
Chatbot Arena由伯克利大学主导团队 LMSYS Org 近日发布了一个针对大语言模型的基准平台 Chatbot Arena。该平台采用匿名、随机的方式让不同的大模型产品进行对抗评测,基于国际象棋等竞技游戏中广泛使用的埃洛等级分系统,通过用户投票产生,系统每次会随机选择两个不同的大模型机器人和用户聊天,并让用户在匿名的情况下选择哪款大模型产品的表现更好一些。
最后系统根据用户的选择判定大模型产品的积分,以排行榜的形式出现在首页中。现已有53000匿名投票,并有越来越多人开始在该平台为不同的大模型产品投票。
Chatbot Arena发布一个更新的排行榜,其中包含更多模型和两个数据集,用于人类偏好相关研究:最新榜单地址:https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard
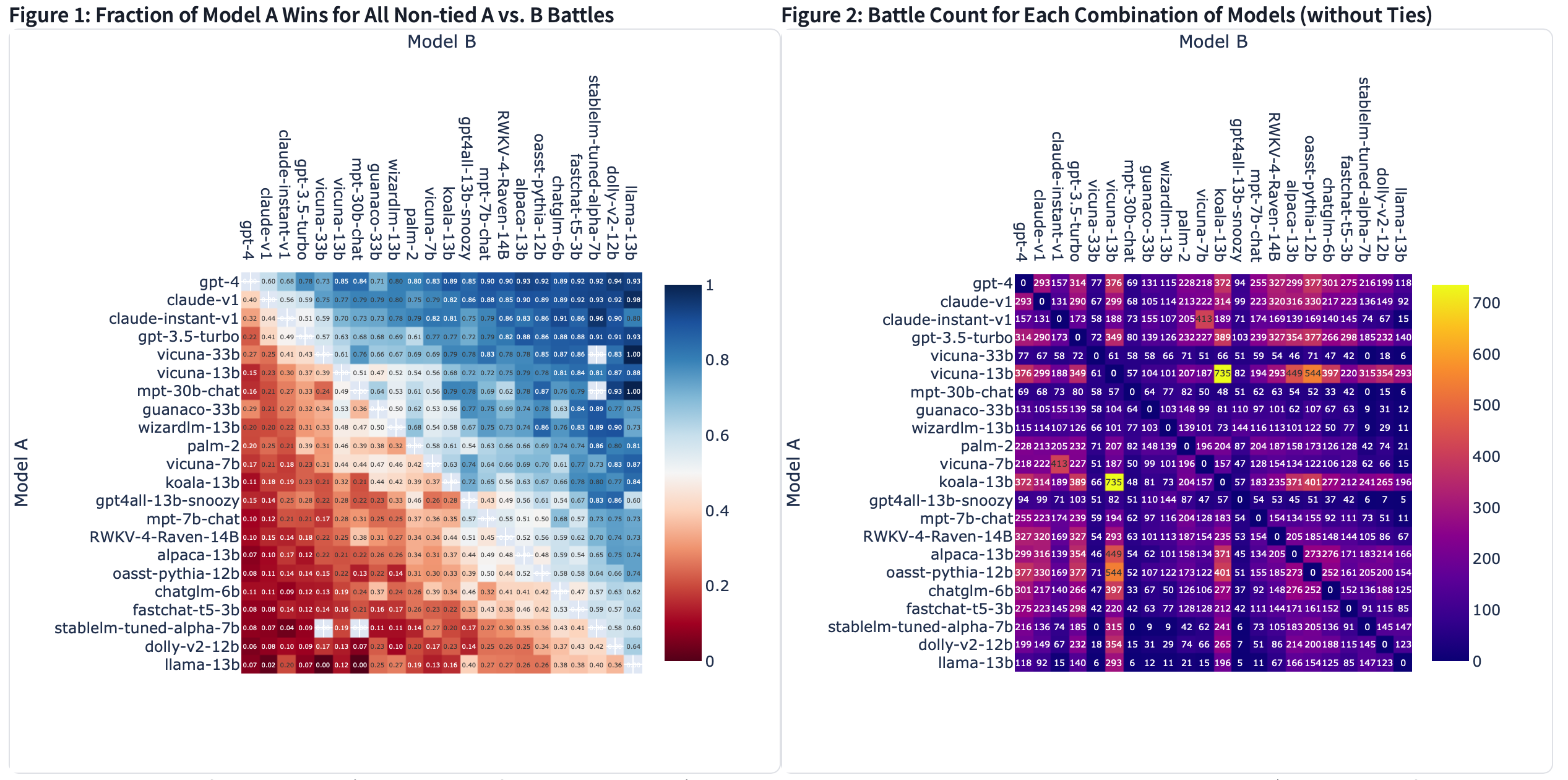
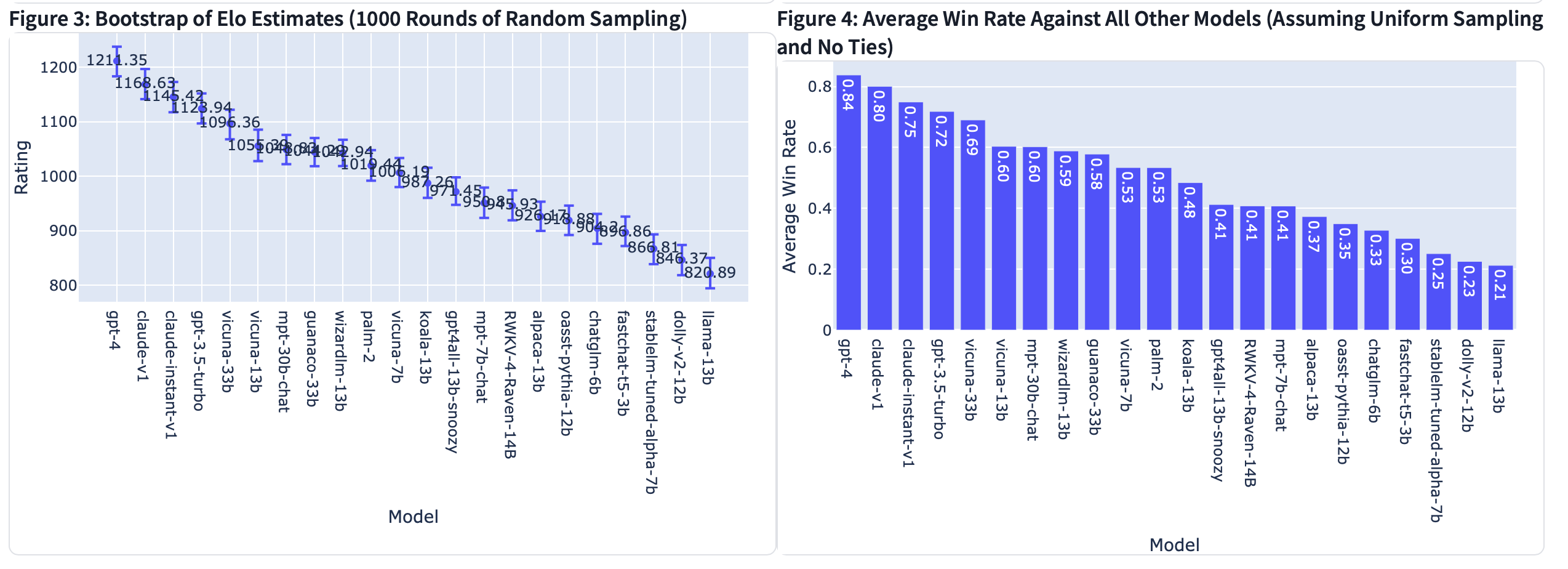
数据集1:33K聊天机器人竞技场对话数据
链接:lmsys/chatbot_arena_conversations
该数据集包含23年4月至6月在Chatbot Arena上收集的33000个已清理的对话,这些对话具有成对的人类偏好。每个示例包括两个模型名称、其完整的对话文本、用户投票、匿名用户ID、检测到的语言标签、OpenAI审核API标签、额外的有毒标签和时间戳。
为了确保数据的安全发布,我们试图删除所有包含个人身份信息(PII)的对话。此外,我们还包括了OpenAI审核API输出,以标记不适当的对话。然而,我们选择不删除所有这些对话,以便研究人员可以研究与野外LLM使用相关的安全相关问题以及OpenAI审核过程。例如,我们包括了由我们自己的有毒标记器生成的其他有毒标签,这些标签是通过在手动标记的数据上微调T5和RoBERTa来训练的。
数据集2:3K MT-bench人类注释
链接:lmsys/mt_bench_human_judgments
除了与Chatbot Arena进行众包评估外,我们还使用MT-bench进行了受控的人类评估。
该数据集包含3.3K专家级配对人类偏好,用于6个模型为响应80个MT工作台问题而生成的模型响应。6种型号是GPT-4、GPT-3.5、Claud-v1、Vicuna-13B、羊驼-13B和LLAMA-13B。注释员大多是在每个问题的主题领域具有专业知识的研究生。数据收集的细节可以在我们的论文中找到。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢