
Learning to Retrieve In-Context Examples for Large Language Models
Liang Wang, Nan Yang, Furu Wei
[Microsoft]
大型语言模型上下文示例检索学习
-
动机:改进大型语言模型(LLM)的上下文学习效果,通过提高选择高质量示例的能力来增强模型的性能。 -
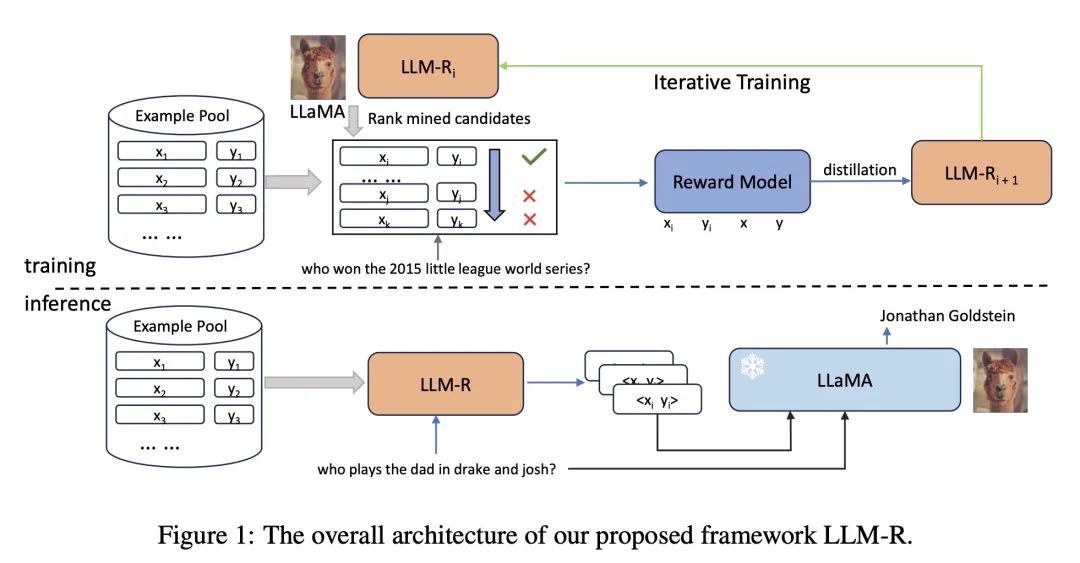
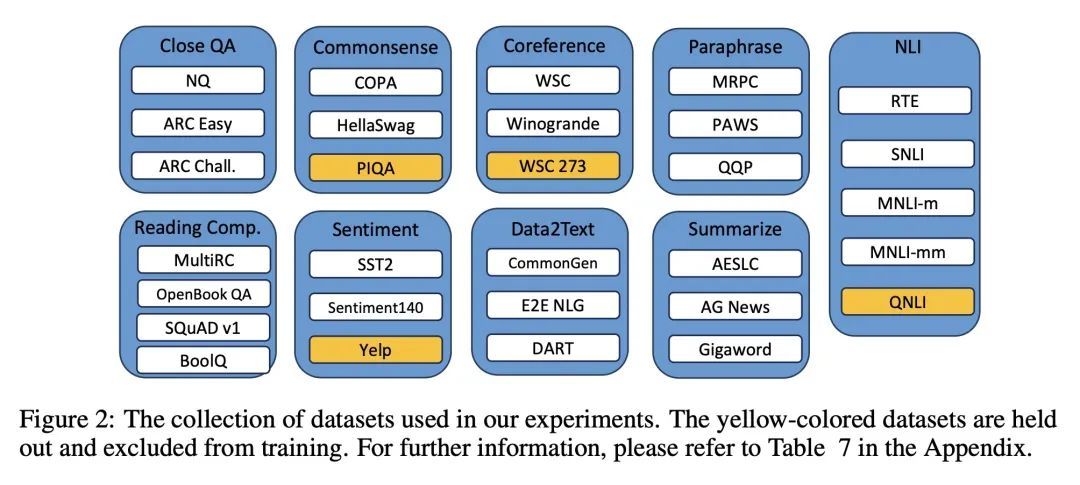
方法:提出一种新框架,通过迭代训练稠密检索器,以为LLM找到高质量的上下文示例。该框架首先基于LLM反馈训练奖励模型,评估候选示例的质量,然后使用知识蒸馏训练基于双编码器的稠密检索器。该框架可以在训练过程中泛化到未见任务,并通过检索具有相似模式的示例来改善性能。 -
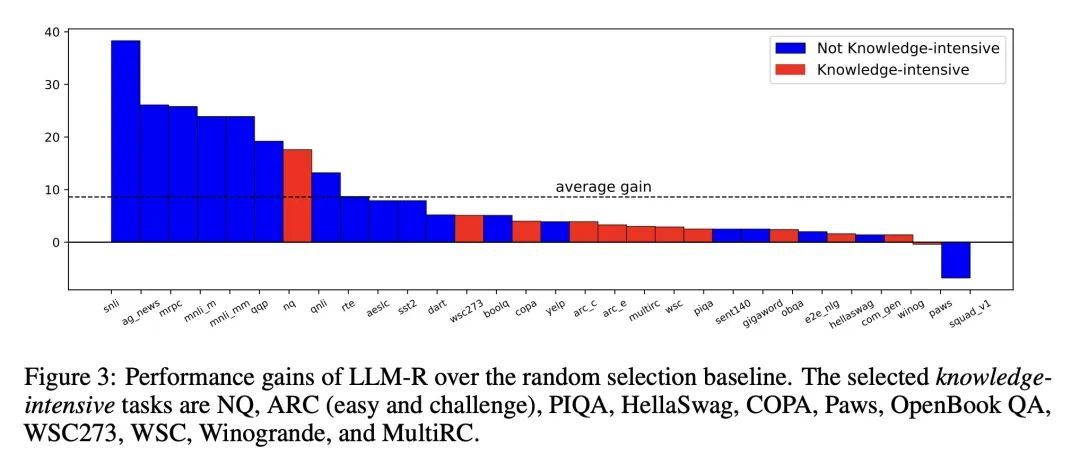
优势:提出一个迭代训练框架,可以显著提升LLM的上下文学习性能。通过检索具有相似模式的示例,模型能获得更好的性能,并且这种提升在不同大小的LLM中都具有一致性。
通过迭代训练稠密检索器,提升大型语言模型的上下文学习能力,改善模型性能,特别适用于具有相似模式的任务。
https://arxiv.org/abs/2307.07164
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢