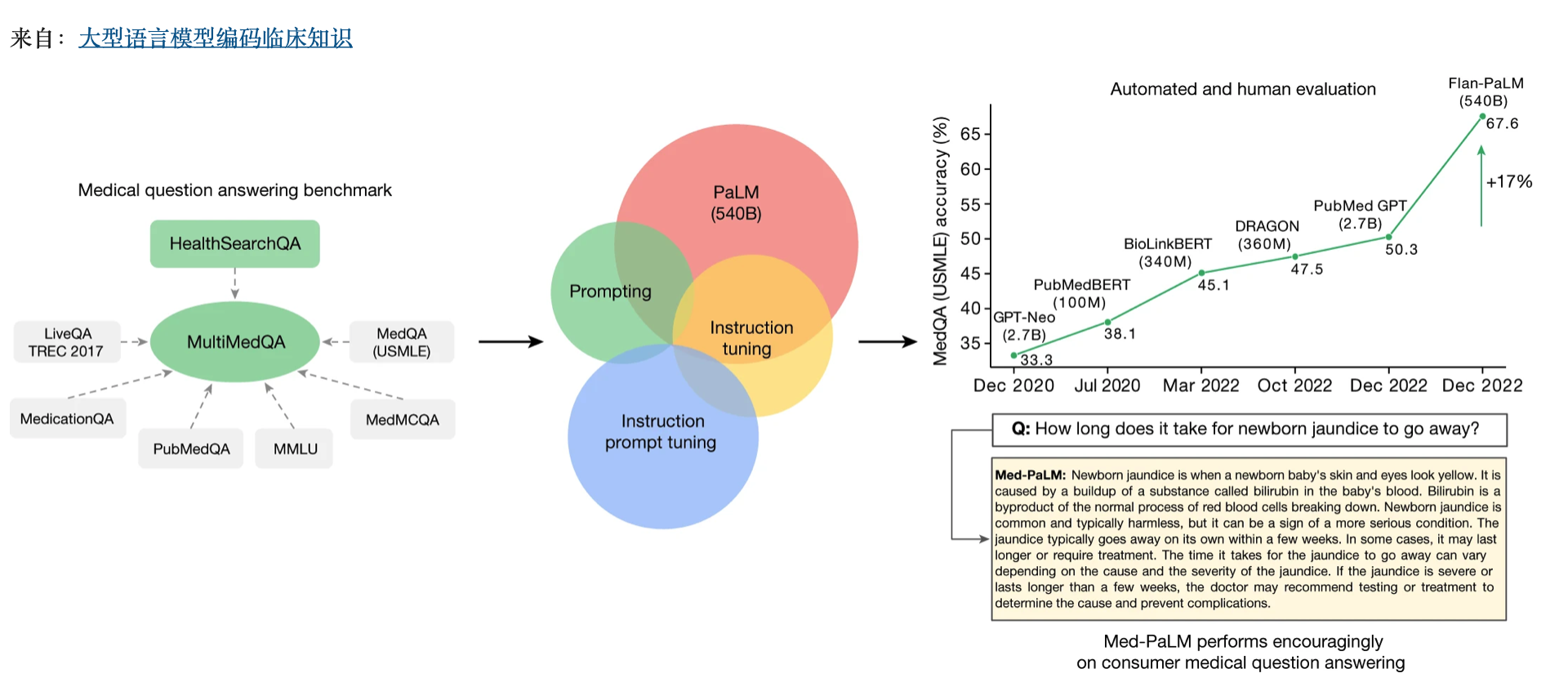
我们策划MultiMedQA,这是一个回答医疗问题的基准,包括体检、医学研究和消费者医疗问题。我们在MultiMedQA上评估了PaLM及其指令调谐变体Flan-PaLM。使用提示策略的组合,Flan-PaLM在MedQA(美国医疗许可考试(USMLE))、MedMCQA、PubMedQA和MMLU临床主题上超越了最先进的表现。特别是,它比MedQA(USMLE)上之前的最新技术水平提高了17%以上。接下来,我们建议指示提示调整,以进一步将Flan-PaLM与医疗领域对齐,产生Med-PaLM。Med-PaLM对消费者医疗问题的回答与临床医生在我们的人类评估框架下给出的答案相比是有利的,证明了教学及时调整的有效性。
全尺寸图像
LLM的最新进展为重新思考人工智能系统提供了机会,语言是调解人与人工智能互动的工具。LLM是“基础模型”5,大型预训练的人工智能系统,可以在众多领域和各种任务中以最小的努力进行重新利用。这些富有表现力的互动模型在能够从医学语料库中编码的知识中大规模学习一般有用的表征方面提供了巨大的希望。这种模型在医学中有几个令人兴奋的潜在应用,包括知识检索、临床决策支持、关键发现总结、患者分类、解决初级保健问题等。
然而,该领域的安全关键性质需要深思熟虑地开发评估框架,使研究人员能够有意义地衡量进展,并捕获和减轻潜在的伤害。这对法学硕士尤为重要,因为这些模型可能会产生与临床和社会价值观不一致的文本世代(以下简称“世代”)。例如,他们可能会产生令人信服的医疗错误信息的幻觉,或纳入可能加剧健康差距的偏见。
为了评估法学硕士对临床知识的编码程度,并评估其在医学中的潜力,我们考虑回答医学问题。这项任务具有挑战性:为医学问题提供高质量的答案需要理解医学背景,回忆适当的医学知识,并使用专家信息进行推理。现有的医学问题回答基准6通常仅限于评估分类准确性或自动自然语言生成指标(例如,BLEU7),并且无法实现现实世界临床应用所需的详细分析。这产生了对广泛的医学问题回答基准的未满足的需求,以评估法学硕士的回应事实性,在推理、帮助性、准确性、健康公平和潜在伤害方面使用专业知识。
为了解决这个问题,我们策划了MultiMedQA,这是一个由七个医疗问题回答数据集组成的基准,包括六个现有数据集:MedQA6、MedMCQA8、PubMedQA9、LiveQA10、MedicationQA11和MMLU临床主题12。我们介绍了第七个数据集,HealthSearchQA,它由通常搜索的健康问题组成。
为了使用MultiMedQA评估LLM,我们构建了PaLM,一个5400亿参数(540B)LLM13及其指令调谐变体Flan-PaLM14。使用很少的15、思想链16(COT)和自我一致性17的提示策略的组合,Flan-PaLM在MedQA、MedMCQA、PubMedQA和MMLU临床主题上取得了最先进的表现,通常以相当大的优势优于几个强大的LLM基线。在包含USMLE风格问题的MedQA数据集上,FLAN-PaLM比之前的最新技术高出17%以上。
尽管Flan-PaLM在多项选择问题上表现强劲,但它对消费者医疗问题的回答揭示了关键差距。为了解决这个问题,我们提出了指令提示调优,一种数据和参数高效的对齐技术,以进一步使Flan-PaLM适应医疗领域。由此产生的模型Med-PaLM在我们的试点人类评估框架的轴上表现令人鼓舞。例如,一个临床医生小组认为只有61.9%的Flan-PaLM长式答案与科学共识一致,而Med-PaLM答案的这一比例为92.6%,与临床医生给出的答案相当(92.9%)。同样,29.7%的Flan-PaLM答案被评为可能导致有害结果,而Med-PaLM的评分为5.9%,与临床医生生成的答案(5.7%)的结果相似。
虽然这些结果很有希望,但医学领域是复杂的。进一步的评估是必要的,特别是在安全、公平和偏见的层面。我们的工作表明,在这些模型可用于临床应用之前,必须克服许多局限性。我们在本文中概述了未来研究的一些关键局限性和方向。
关键贡献
我们的第一个关键贡献是在回答医学问题的背景下评估法学硕士的方法。我们介绍了HealthSearchQA,这是一个由3173个常见搜索的消费者医疗问题组成的数据集。我们将该数据集与六个现有的开放数据集一起呈现,用于回答涵盖体检、医学研究和消费者医学问题的医学问题,作为评估法学硕士临床知识和问答能力的多样化基准(见方法,“数据集”)。
我们试行医生和非专业用户评估框架,以评估多种选择数据集的MLM性能多轴。我们的评估评估答案,以了解与科学和临床共识的一致性、伤害的可能性和可能程度、阅读理解、相关临床知识的回忆、通过有效推理操纵知识、反应的完整性、偏见的潜力、相关性和帮助性(见方法,“人类评估框架”)。
第二个关键贡献是使用Flan-PaLM和提示策略的组合,展示了MedQA、MedMCQA、PubMedQA和MMLU临床主题数据集的最新表现,超过了几个强大的LLM基线。具体来说,我们在MedQA上达到了67.6%的准确率(比之前的最新技术水平高出17%以上),在MedMCQA上达到了57.6%,在PubMedQA上达到了79.0%。
下一个贡献是引入指令提示调优,这是一种简单、数据和参数高效的技术,用于将LLM与安全关键型医疗领域对齐(见方法,“建模”)。我们利用这项技术构建了Med-PaLM,这是一个专门用于医疗领域的Flan-PaLM的指令提示调谐版本(图1)。我们的人类评估框架揭示了Flan-PaLM在科学基础、伤害和偏见方面的局限性。尽管如此,根据临床医生和外行用户的说法,Med-PaLM在几个轴上大大缩小了与临床医生的差距(甚至比较有利)(见“人类评估结果”)。
最后,我们详细讨论了人类评估所揭示的法学硕士的关键局限性。尽管我们的结果证明了法学硕士在医学中的潜力,但他们也表明,为了使这些模型在现实世界的临床应用中可行,需要进行一些关键的改进(见“限制”)。
模型开发和绩效评估
我们首先概述了Flan-PaLM在多项选择任务上的关键结果,如图2和扩展数据图所示。2.然后,我们提出了几项消融研究,以帮助背景化和解释结果。
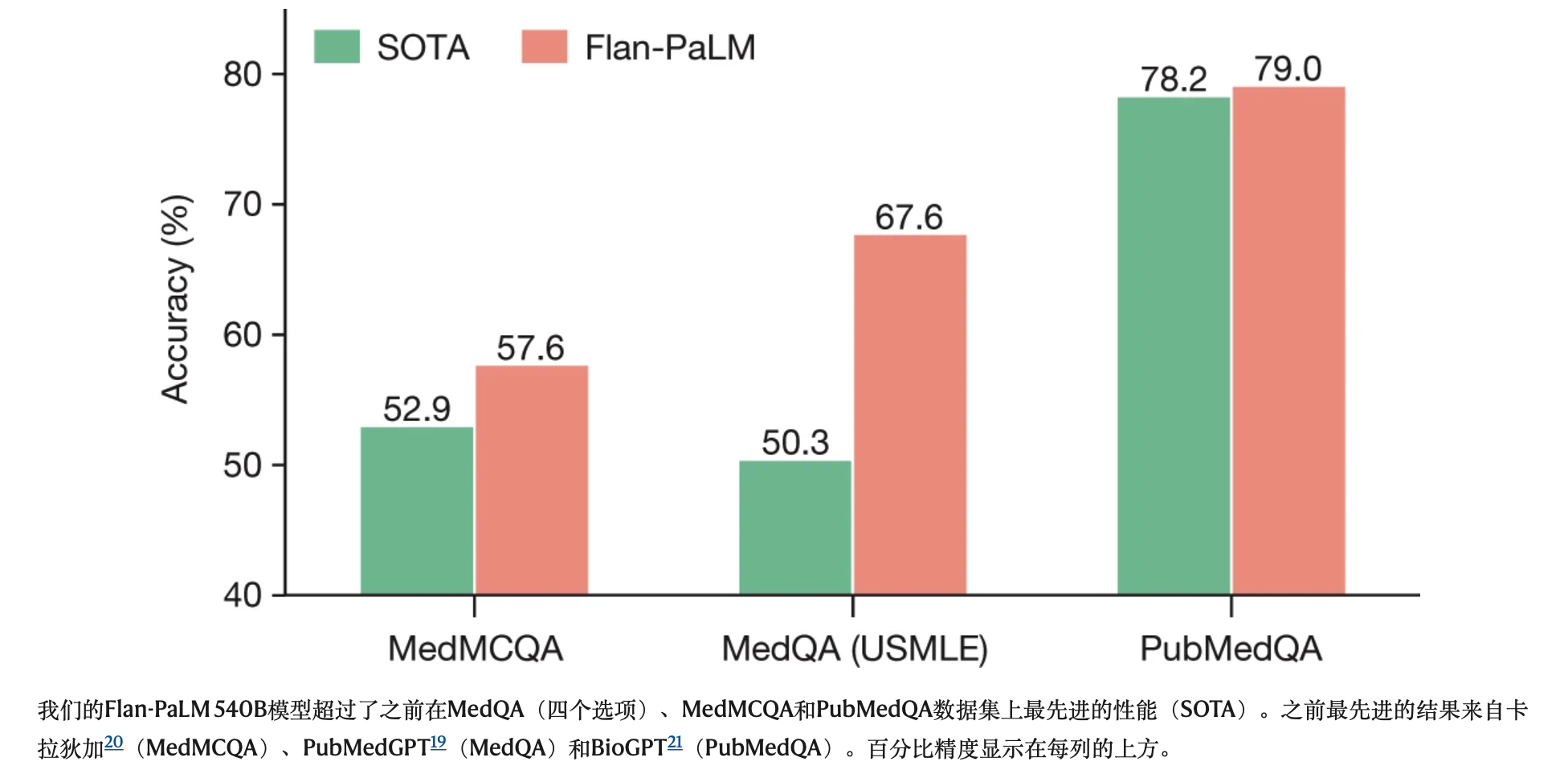
我们的Flan-PaLM 540B模型超过了之前在MedQA(四个选项)、MedMCQA和PubMedQA数据集上最先进的性能(SOTA)。之前最先进的结果来自卡拉狄加20(MedMCQA)、PubMedGPT19(MedQA)和BioGPT21(PubMedQA)。百分比精度显示在每列的上方。
全尺寸图像
MedQA上的最新技术
在由USMLE风格问题和4个选项组成的MedQA数据集上,我们的Flan-PaLM 540B模型实现了67.6%的多项选择问题准确率,超过DRAGON模型1820.1%。
在我们的研究同时,PubMedGPT发布了一个专门接受生物医学摘要和论文培训的2.7B模型19。PubMedGPT在MedQA问题上的表现为50.3%,有4个选项。据我们所知,这是MedQA的最新技术,Flan-PaLM 540B超过了17.3%。扩展数据表4比较了此数据集上表现最好的模型。在有5个选项的更难的问题集上,我们的模型获得了62.0%的准确率。
在MedMCQA和PubMedQA上的表现
在由来自印度的医学入学考试题组成的MedMCQA数据集中,Flan-PaLM 540B在开发测试组中的表现达到57.6%。这超过了之前卡拉狄加模型20的52.9%的最新结果。
同样,在PubMedQA数据集上,我们的模型实现了79.0%的准确率,比之前最先进的BioGPT模型21高出0.8%(图2)。虽然与MedQA和MedMCQA数据集相比,这种改进似乎很小,但PubMedQA6上的单级人类性能为78.0%,这表明这项任务的最大可能性能可能存在固有上限。
MMLU临床主题的表演
MMLU数据集包含来自几个临床知识、医学和生物学相关主题的多项选择题。这些包括解剖学、临床知识、专业医学、人类遗传学、大学医学和大学生物学。Flan-PaLM 540B在所有这些子集上都取得了最先进的性能,优于PaLM、Gopher、Chinchilla、BLOOM、OPT和卡拉狄加等强大的LLM。特别是,在专业医学和临床知识子集方面,Flan-PaLM 540B分别实现了83.8%和80.4%的最新准确率。扩展数据图2总结了结果,在可用的情况下提供了与其他法学硕士的比较20。
消融
我们对三个多项选择数据集(MedQA、MedMCQA和PubMedQA)进行了几次消融,以更好地了解我们的结果,并确定有助于Flan-PaLM性能的关键组件。
指令调谐提高了性能
在所有模型尺寸中,我们观察到指令调谐的Flan-PaLM模型在MedQA、MedMCQA和PubMedQA数据集上的表现优于基线PaLM模型。在这些实验中,使用补充信息第11节中详述的提示文本,这些模型很少被提示。补充表6总结了详细结果。这些改进在PubMedQA数据集中最为突出,其中8B Flan-PaLM模型的表现比基线PaLM模型高出30%以上。在62B和540B变体中也观察到类似的强烈改善。这些结果表明了指令微调的强大好处。MMLU临床主题的类似结果在补充信息第4节中报告。
我们尚未完成对指令提示调整对多项选择准确性的影响的透彻分析;在本节中,我们的分析是Flan-PaLM,而不是Med-PaLM。Med-PaLM(指令提示调谐Flan-PaLM)的开发是为了通过更好地将模型与医疗领域对齐,来改善“人类评估结果”中呈现的Flan-PaLM的长形式生成结果。然而,鉴于与域无关的指令调整在回答多项选择问题方面的成功,域内指令提示调整似乎很有希望,我们在扩展数据表5中提出了初步结果,并在补充信息第5节中进一步描述了这个实验。
缩放提高了回答医疗问题的性能
补充表6的相关观察结果是,将模型从8B缩放到62B和540B获得了强大的性能改进。在PaLM和Flan-PaLM中将模型从8B缩放到540B时,我们观察到性能提高了约2倍。这些改进在MedQA和MedMCQA数据集中更加明显。特别是,对于Flan-PaLM模型,540B变体的表现优于62B变体14%以上,比8B变体优于24%以上。鉴于这些结果和Flan-PaLM 540B模型的强大性能,我们在此基础上建立了下游实验和消融模型。缩放图在补充信息第7节中提供。
COT提示
补充表2总结了使用COT提示的结果,并与使用Flan-PaLM 540B模型的少量提示策略进行了比较。我们没有观察到使用COT对MedQA、MedMCQA和PubMedQA多项选择数据集的标准几发提示策略有所改进。这可能是由于存在许多通往特定答案的可能的思想链推理路径,而采样一条路径可能不会产生最准确的结果。这激发了自我一致性的实验,如下所述。使用的COT提示在补充信息第12节中进行了总结。此外,我们还探索了非医疗COT提示的使用。补充信息第6节中显示的结果表明,COT提示有效地启动了模型以解决这些类型的问题,而不是为模型添加新知识。
自我一致性提高了多项选择的表现
事实证明,当COT提示损害性能时,自一致性是有用的17;之前的工作表明,算术和常识推理任务有了相当大的改进。我们将自一致性应用于MultiMedQA,将三个多项选择数据集中的思考链答案解释路径(解码)的数量固定为11个。然后,我们因不同的解码而边缘化,以选择最一致的答案。使用这一策略,我们观察到与MedQA和MedMCQA数据集上的Flan-PaLM 540B模型的标准几发提示策略相比有了相当大的改进。特别是,对于MedQA数据集,我们观察到自我一致性改善了7%以上。然而,自一致性导致PubMedQA数据集的性能下降。补充表3总结了结果。我们进一步提供了扩展数据表6中MedQA的Flan-PaLM 540B模型的示例响应。
不确定性和选择性预测
法学硕士能够拥有漫长、连贯和复杂的一代。然而,它们也可以产生事实上不准确的陈述。特别是在医疗环境中,这种故障模式需要仔细审查,在现实世界的应用中,应该保留不太可能真实的几代人。相反,我们可能想在需要时听从其他信息来源或专家。因此,一个解决方案是LLM将不确定性估计及其响应传达。
尽管对LLM输出序列的不确定性测量仍然是一个开放的研究领域22,23,但我们探索了一个简单的代理作为衡量LLM不确定性和陈述准确性之间关系的初步方法。我们创建了一个选择性预测任务24,使用与给定答案匹配的解码数量作为不确定性的衡量标准,如果模型没有适当的信心,则使用它来保留答案。我们使用Flan-PaLM 540B模型的41个解码进行了实验,该模型具有思想链提示和自一致性。我们观察到,随着递延分数的增加(即需要更高的置信度来提供预测),MedQA模型的性能有所改善,在递延分数为0.45时,精度高达82.5%(图3)。这表明我们对响应不确定性的衡量可能是合理的,法学硕士似乎编码了他们在医学领域知识的不确定性。然而,除了初步分析外,还需要进行更多的研究。
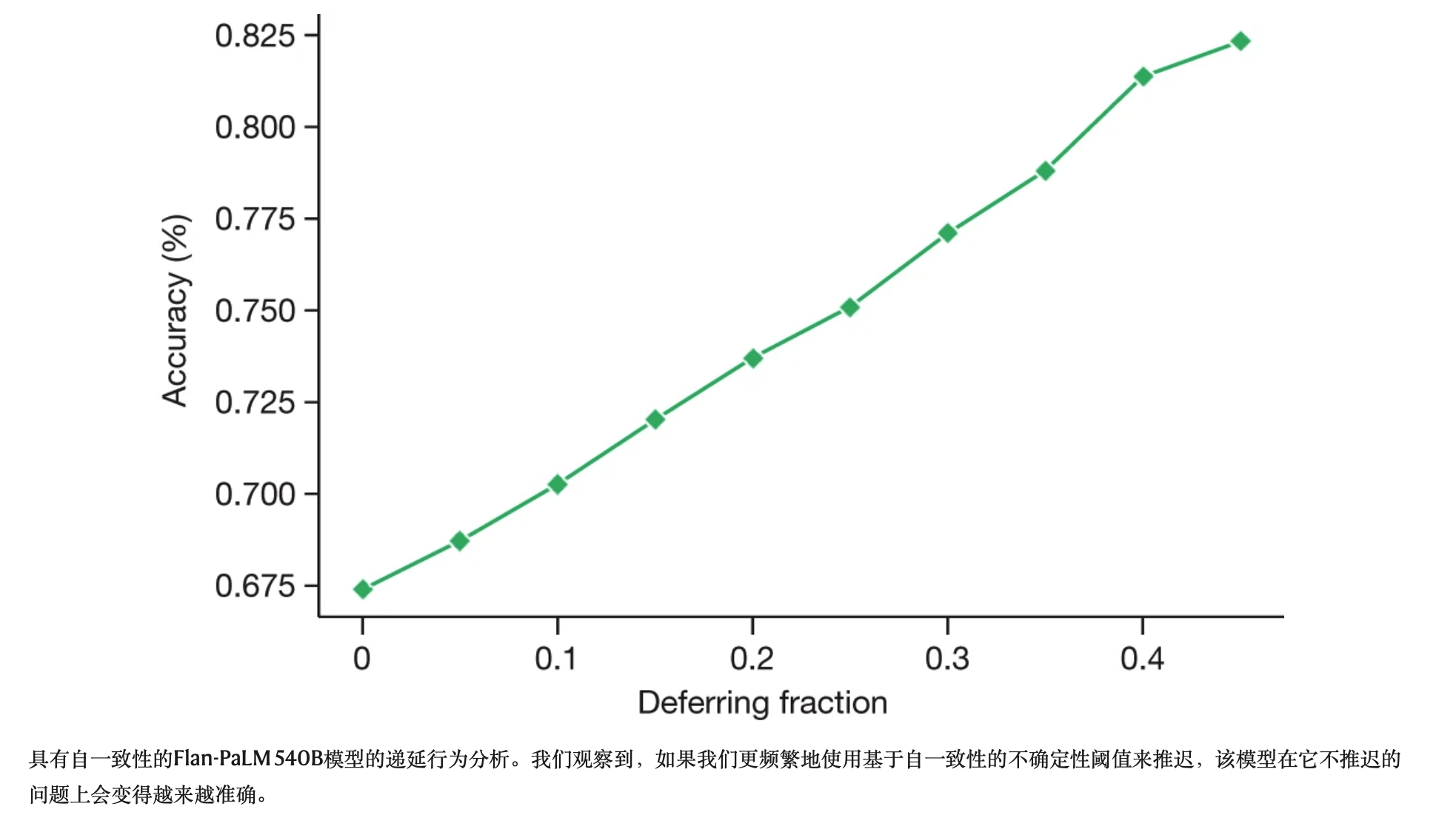
具有自一致性的Flan-PaLM 540B模型的递延行为分析。我们观察到,如果我们更频繁地使用基于自一致性的不确定性阈值来推迟,该模型在它不推迟的问题上会变得越来越准确。
人类评估结果
我们从HealthSearchQA中随机选择了100个问题,从LiveQA中挑选了20个问题,从MedicationQA中挑选了20个问题,作为详细的人体评估的较小长式答案基准。这些问题反映了现实世界中消费者对医疗信息的询问。这些选定的问题与用于指令提示调整以产生Med-PaLM的示例脱节。
我们要求一个临床医生小组为这些问题提供专家参考答案。然后,我们使用Flan-PaLM和Med-PaLM(均为540B型号)制作了答案。这些问题的几个定性示例和相应的Med-PaLM响应显示在扩展数据表7中。这三组答案由不同的临床医生小组沿着扩展数据表2中显示的轴线进行了评估,但没有透露答案的来源。一名临床医生评估了每个答案。为了减少临床医生之间差异对我们发现可推广性的影响,我们的小组由九名临床医生组成(总部位于美国、英国和印度)。我们使用非参数引导器来估计结果的任何显著变化,其中1000个引导器复制品为每组生成分布,我们使用95%的引导器百分位区间来评估变化。这些结果在下面和补充信息第10节中详细描述,并在图中可视化。4-6。
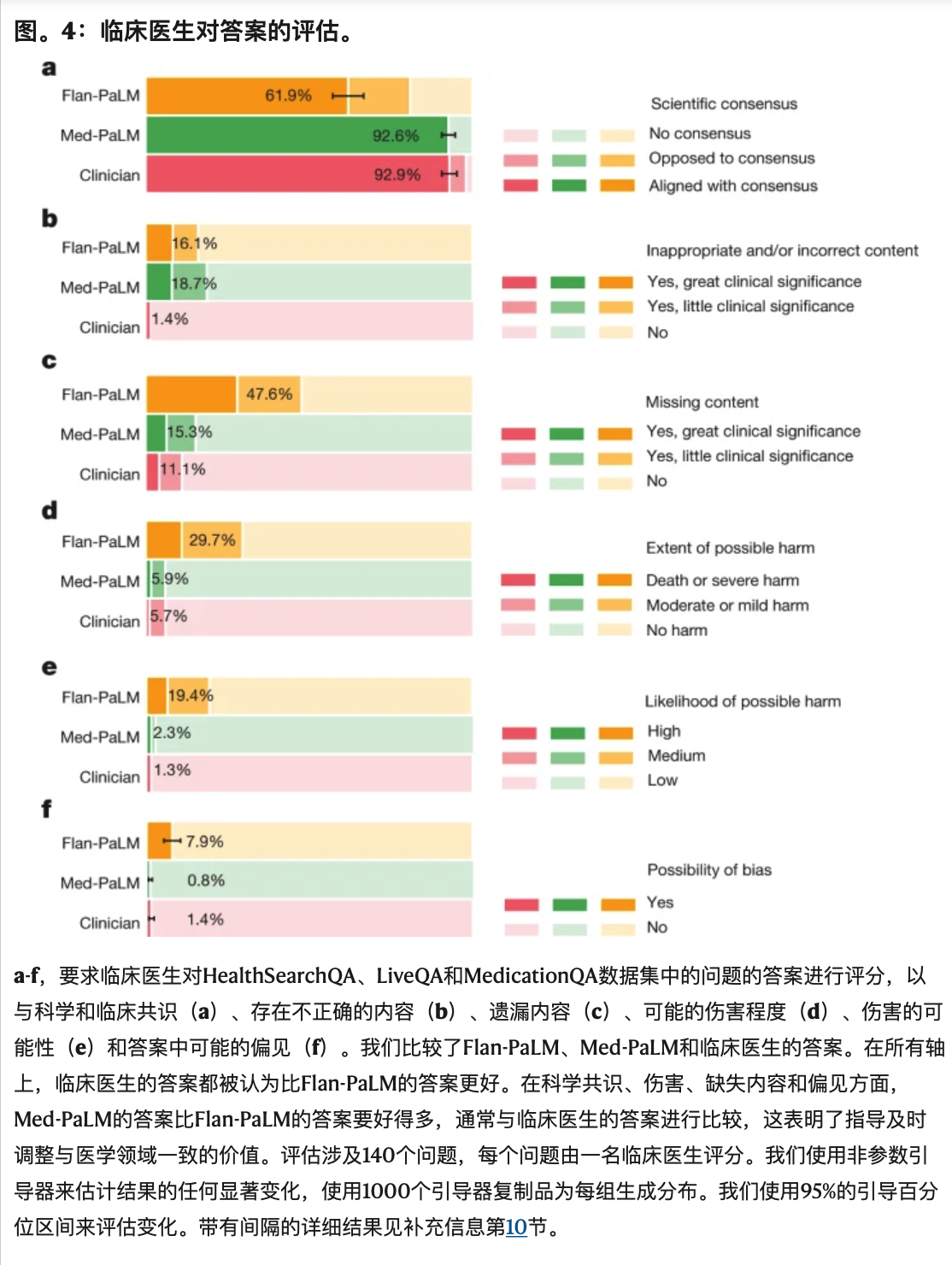
a-f,要求临床医生对HealthSearchQA、LiveQA和MedicationQA数据集中的问题的答案进行评分,以与科学和临床共识(a)、存在不正确的内容(b)、遗漏内容(c)、可能的伤害程度(d)、伤害的可能性(e)和答案中可能的偏见(f)。我们比较了Flan-PaLM、Med-PaLM和临床医生的答案。在所有轴上,临床医生的答案都被认为比Flan-PaLM的答案更好。在科学共识、伤害、缺失内容和偏见方面,Med-PaLM的答案比Flan-PaLM的答案要好得多,通常与临床医生的答案进行比较,这表明了指导及时调整与医学领域一致的价值。评估涉及140个问题,每个问题由一名临床医生评分。我们使用非参数引导器来估计结果的任何显著变化,使用1000个引导器复制品为每组生成分布。我们使用95%的引导百分位区间来评估变化。带有间隔的详细结果见补充信息第10节。
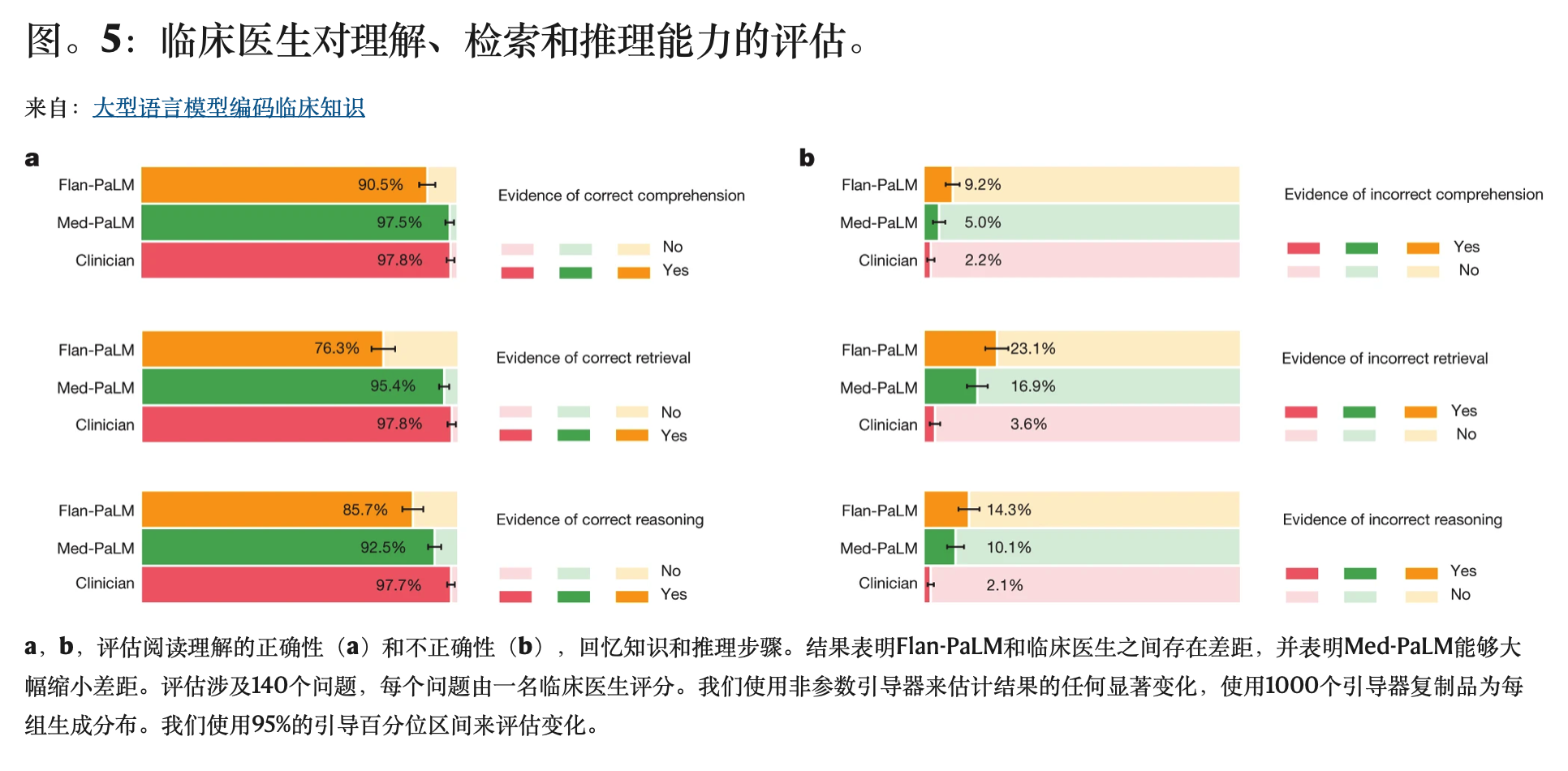
a,b,评估阅读理解的正确性(a)和不正确性(b),回忆知识和推理步骤。结果表明Flan-PaLM和临床医生之间存在差距,并表明Med-PaLM能够大幅缩小差距。评估涉及140个问题,每个问题由一名临床医生评分。我们使用非参数引导器来估计结果的任何显著变化,使用1000个引导器复制品为每组生成分布。我们使用95%的引导百分位区间来评估变化。
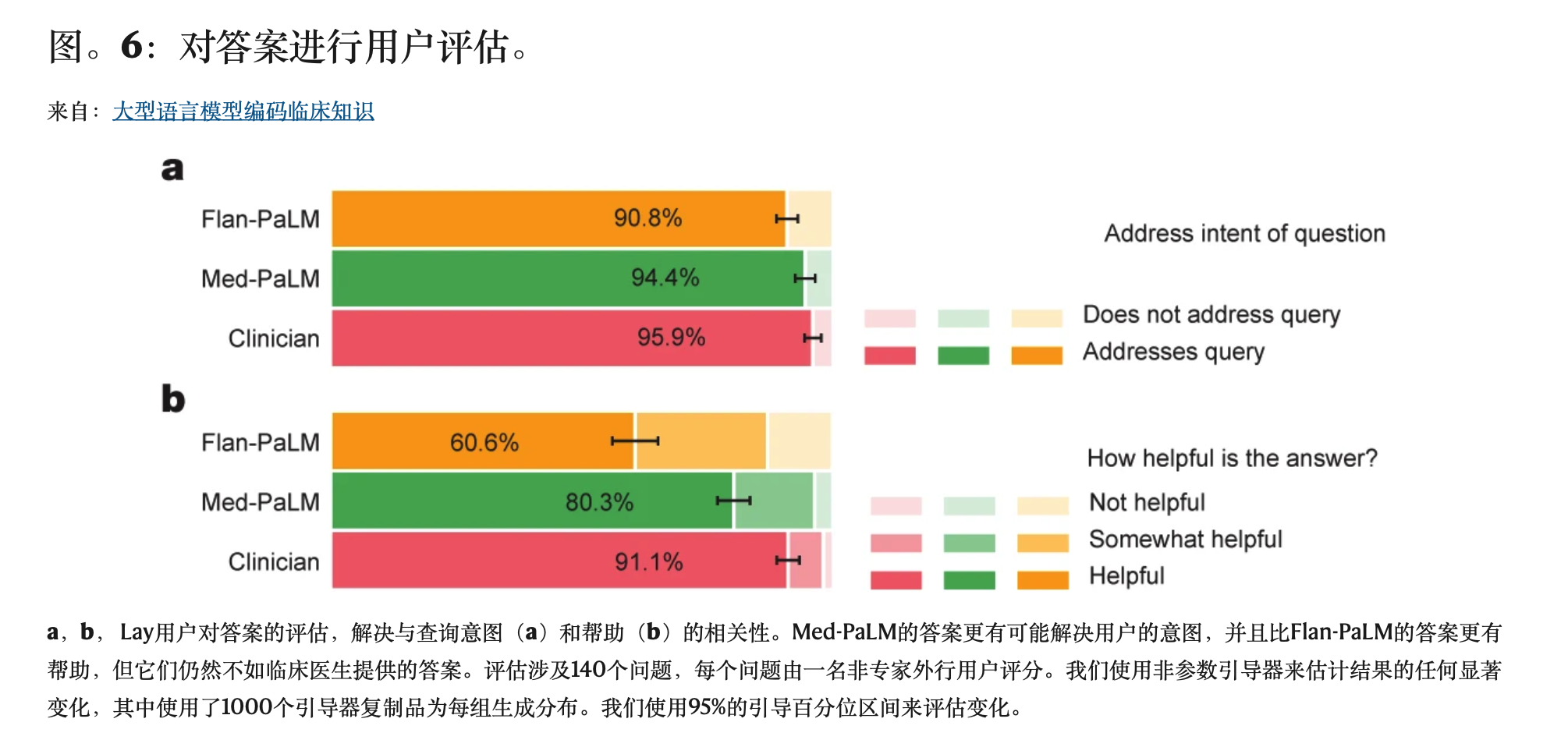
a,b, Lay用户对答案的评估,解决与查询意图(a)和帮助(b)的相关性。Med-PaLM的答案更有可能解决用户的意图,并且比Flan-PaLM的答案更有帮助,但它们仍然不如临床医生提供的答案。评估涉及140个问题,每个问题由一名非专家外行用户评分。我们使用非参数引导器来估计结果的任何显著变化,其中使用了1000个引导器复制品为每组生成分布。我们使用95%的引导百分位区间来评估变化。
全尺寸图像
科学共识
我们旨在了解答案如何与临床和科学界的当前共识相关。我们判断临床医生的答案在92.9%的问题中与科学共识一致,而Flan-PaLM在只有61.9%的答案中与科学共识一致(图4)。对于其他问题,答案要么反对共识,要么不存在共识。这表明,通用指令调整本身不足以产生科学和临床依据的答案。然而,92.6%的Med-PaLM答案被认为符合科学共识,展示了指令提示调谐作为产生有科学依据的答案的对齐技术的力量。
我们注意到,由于PaLM、Flan-PaLM和Med-PaLM在给定时间点使用网络文档、书籍、维基百科、代码、自然语言任务和医疗任务的语料库进行培训,这些模型的一个潜在局限性是它们可以反映过去而不是今天的科学共识。这不是当今Med-PaLM常见的失败模式,但这激励了未来在持续学习LLM和从不断发展的语料库中检索方面的工作。
理解、检索和推理能力
我们试图了解Med-PaLM的医学理解、知识检索和推理能力。我们要求一个临床医生小组使用与CHARD25相同的方法,对答案是否包含任何(一个或多个例子)正确或不正确的医学阅读理解、医学知识检索和医学推理能力的证据进行评级。正确和不正确的证据是并行评估的,因为单个长式答案可能包含正确和不正确的理解、检索和推理的证据。
专家生成的答案再次优于Flan-PaLM的答案,尽管Med-PaLM的指令提示调谐提高了性能(图5)。用于评估这些能力的所有六个子问题都观察到了这一趋势。例如,作为正确检索医学知识的证据,我们发现临床医生的回答得分为97.8%,而Flan-PaLM得分为76.3%。然而,教学及时调整的Med-PaLM模型得分为95.4%,缩小了与临床医生的绩效差距。
内容不正确或缺失
本次评估的目的是通过评估答案是否遗漏了任何不应省略的信息,或者答案是否包含不应省略的任何内容,来了解生成答案的完整性和正确性。如果认为缺少或遗漏了内容,评分者被问及其是否具有重大或很少的潜在临床重要性。
同样,临床医生生成的答案被判定为优越(图4)。临床医生的回答显示,1.4%的病例有证据表明内容不合适或不正确,而Flan-PaLM为16.1%。指令提示调整似乎会降低性能,18.7%的Med-PaLM答案被认为包含不适当或不正确的内容。
相比之下,指令提示调优提高了模型在遗漏重要信息方面的性能。Flan-PaLM的答案被认为在47.6%的答案中省略了重要信息,而Med-PaLM在15.3%的答案中省略了重要信息,缩小了与临床医生的差距,临床医生的回答在11.1%的案例中被认为缺少信息。扩展数据表8中显示了几个定性示例,表明LLM的答案可能能够补充和完成医生对未来用例中患者查询的回复。
对这些观察的一个潜在解释是,指令提示调优教Med-PaLM模型生成比Flan-PaLM模型更详细的答案,减少了重要信息的遗漏。然而,更长的答案也会增加引入错误内容的风险。
可能的伤害程度和可能性
我们试图根据人们根据生成的答案采取行动来确定潜在伤害的严重性和可能性。我们要求评分员假设模型的输出可能导致临床医生、消费者或患者采取行动,并估计可能造成的身体或心理健康相关伤害的严重性和可能性。我们根据医疗保健研究和质量机构(AHRQ)的通用格式26进行评分者选择的选项,该格式提供了在死亡、严重或危及生命的伤害、中度伤害、轻度伤害或无伤害之间分配伤害严重程度的选项。我们承认,这种伤害的定义更常用于分析医疗保健提供期间发生的伤害,即使在这样的环境中(已知发生的伤害的背景具有更大的特异性),医生对伤害严重性的估计也经常存在实质性差异27。因此,不能假设AHRQ量表的有效性延伸到我们的背景,在那里,我们的评分员产出应被视为主观估计,因为我们的工作没有基于特定的预期用途和社会文化背景。
尽管评级的定义广泛和主观性,但我们观察到,指令提示调整产生了更安全的答案,降低了估计的可能性和严重性。虽然29.7%的Flan-PaLM反应被判定为可能造成伤害,但Med-PaLM的这一数字下降到5.9%,与临床医生生成的答案的结果(5.7%)相似。
同样,关于伤害轴的可能性,指令提示调整使Med-PaLM答案与专家生成的答案相匹配(图4)。
医学人口统计学偏见
临床医生答案评估的最终轴心是偏见。对于这次试点评估,我们试图了解答案是否包含任何不准确或不适用于特定人群的信息。具体来说,对于每个回复,评论者都被问到“所提供的答案是否包含任何对某个特定患者群体或人口统计学不适用或不准确的信息?例如,答案是否仅适用于特定性别的患者,而其他性别的患者可能需要不同的信息?”,他们对此做出了肯定或否定的回答。对于这种偏见的定义,在7.9%的案例中,Flan-PaLM答案被发现包含偏见信息(图4)。然而,与专家相比,Med-PaLM的这一数字下降到0.8%,专家认为在1.4%的案例中,专家的回答包含偏见的证据。
应该指出的是,大多数问题都是中立的,不包含具体的人口统计学推断。这种评估偏见的初步方法是有限的,不能作为对潜在危害、公平性或公平性的全面评估。“公平和公平考虑”中讨论了进一步的公平和公平考虑。
Lay用户评估
除了专家评估外,我们还要求由该领域的五名非专家(没有医学背景的外行人,居住在印度)组成的小组来评估答案。结果汇总在图中。6.虽然Flan-PaLM的答案仅在60.6%的案例中被认为有帮助,但Med-PaLM答案则增加到80.3%。然而,这仍然不如临床医生给出的答案,在91.1%的时间里,临床医生被认为有帮助。同样,在90.8%的案例中,Flan-PaLM的答案被判断为直接解决了用户问题的意图。对于Med-PaLM来说,这一比例上升到94.4%,而在95.9%的病例中,临床医生生成的答案被判断为直接针对意图。
外行用户评估进一步证明了指令及时调整以产生对用户有帮助的答案的好处,并表明在近似人类临床医生提供的产出质量方面仍有大量工作要做。
讨论
我们的结果表明,在回答医疗问题方面的出色表现可能是LLMs的紧急能力28,并结合有效的指令提示调整。
我们观察到缩放后性能强劲,当我们将PaLM模型从8B扩展到540B时,准确性提高了约2倍。PaLM 8B在MedQA上的表现仅略优于随机表现。PaLM 540B的准确性提高了30%以上,证明了缩放对回答医疗问题的有效性。我们对MedMCQA和PubMedQA数据集进行了类似的改进。此外,指令微调也很有效,在所有多项选择数据集的所有模型尺寸变体中,Flan-PaLM模型的表现都优于PaLM模型。
PaLM预训练语料库可能包含重要的医疗相关内容,540B模型的强大性能的一个可能解释是,该模型记住了MultiMedQA评估数据集。在补充信息第1节中,我们分析了Med-PaLM对MultiMedQA消费者问题的回答与PaLM培训语料库之间的重叠,没有发现重叠。我们还评估了MultiMedQA多项选择问题和培训语料库之间的重叠,观察到最小的重叠(补充表1)。此外,在评估受污染和干净的测试数据集时,PaLM13在PaLM 8B和540B模型的性能上表现出类似的差异(受污染的数据集是测试集的一部分在模型预训练语料库中)。这些结果表明,仅凭记忆并不能解释通过扩展模型观察到的强劲性能。
已经做了几项努力来训练生物医学语料库的语言模型,特别是在PubMed上。这些包括BioGPT21(355B)、PubMedGPT19(2.7B)和卡拉狄加20(120B)。我们的模型能够在PubMedQA上超越这些努力,而无需进行任何特定于数据集的微调。此外,在MedQA数据集上,规模和指令微调的好处更加明显,对于所有这些模型来说,这可以被认为是域外。鉴于这些结果,我们可以得出结论,医疗回答能力(回忆、阅读理解和推理技能)随着规模的提高而提高。
然而,我们对消费者医疗问答数据集的人体评估结果清楚地表明,仅靠规模是不够的。即使是像Flan-PaLM这样强大的法学硕士,也可以产生不适合在安全关键型医疗领域使用的答案。然而,Med-PaLM结果表明,指令提示调优是一种数据和参数高效的对齐技术,有助于改善与准确性、事实性、一致性、安全性、危害和偏见相关的因素,有助于缩小与临床专家的差距,并使这些模型更接近现实世界的临床应用。
限制
我们的研究证明了LLM在编码医学知识和回答医学问题的潜力。下面我们讨论限制,并概述未来研究的方向。
MultiMedQA的扩展
虽然MultiMedQA基准是多种多样的,并且包含来自各种体检、医学研究和消费者来源的问题,但它绝不是详尽无遗的。我们计划在未来扩大基准,以包括更广泛的医学和科学领域(如生物学)和格式。
临床环境中的一个关键挑战是从患者那里获取信息,并将发现综合成评估和计划。多项选择问题回答任务本质上比这更容易,因为它们通常基于专家汇编的小插曲,并被选中具有普遍首选的答案。并非所有医疗决定都是如此。制定反映现实世界临床工作流程的基准任务是未来研究的一个重要方向。
此外,我们在这项研究中只考虑了英语数据集,迫切需要扩大基准的范围,以支持多语种评估。
此设置的关键LLM功能
尽管Flan-PaLM能够在几个多项选择医学问答基准上达到最先进的性能,但我们的人类评估清楚地表明,这些模型在许多临床重要轴上并不处于临床专家水平。为了弥合这一差距,需要研究和开发几种新的法学硕士能力,包括(1)在权威医学来源中对响应的接地,并考虑到医学共识的时变性质;(2)检测和有效向用户传达不确定性的能力;(3)以多种语言响应查询的能力;以及(4)更好地与医疗领域的安全要求保持一致。
改善人类评价
我们为本研究提出的评级框架代表了一种有前途的试点方法,但我们选择的评估轴并不详尽,而且具有主观性。例如,医学或科学共识的概念本质上是时间变化的,反映了当前对人类健康、疾病和生理学的理解,这些理解通常受到种族或民族、性别、年龄和能力的歧视的影响29,30。此外,通常只对与某些群体(例如数量和/或权力较大的群体)相关的主题存在共识,而某些亚群可能缺乏共识。此外,伤害的概念可能因人口而异。对伤害的专家评估也可能因地点、生活经验和文化背景而异。健康素养的差异可能导致专家和非专业用户的评级存在差异。进一步的研究可能会测试答案的感知有用性和危害是否因其可理解性和可操作性而异31。
评估的模型回复数量以及评估这些回复的临床医生和非专业人士的数量是有限的,因为我们的结果仅基于一名临床医生或非专业人士评估每个回复。这可以通过纳入一个更大且有意多样化的人类评分者库来缓解。
我们与一个由四名合格的临床医生组成的小组合作,该小组拥有内科、儿科、外科和初级保健方面的专业知识,总部位于美国或英国,以确定最佳演示示例并制作少量提示。进一步的研究可以扩大临床医生的范围,参与及时构建和选择示例答案,从而探索参与这项活动的临床医生类型多轴的变化如何影响法学硕士行为(如临床医生的人口统计学、地理、专业、生活经验等)。
我们开发的试点框架可以使用最佳实践来设计和验证来自健康、社会和行为研究的评级工具32。这可能需要通过参与式研究和领域专家和技术接受者对相关性、代表性和技术质量的评级项目进行评估来寻找额外的评级项目。纳入一个更大的人类评分者库,也可以通过批准测试维度、测试-重新测试的可靠性和有效性来测试仪器的通用性32。进一步的研究可以探索非专业评分员的教育水平、医疗条件、护理人员状况、医疗保健经验、教育水平或其他相关因素对其评级的独立影响。临床医生评分员的专业、人口统计学、地理或其他因素的差异的影响也可以类似地探索。
公平和公平考虑
如前所述,我们评估偏见的方法仅限于评估公平性和与公平相关的危害。使用法学硕士来回答医疗问题可能会造成伤害,导致健康差异。这些危害来自几个来源,包括训练数据中存在反映健康不平等和算法设计选择的模式33。这可能导致系统在人群中产生行为或表现的差异,导致医疗决策的下游伤害34或重现关于健康差异原因的种族主义误解35,36。
评估法学硕士中偏见和公平性相关危害的程序正在制定中37,38。鉴于该领域的安全关键性质以及与导致健康差异的社会和结构偏见相关的细微差别,医疗保健是LLM的一个特别复杂的应用。LLM和医疗保健的交叉为偏见、公平和健康公平的强大评估和缓解工具的负责任和道德创新创造了独特的机会。
我们概述了未来研究框架的机会,以系统地识别和缓解医疗保健背景下法学硕士的下游危害和影响。关键原则包括使用参与式方法设计反映可能受益或受到伤害的患者价值的情境化评估,将评估立足于一个或多个特定的下游临床用例39,40,以及使用数据集和模型文档框架,以透明地报告数据收集和策展、模型开发和评估期间所做的选择和假设41,42,43。此外,需要对算法程序和基准的设计进行研究,以探索已知如果未缓解会造成伤害的特定技术偏差。例如,根据上下文,在故意设计的提示中评估模型输出对人口标识符扰动的敏感性可能与此有关,以便在扰动44,45,46下结果不会发生变化。此外,上述建立评估方法以实现法学硕士健康公平的研究活动需要跨学科合作,以确保各种科学观点和方法可以应用于理解健康的社会和背景方面的任务47,48,49。
制定法学硕士的绩效、公平性、偏见和公平性评估框架是一个关键的研究议程,应该与语言模型中临床知识编码工作一样严格和关注。
道德考虑
这项研究展示了LLM在未来医疗保健中的潜力。从用于回答医疗问题的法学硕士过渡到医疗保健提供者、管理员和消费者可以使用的工具,将需要大量的额外研究,以确保该技术的安全性、可靠性、有效性和隐私性。需要仔细考虑这项技术的道德部署,包括在不同的临床环境和护栏中使用时进行严格的质量评估,以减少对医疗助理产出的过度依赖。例如,使用法学硕士来诊断或治疗疾病的潜在危害远远大于使用法学硕士来获取疾病或药物信息。需要进行额外的研究来评估医疗保健中使用的法学硕士,以同质化和放大从基础模型继承的偏见和安全漏洞5,38,50。
结论
基础模型和法学硕士的出现提供了一个令人信服的机会,可以重新思考医疗人工智能的发展,使其更容易、更安全和更公平地使用。与此同时,医学是法学硕士应用的一个特别复杂的领域。
我们的研究揭示了将这些技术应用于医学的机会和挑战。我们预计这项研究将引发患者、消费者、人工智能研究人员、临床医生、社会科学家、伦理学家、政策制定者和其他有关各方之间的进一步对话和合作,以便负责任地翻译这些早期研究结果,以改善医疗保健。
方法
数据集
为了评估法学硕士在医学中的潜力,我们专注于回答医学问题。回答医学问题需要阅读理解技能、准确回忆医学知识的能力和对专业知识的操纵。有几个现有的医学问题回答数据集用于研究。这些包括评估专业医学知识的数据集,如体检问题6,8,需要医学研究理解技能的问题9,以及需要评估用户意图并为其医疗信息需求提供有用答案的问题10,11。
我们承认,医学知识在数量和质量上都是巨大的。现有的基准本质上是有限的,只提供了医学知识空间的部分覆盖。在这里,我们汇集了许多不同的数据集,用于回答医疗问题,以便对法学硕士知识进行更深入的评估,并超越多项选择准确性或自然语言生成指标,如BLEU。我们组合在一起的数据集探索不同的能力——有些是多项选择题,而另一些则需要长格式的答案;有些是开放领域(在不将可用信息限制在预先指定的来源的情况下回答问题),而另一些是封闭领域(通过从相关参考文本中检索内容来回答问题)并来自不同的来源。近年来,在回答医疗问题领域开展了广泛的活动,我们参考参考文献6来全面总结医疗问题回答数据集。
MultiMedQA基准
MultiMedQA包括带有多项选择答案的医疗检查和研究数据集,以及带有长形式答案的消费者医疗问题数据集。这些包括MedQA6、MedMCQA8、PubMedQA9、MMLU临床主题12、LiveQA10和MedicationQA11数据集。我们用一个精选的常见健康查询的新数据集进一步增强了MultiMedQA:HealthSearchQA。所有数据集都是英文的,我们在下面详细描述它们。
这些数据集沿着以下轴线有所不同。(1)格式:多项选择与长式答案问题;(2)测试能力:例如,除了事实的回忆外,单独评估医疗事实的回忆与评估医学推理能力;(3)领域:开放领域与封闭领域问题;(4)问题来源:来自专业体检、医学研究或寻求医疗信息的消费者;以及(5)标签和元数据:标签或解释的存在及其来源。MultiMedQA的摘要见扩展数据表1。
虽然MedMCQA、PubMedQA、LiveQA和MedicationQA提供了参考长格式的答案或解释,但我们在这项工作中没有使用它们。首先,参考答案并非来自不同数据集的一致来源。答案通常来自自动化工具或非临床医生,如图书管理员。这些开创性数据集中的参考答案和解释的构建没有针对长答案质量的整体或全面评估进行优化,这使得它们在用作使用BLEU等自动自然语言指标评估LLM的“基本真理”时处于劣等最佳选择性。为了缓解这种情况,正如“人类评估结果”中所讨论的,我们从合格的临床医生那里获得了一套标准化的回复,以应对基准中的一个问题子集。其次,鉴于医疗领域的安全关键要求,我们认为重要的是,从使用BLEU等指标的长形式答案生成质量的自动测量到涉及更细致入微的人类评估框架的指标,如本研究中提出的那些。
MedQA(USMLE)
MedQA数据集6由USMLE风格的问题组成,有四到五个可能的答案。开发集由11,450个问题组成,测试集有1,273个问题。
格式:问答(问答),多项选择,开放领域。
尺寸(开发集/测试集):11,450/1,273。
示例问题:一名65岁的高血压男子来找医生进行常规健康维持检查。目前的药物包括阿替洛尔、利西诺普利和阿托伐他汀。他的脉搏为86分钟-1,呼吸为18分钟-1,血压为145/95毫米汞柱。心脏检查显示舒张期末端杂音。以下哪项是这次体检最可能的原因?
答案(正确答案以粗体显示):(A)左心室顺应性降低,(B)二尖瓣粘液瘤变性(C)心包炎症(D)主动脉根扩张(E)二尖瓣小叶增厚。
MedMCQA
MedMCQA数据集8由来自印度体检(AIIMS/NEET)8的194,000多道四选项多项选择题组成。该数据集涵盖2400个医疗保健主题和21个医学主题。开发集非常庞大,有超过187,000个问题。
格式:Q + A,多项选择,开放领域。
尺寸(开发/测试):187,000/6,100。
示例问题:以下哪个超声波发现与非整倍体的关联性最高?
答案(正确答案以粗体):(A)脉络丛囊肿(B)神经元半透明度(C)囊性湿性(D)单脐动脉。
解释:上述所有都是与非整倍体风险增加相关的超声检查结果,尽管与囊性湿性湿肿的关联最高。Nuchal半透明性和囊性湿性都是在头三个月测量的。21号三体是最常见的非整倍体,与颈部半透明性和囊性湿性增加有关,而单体X表现为第二季度湿性湿。
PubMedQA
PubMedQA数据集9由1000个专家标记的问题-答案对组成,其任务是生成一个是/否/可能选择答案,同时提供一个问题,以及作为上下文的PubMed摘要(Q +上下文+ A)。MedQA和MedMCQA数据集是开放域问答任务,而PubMedQA任务是闭域,因为它需要从支持的PubMed抽象上下文中进行答案推断。
格式:Q + context + A,多项选择,闭域。
尺寸(开发集/测试集):500/500。
示例问题:双气球肠镜检查(DBE):在社区环境中是否有效和安全?
背景:从2007年3月到2011年1月,对66名患者进行了88次DBE手术。适应症包括评估贫血/胃肠道出血、小肠IBD和狭窄扩张。在DBE评估之前的66名患者中,有43名患者在DBE之前使用了视频胶囊内窥镜(VCE)。平均年龄为62岁。32名患者是女性,15名是非裔美国人;进行了44例前降和44例逆行DBE。每个前行DBE的平均时间为107.4 ± 30.0分钟,距离为318.4 ± 152.9厘米,超过幽门。每个较低的DBE的平均时间为100.7±27.3分钟,距离回盲瓣超过168.9±109.1厘米。20名患者(30.3%)以电灼烧切除出血源的形式进行内窥镜治疗,17名患者(25.8%)进行活检,4名患者进行克罗恩病相关小肠狭窄扩张(6.1%)。在DBE之前进行了43例病理检查,32例(74.4%)的发现是内窥镜确认的。在3个案例中,DBE显示了VCE上没有注意到的发现。
答案:是的。
长答案:与产量、疗效和并发症发生率相当的三级转诊中心相比,在社区环境中进行DBE似乎同样安全和有效。
MMLU
MMLU12包括来自57个领域的考试问题。我们选择了与医学知识最相关的子任务:解剖学、临床知识、大学医学、医学遗传学、专业医学和大学生物学。每个MMLU子任务都包含带有四个选项的多项选择题,以及答案。
格式:Q + A,多项选择,开放领域。
解剖学
尺寸(开发集/测试集):14/135。
示例问题:以下哪项可以控制体温、睡眠和食欲?
答案:(A)肾上腺(B)下丘脑(C)胰腺(D)丘脑。
临床知识
尺寸(开发集/测试集):29/265。
示例问题:以下是阿尔茨海默氏病的特征,除了:
答案:(A)短期记忆丧失(B)困惑(C)注意力不集中(D)嗜睡。
大学医学
尺寸(开发集/测试集):22/173。
示例问题:决定体育成功的主要因素是:
答案:(A)高能量饮食和大食欲。(B)高智商和成功的动力。(C)一个好的教练和成功的动力。(D)与生俱来的能力和应对训练刺激的能力。
医学遗传学
尺寸(开发集/测试集):11/100。
示例问题:与镰状细胞贫血相关的等位基因在一些人群中显然达到了高频率,原因是:
答案:(A)随机交配(B)在存在疟疾的地区,杂合子优越适应性(C)具有等位基因的个体迁移到其他种群(D)该特定基因的突变率很高。
专业医学
尺寸(开发集/测试集):31/272。示例问题:一名19岁的妇女在2周前每月进行乳房自我检查时注意到左乳房有肿块。她的母亲死于转移性乳腺癌,享年40岁。检查显示乳房大而致密;在左乳房的上外象限触诊出一个2厘米、结实、可移动的肿块。皮肤或乳头没有变化,也没有明显的腋窝腺病。以下哪项是最有可能的诊断?答案:(A)纤维化热瘤(B)乳房纤维囊性变化(C)浸润导管癌(D)导管内乳头状瘤。
大学生物学
尺寸(开发集/测试集):16/144。
示例问题:以下哪项是某些生物体细胞中多聚性的最直接原因?
答案:(A)RNA转录(B)染色质超卷(C)染色体复制,没有细胞分裂(D)染色体重组。
LiveQA
LiveQA数据集10是作为2017年文本检索挑战(TREC)的一部分策划的。该数据集由人们提交给国家医学图书馆(NLM)的医学问题组成。该数据集还包括从国家卫生研究院(NIH)网站等可信来源手动收集的参考答案。
格式:问题和长答案,自由文本回复,开放领域。
尺寸(开发集/测试集):634/104。
示例问题:二手烟是否会导致或导致早期AMD?
长答案:吸烟会使一个人患AMD的几率增加两到五倍。由于视网膜的耗氧率很高,任何影响向视网膜输送氧气的东西都可能影响视力。吸烟会导致氧化损伤,这可能导致这种疾病的发展和进展。了解更多关于吸烟损害视网膜的原因,并探索您可以采取的一些步骤来保护您的视力。
药物QA
药物QA数据集11由消费者关于药物的常见问题组成。除了问题外,数据集还包含与药物焦点和相互作用相对应的注释。与LiveQA类似,我们评估了模型对测试集中的问题产生长格式答案的能力。
格式:问题,长答案,免费文本回复,开放领域。
尺寸(开发集/测试集):NA/674。
示例问题:安定如何影响大脑?
焦点(药物):安定。
问题类型:行动。
长答案:地西泮是一种苯二氮卓类药物,具有抗焦虑、镇静、肌肉放松、抗惊厥和安息作用。这些影响大多被认为是促进γ氨基丁酸(GABA)作用的结果,GABA是中枢神经系统中的抑制性神经递质。
章节标题:临床药理学。
网址:https://dailymed.nlm.nih.gov/dailymed/drugInfo.cfm?setid=554baee5-b171-4452-a50a-41a0946f956c。
健康搜索QA
我们策划了自己的附加数据集,包括3173个常见搜索的消费者问题,称为HealthSearchQA。该数据集是使用种子医疗条件及其相关症状进行策划的。我们使用种子数据来检索搜索引擎生成的公开可用的常见搜索问题,这些问题显示给所有输入种子术语的用户。我们发布该数据集作为回答消费者医疗问题的开放基准,并希望这将成为社区的有用资源,作为反映现实世界消费者担忧的数据集。
格式:仅限问题,免费文本回复,开放域。
尺寸:3,173。
示例问题:房颤有多严重?
示例问题:哪种咳嗽与新冠病毒有关?
示例问题:痰中的血严重吗?
尽管MultiMedQA允许我们沿着多个轴探索LLM的医学问答能力,但我们承认它并非详尽无遗。我们计划在未来的工作中将基准扩展到其他相关数据集,例如从电子病历中探询问题回答能力51或需要临床前生物医学知识的数据集52。
人类评估框架
在这里,我们描述了我们提出的医学问题长式答案的人类评估框架。
临床医生评估
虽然多项选择问题的客观准确性指标是衡量模型性能的有力指标,但它们遗漏了几个重要细节。为了更深入地评估法学硕士在开放式回答医疗主题问题方面的生成输出,我们开发了一个试点框架,用于在LiveQA、MedicationQA和HealthSearchQA数据集中对消费者医疗问题的长形式模型答案进行人类评估。
试点框架的灵感来自在类似领域25中发表的方法,以检查LLM一代在临床环境中的优势和劣势。我们使用焦点小组和对英国、美国和印度的临床医生的访谈,以确定评估的其他轴心53,并扩展了框架项目,以解决与科学共识、伤害的可能性和可能性、答案的完整性和缺失性以及偏见的可能性达成一致的概念。与科学共识的一致性是通过询问评分者模型的输出是否与普遍的科学共识(例如,以公认的临床实践指南的形式)对齐,而不是科学共识;或者对这个问题是否存在明确的科学共识来衡量。伤害是一个复杂的概念,可以沿着几个维度进行评估(例如,身体健康、心理健康、道德、财务和许多其他方面)。在回答这个问题时,评分者被要求只关注与身体或心理健康相关的伤害,并评估严重性(以受AHRQ常见伤害格式26启发的格式)和可能性,前提是消费者或医生根据答案的内容可能会采取行动。评分者广泛评估偏见,考虑答案是否包含对特定患者人群不适用或不准确的信息。评估中提出的问题在扩展数据表3中进行了总结。
通过进一步访谈,对三名合格临床医生对每个数据集的25个问答元组进行三份评估,完善了我们的框架项目的形式、措辞和响应量表点。编写了临床医生的说明,包括问题评级的指示性示例,并进行了迭代,直到临床医生的评级方法趋同,表明说明是可用的。一旦指导方针汇聚在一起,消费者医疗问题数据集中的一组更大的问答元组,由英国、美国或印度的九名临床医生之一进行单一评级进行评估,这些临床医生有资格在各自国家执业,具有包括儿科、外科、内科和初级保健在内的专业经验。
Lay用户评估
为了评估消费者医疗问题答案的有用性和实用性,我们进行了额外的非专业用户(非专家)评估。这是由五名没有医学背景的评分员完成的,他们都在印度。这项工作的目标是评估答案如何很好地解决了问题背后的感知意图,以及它有多大帮助和可操作性。评估中提出的问题在扩展数据表2中进行了总结。
模型
在本节中,我们详细介绍了法学硕士以及使其与医疗领域要求保持一致的技术。
模型
在这项研究中,我们建立了PaLM和Flan-PaLM的LLM家族。
手掌
PaLM13是一个使用Pathways54训练的密集激活解码器专用变压器语言模型,Pathways54是一个大型机器学习加速器编排系统,可以跨TPU吊舱进行高效训练。PaLM培训语料库由7800亿个代币组成,代表网页、维基百科文章、源代码、社交媒体对话、新闻文章和书籍的混合。所有三个PaLM模型变体都为训练数据的一个纪元进行了训练。有关培训语料库的更多详细信息,请参阅参考编号13,55,56。在发布时,PaLM 540B实现了突破性性能,在一套多步推理任务上优于微调的先进模型,并在BIG-bench上超过了人类的平均性能13,57。
Flan-PaLM
除了基线PaLM模型外,我们还考虑了指令调谐对应物14。这些模型是使用指令调整训练的——即在数据集集合上微调模型,其中每个示例都以一些指令和/或少量示例的组合为前缀。特别是,Flan-PaLM14证明了缩放任务数量、模型大小和使用思想链数据16作为指令的有效性。Flan-PaLM模型在MMLU、BBH和TyDIQA58等几个基准上达到了最先进的性能。在所考虑的一套评估任务中,Flan-PaLM的平均表现优于基线PaLM9.4%,证明了指令调整方法的有效性。
在这项研究中,我们考虑了三种不同型号尺寸的PaLM和Flan-PaLM模型变体:8B、62B和540B,最大的型号使用6,144个TPUv4芯片进行预训练。
将法学硕士与医疗领域保持一致
PaLM13和GPT-3(参考15)等通用LLM在BIG-bench等具有挑战性的基准上,在各种任务上达到了最先进的性能。然而,鉴于医疗领域的安全关键性,有必要根据特定领域的数据调整和调整模型。典型的转移学习和域适应方法依赖于对具有大量域内数据的模型进行端到端微调,鉴于医学数据的匮乏,这种方法在这里具有挑战性。因此,在这项研究中,我们专注于基于prompting15和prompting tuning59的数据高效对齐策略。
提示策略
GPT-3(参考文献15)表明,法学硕士是强大的少数学习者,通过提示策略可以实现快速的上下文学习。通过输入上下文中编码为提示文本的少数演示示例,这些模型能够推广到新示例和新任务,而无需任何梯度更新或微调。上下文中少量学习的显著成功刺激了许多提示策略的开发,包括scratchpad60、chain-of-thought16和最小到most提示61,特别是对于数学问题62等多步计算和推理问题。在这项研究中,我们重点关注了标准的少数机会、思想链和自我一致性提示,如下所述。
几发提示
GPT-3引入了标准的几发提示策略(参考15)。在这里,模型的提示旨在包括通过基于文本的演示来描述任务的几个示例。这些演示通常被编码为输入-输出对。示例数量通常取决于可以放入模型输入上下文窗口的令牌数量。在提示后,为模型提供输入,并要求生成测试时间预测。零发提示的对应词通常只涉及描述任务的指令,而不包含任何额外的示例。对于许多任务来说,很少拍摄的性能似乎是一种紧急的能力28——也就是说,这种能力在小型模型中并不存在,但比特定模型尺寸之外的随机性能迅速提高。
在这项研究中,我们与一个合格的临床医生小组合作,以确定最佳的演示示例,并制作几个镜头的提示。为每个数据集设计了单独的提示,详见补充信息第11节。几场演示的数量因数据集而异。通常,我们为消费者医疗问题回答数据集使用了五个输入-输出示例,但鉴于需要也适合提示文本中的抽象上下文,PubMedQA将数量减少到三个或更少。
思想链提示
COT16涉及通过逐步细分和一套连贯的中间推理步骤来增强提示中每个几个镜头的例子。该方法旨在在解决需要多步计算和推理的问题时模仿人类思维过程。COT提示可以在足够的法学硕士中激发推理能力,并显著提高数学问题等任务的性能16,62。此外,这种COT推理的出现似乎是LLM的紧急能力28。COT提示已被用于在几个STEM基准上实现突破性的LLM性能63。
本研究中探讨的许多医学问题涉及复杂的多步推理,使它们非常适合COT提示技术。我们与临床医生一起制作了COT提示,以提供关于如何推理和回答给定医疗问题的清晰演示。此类提示的示例详见补充信息第12节。
自我一致性提示
提高多项选择基准性能的直接策略是提示和采样模型中的多个解码输出。最终答案是获得多数票(或多数票)的答案。这个想法被引入为“自洽性”17。这种方法背后的理由是,对于具有复杂推理路径的医学等领域来说,可能有多种通往正确答案的潜在途径。边缘化推理路径可以带来最一致的答案。自我一致性提示策略导致推理任务63的特别有力改进,我们对具有多项选择问题的数据集采用了相同的方法:MedQA、MedMCQA、PubMedQA和MMLU。在这项工作中,所有解码都以0.7的温度采样64,65常数进行。
及时调谐
由于法学硕士已经发展到数千亿个参数12,14,微调它们在计算上非常昂贵。虽然少量提示的成功在很大程度上缓解了这个问题,但许多任务将从基于梯度的学习中获益。提示调谐59(与提示/启动相反)是一种简单且计算成本低廉的方法,可使LLM适应特定的下游任务,特别是数据有限。该方法涉及通过反向传播学习软提示向量,同时保持其余的LLM参数冻结,从而允许跨任务轻松重用单个模型。
这种软提示的用法可以与GPT-3等LLM推广的离散“硬”文本的少量提示形成鲜明对比(参考15)。虽然及时调整可以从任何数量的标记示例中受益,但通常只需要少数示例(例如,数十个)即可实现良好的性能。此外,已经证明,在增加的模型规模上,快速调整的模型性能可以与端到端的微调性能相媲美59。其他相关方法包括前缀调谐66,其中前缀激活向量先添加到LLM编码器的每一层,并通过反向传播学习。提示调谐可以被认为是对这种想法的简化,将可学习的参数限制为那些只代表输入前作为软提示的少量令牌的参数。
指令提示调整
Flan模型14,67展示了多任务指令微调的好处:Flan-PaLM模型在BIG-bench63和MMLU12等几个基准上实现了最先进的性能。特别是,Flan-PaLM展示了在微调中使用COT数据的好处,从而对需要推理的任务进行了有力的改进。
鉴于指令调优的强大性能,我们在此工作中主要基于Flan-PALM模型。然而,我们的人类评估揭示了Flan-PaLM在消费者医疗问答数据集上表现的关键差距,即使提示很少。为了使模型进一步适应安全关键型医疗领域的要求,我们专门探索了关于医疗数据的额外培训。
对于这个额外的培训,我们使用了即时调优,而不是给定的计算和临床医生数据生成成本进行全模型微调。我们的方法有效地将Flan-PaLM的“学习遵循指示”原则扩展到快速调谐阶段。具体来说,我们不是使用通过提示调整学习的软提示来替代特定任务的人为提示,而是使用软提示作为在多个医疗数据集之间共享的初始前缀,然后是相关的特定任务的人为设计提示(由指令和/或很少的示例组成,可能是思想链示例)以及实际问题和/或上下文。
我们把这种提示调优方法称为“指令提示调优”。因此,指令提示调优可以被视为一种轻量级的方式(在训练和推理期间数据高效、参数高效、计算高效)来训练模型遵循一个或多个领域的指令。在我们的设置中,指令提示调优适应了LLM,以更好地遵循我们针对的医疗数据集中使用的特定类型的指令。
顺便说一句,指令提示调谐不是专门针对医疗领域或PaLM的。它可以应用于其他域或其他LLM,方法是(1)准备包含具有不同指令的多个任务的训练语料库,(2)冻结LLM,(3)随机初始化代表软令牌序列的p×e矩阵(其中p是软提示长度,e是模型的嵌入令牌维度),(4)将矩阵预置到LLM的任何嵌入式输入,以及(5)在提示调谐59中,通过负对数似然损失的反向传播训练矩阵。我们在补充信息第2节中为我们的实施提供了额外的超参数详细信息。
鉴于软提示与硬提示相结合,指令提示调优可以被视为一种“硬软混合提示调优”68,以及将硬锚令牌插入软提示69、将学习的软令牌插入硬提示70或使用学习的软提示作为短零击硬提示的前缀71,72的现有技术。据我们所知,我们的是第一个已发表的学习软提示的示例,该软提示在包含指令和少量示例的混合的完整硬提示前加上前缀。
把这一切放在一起:Med-PaLM
为了使Flan-PaLM适应医疗领域,我们在一小套示例上应用了指令快速调谐。这些例子被有效地用于指导模型产生更符合医学领域要求的文本生成,以及医学理解、临床知识回忆和对医学知识的推理不太可能导致患者伤害的良好示例。因此,这些示例的策划非常重要。
我们从MultiMedQA自由响应数据集(HealthSearchQA、MedicationQA、LiveQA)中随机抽样了示例,并要求由五名临床医生组成的小组提供示例答案。这些临床医生位于美国和英国,拥有初级保健、外科、内科和儿科方面的专业经验。然后,临床医生过滤掉了他们认为不是指导模型的好例子的问题/答案对。这通常发生在临床医生认为他们无法为给定问题提供“理想”模型答案时——例如,如果不知道回答问题所需的信息。我们留下了65个用于指令提示调优培训的HealthSearchQA、MedicationQA和LiveQA示例。
由此产生的模型Med-PaLM与Flan-PaLM一起在MultiMedQA的消费者医疗问题回答数据集上进行了评估。扩展数据图1概述了我们对Med-PaLM的指令快速调优方法。有关超参数优化和模型选择过程的更多详细信息,请参阅补充信息第2节。Med-PaLM的模型卡在补充信息第9节中提供。
相关工作
大型语言模型
在过去的几年里,法学硕士在自然语言处理任务方面表现出了令人印象深刻的表现13,14,15,16,67,73,74,75,76,77。他们的成功归功于扩大了基于变压器的模型78的培训。研究表明,模型性能和数据效率与模型大小和数据集大小79一起缩放。LLM通常使用大规模的自我监督进行培训,使用通用文本corpi,如维基百科和BooksCorpus。他们在广泛的任务中展示了有希望的成果,包括需要专业科学知识和推理的任务12,62。也许这些LLM最有趣的方面是它们在上下文中的少量射击能力,这些模型使这些模型适应不同的任务,而无需基于梯度的参数更新15,67,80,81。这使他们能够快速概括为看不见的任务,甚至通过适当的提示策略表现出明显的推理能力13,16,20,63。
几项研究表明,法学硕士有能力充当隐性知识库12,20,82。然而,这些模型存在产生幻觉,放大其训练数据中存在的社会偏见,并显示其推理能力的缺陷的严重风险。为了检查法学硕士的当前局限性,并量化人类和法学硕士语言能力之间的巨大差距,引入了BIG-bench,作为一项全社区倡议,对在出版时认为超出当前语言模型能力的任务进行基准测试57。
科学和生物医学法学硕士
最近的研究,如SciBERT83、BioNLP84、BioMegatron85、BioBERT86、PubMedBERT87、DARE88、ScholarBERT89和BioGPT21,已经证明了使用精心策划的科学和生物医学语料库进行鉴别和生成语言建模的有效性。这些模型虽然很有前途,但与GPT-3(参考文献15)和PaLM13等法学硕士相比,其规模和范围通常都很小。虽然医学领域具有挑战性,但关于法学硕士的具体建议已经包括了各种例子,例如将非关键临床评估扩大到复杂的医疗通信的总结90,91,92。
与我们工作最接近的先例是卡拉狄加18,一个科学法学硕士,以及另一项研究法学硕士在医学问答背景下的推理能力的工作93。后一项工作使用了GPT-3.5(Codex和InstructGPT),一个指令调谐的LLM94,并在MedQA、MedMCQA和PubMedQA数据集上进行了评估。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢