
Meta 今日发布了大家期待已久的免费可商用版本 Llama 2。

Llama 2 模型接受了 2 万亿个标记的训练,上下文长度是 Llama 1 的两倍。Llama-2-chat 模型还接受了超过 100 万个新的人类注释的训练。Llama 2训练语料相比LLaMA多出40%,上下文长度是由之前的2048升级到4096,可以理解和生成更长的文本。
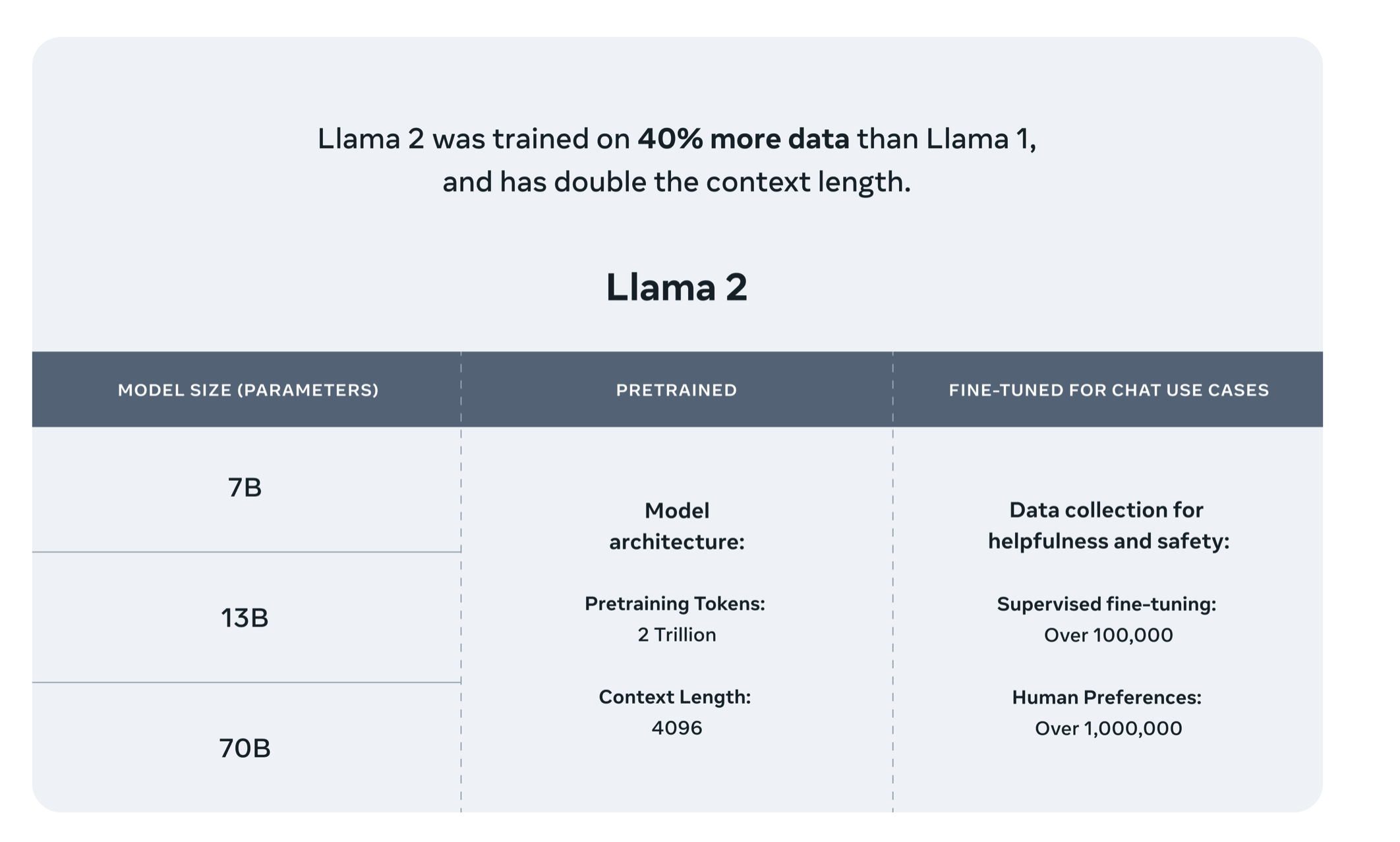
此次 Meta 发布的 Llama 2 模型系列包含 70 亿、130 亿和 700 亿三种参数变体。此外还训练了 340 亿参数变体,但并没有发布,只在技术报告中提到了。
相比于 Llama 1,Llama 2 的训练数据多了 40%,上下文长度也翻倍,并采用了分组查询注意力机制。具体来说,Llama 2 预训练模型是在 2 万亿的 token 上训练的,精调 Chat 模型是在 100 万人类标记数据上训练的。
Llama 2 在包括推理、编码、精通性和知识测试等许多外部基准测试中都优于其他开源语言模型。
作为一组经过预训练和微调的大语言模型(LLM),Llama 2 模型系列的参数规模从 70 亿到 700 亿不等。其中的 Llama 2-Chat 针对对话用例进行了专门优化。
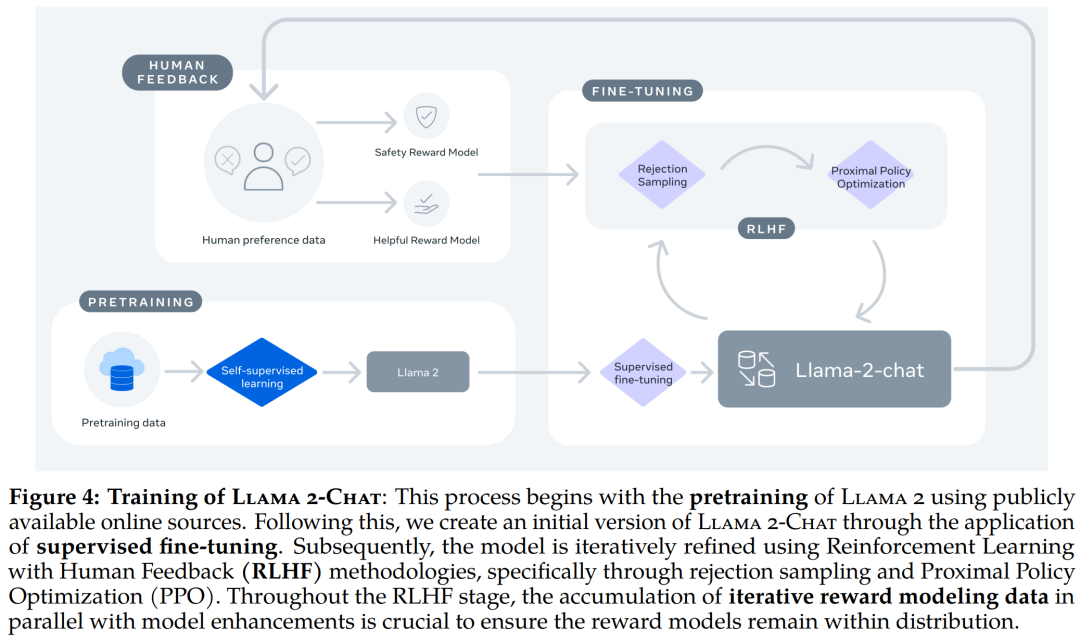
Llama 2-Chat 的训练 pipeline。Llama 2 模型系列除了在大多数基准测试中优于开源模型之外,根据 Meta 对有用性和安全性的人工评估,它或许也是闭源模型的合适替代品。
关于论文:
-
训练语料库包含来自公开来源的新数据组合,其中不包括来自 Meta 产品或服务的数据,强调公开
-
努力从某些已知包含大量个人信息的网站中删除数据,注重隐私。
-
对 2 万亿个token的数据进行了训练,因为这提供了良好的性能与成本权衡,对最真实的来源进行上采样,以增加知识并抑制幻觉,保持真实。
-
进行了各种预训练数据调查,以便用户更好地了解模型的潜在能力和局限性,保证安全。
模型结构:
-
上下文长度:Llama 2 的上下文窗口从 2048 个标记扩展到 4096 个字符。越长上下文窗口使模型能够处理更多信息,这对于支持聊天应用程序中较长的历史记录、各种摘要任务以及理解较长的文档。多个评测结果表示较长的上下文模型在各种通用任务上保持了强大的性能。 - Grouped-Query Attention 分组查询注意力:(1)自回归解码的标准做法是缓存序列中先前标记的键 (K) 和值 (V) 对,从而加快注意力计算速度。然而,随着上下文窗口或批量大小的增加,多头注意力 (MHA) 模型中与 KV 缓存大小相关的内存成本显着增长。对于较大的模型,KV 缓存大小成为瓶颈,键和值投影可以在多个头之间共享,而不会大幅降低性能。可以使用具有单个 KV 投影的原始多查询格式(MQA)或具有 8 KV 投影的分组查询注意力变体(GQA)。(2)论文将 MQA 和 GQA 变体与 MHA 基线进行了比较,使用 150B 字符训练所有模型,同时保持固定的 30B 模型大小。为了在 GQA 和 MQA 中保持相似的总体参数计数,增加前馈层的维度以补偿注意力层的减少。对于 MQA 变体,我们将 FFN 维度增加 1.33 倍,对于 GQA 变体,Llama将其增加 1.3 倍。从结果中观察到 GQA 变体在大多数评估任务上的表现与 MHA 基线相当,并且平均优于 MQA 变体。
关于微调:
-
指令数据质量非常重要,包括多样性,注重隐私安全不包含任何元用户数据,还观察到,不同的注释平台和供应商可能会导致下游模型性能明显不同,这凸显了数据检查的重要性。
-
微调细节:(1)对于监督微调,使用余弦学习率规划器,初始学习率为 2 × 10−5,权重衰减为 0.1,批量大小为 64,序列长度为 4096 个标记。(2)对于微调过程,每个样本都包含提示和答案, 为了确保正确填充模型序列长度,连接训练集中的所有提示和答案。使用特殊标记来分隔提示和答案部分。(3) 利用自回归目标,将用户提示中的token损失归零,仅对答案token进行反向传播。最后对模型进行了 2 个 epoch 的微调。
-
引入Ghost Attention (GAtt)有助于控制多个回合的对话效果。
关于中文:
预训练数据中的语言分布,百分比 >= 0.005%。大多数数据都是英文的,这意味着 Llama 2 在英语用例中表现最佳。大的未知类别是部分由编程代码数据组成。
另外词表也是Llama 1同样大小(32k),所以基于Llama2还需要做中文增强训练。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢