
初创公司Fable新发布的节目统筹智能体(Showrunner),如同一声惊雷炸响。
项目的灵感,就来自于此前斯坦福爆火的西部世界虚拟小镇论文,其中25个AI智能体居住在包含学校、医院、家庭的沙盒虚拟城镇中。
而在这次的《南方公园》中,同样是一群AI角色通过复杂的社交互动来推动自己的日常生活,每个人都有自己独特的背景故事、个性和动机。
 论文地址:https://fablestudio.github.io/showrunner-agents/
论文地址:https://fablestudio.github.io/showrunner-agents/
在多智能体无梯度架构的驱动下,每个角色的完整经历都会被存储为自然语言。随着时间的推移,这些记忆会被合成更高层次的反射,随时动态检索,来实时计划每个角色的行为。
其中,两个在《南方公园》数据集(约1200个角色和600张场景)上训练的自定义扩散模型,可以生成新角色和新场景,一个超分辨率模型(R-ESRGAN-4x+-Anime6B)可以将场景放大。语音克隆AI(如ElevenLabs),可以给角色即时配音。
英伟达首席AI科学家Jim Fan兴奋断言:多智能体模拟,将是新兴智能的下一个前沿!

Fable的研究者表示:所以单个AI Agent都会将失败,因为他们没有生命,无法共情——没有人会想当个缸中之脑,无休止地和人闲聊。
负责人介绍说,项目的目标一直都是AGI,只有AGI,才是真正活着的AI,AI聊天机器人还远远算不上。它们会在模拟世界中过着真实的日常生活,还会随着时间推移而不断成长。
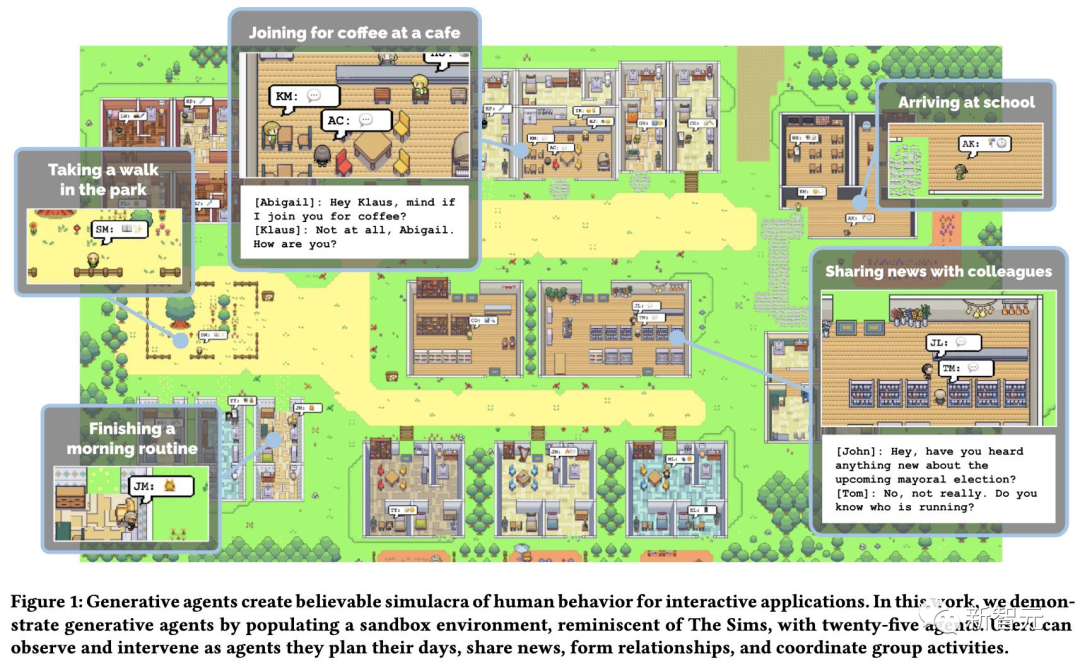
在这个虚拟世界中,我们可以观看AI的生活,就仿佛一场属于AI的真人秀。
在南方公园这个模拟小镇中,你可以用Showrunner制作自己的电视剧IP。
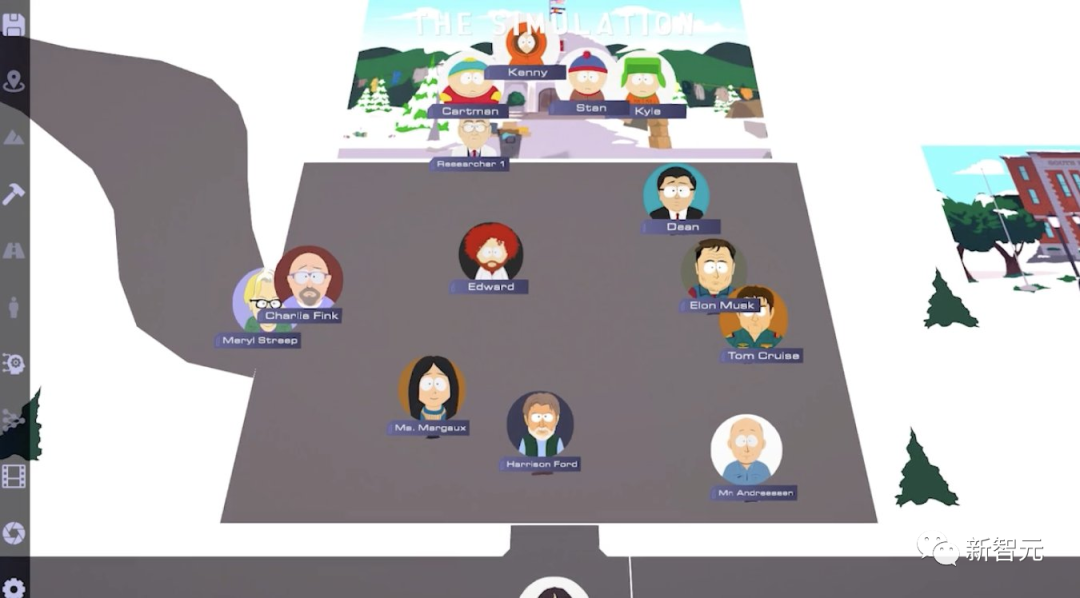
在整个过程中,你可以让智能体为你自动写剧本,还可以给Showrunner一两句话的prompt。
如果你希望深入地了解细节,就可以通过prompt逐个编辑每个场景的对话。
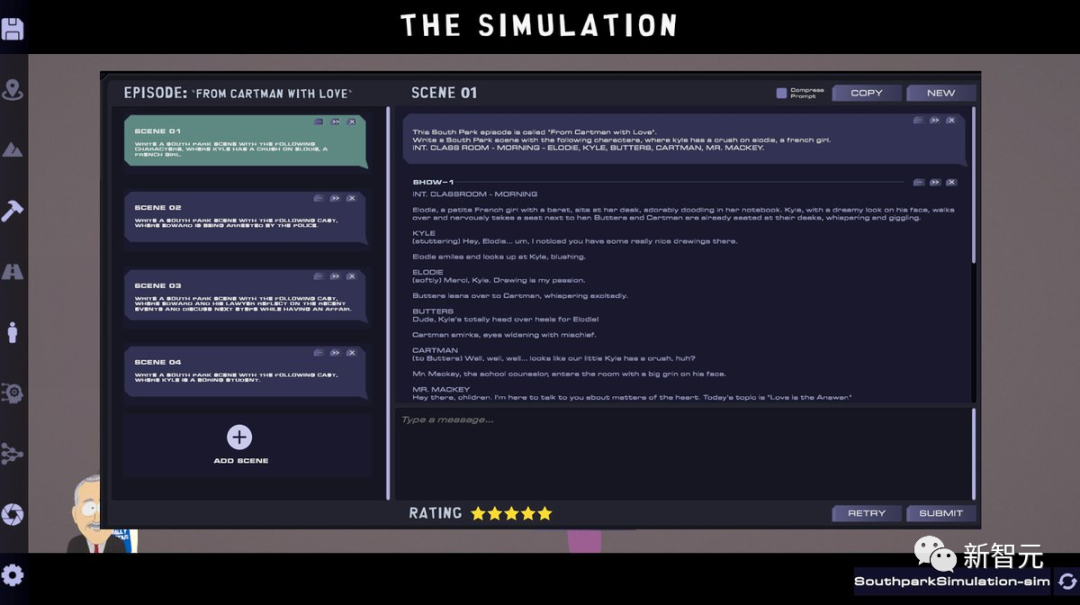
智能体写出的剧情,是什么水平?让我们来赏析一下。

在视频开头,会介绍一段Westland编年史。
一家邪恶的公司Bizney创造出一只机器猪作为人类的AI伴侣,这只机器猪有严重的种族主义倾向,使公司陷入了一场公关噩梦。

剧中的主人公发现,马斯克绑架了所有的好莱坞当红顶级演员,让他们来火星陪他一起生活。
而自90年代以来,我们见到的很多明星,比如汤姆克鲁斯和梅丽尔斯特里普,其实都是他们的DeepFake。

最有趣的是,考虑到网友们或许自己也想成为「剧中人」,所以Fable特意新建了一个上传功能,让用户可以上传自己的照片和声音,出现在节目中。
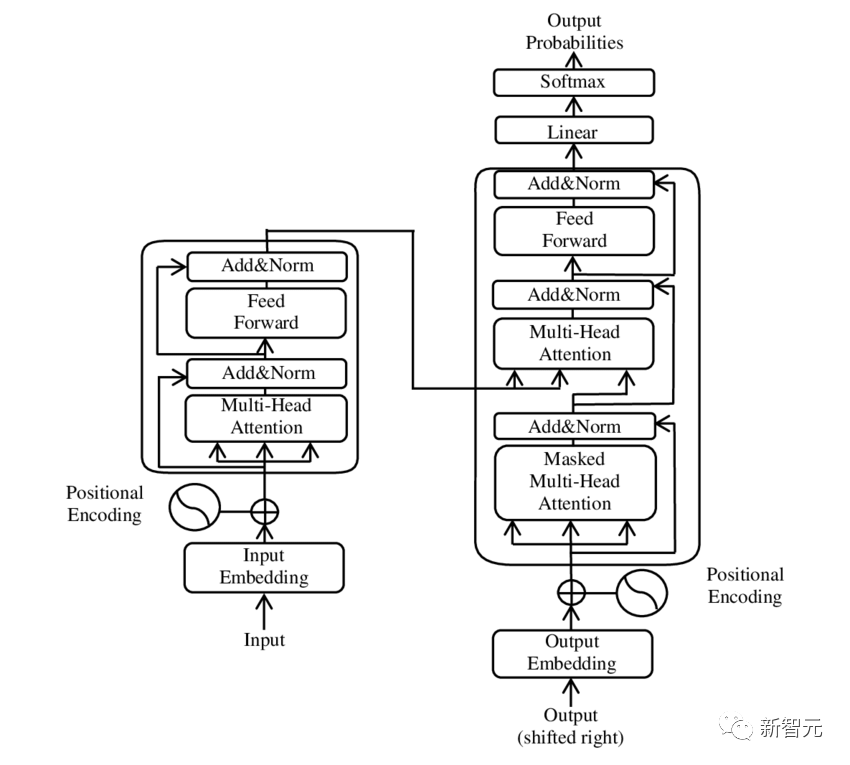
大语言模型
LLM通常基于Transformer架构构建,这类模型依赖于自注意力机制。Transformer能够高效利用计算资源,使得训练更大规模的语言模型成为可能。
例如,GPT-4包含数十亿个参数,在大规模数据集上训练,在其权重中有效编码了大量的世界知识。
向量嵌入(vector embeddings)的概念对这些大语言模型的运行机制至关重要。它们是将词或短语表示为高维空间中的数学表示。这些嵌入捕获了词之间的语义关系,语义相似的词在嵌入空间中位置邻近。
在大语言模型中,模型词汇表中的每个词起初都表示为一个稠密向量,也称为嵌入。这些向量在训练过程中被调整,它们的最终值或者说「嵌入」,表示了单词之间的学习关系。
在训练过程中,模型通过调整嵌入和其他参数来最小化预测词和实际词之间的差异,以预测句子中的下一个词。因此,嵌入反映了模型对词及其上下文的理解。

此外,由于Transformer可以关注句子中任意位置的词,模型可以形成对句子含义更全面的理解。这是对旧模型只能考虑有限窗口中的词的重大进步。
向量嵌入和Transformer体系结构的结合使得大语言模型可以更加深入细致地理解语言,这就是为什么这些模型可以生成如此高质量、类人的文本的原因。
如前所述,基于Transformer的语言模型擅长短期的一般任务。它们被视为是用快速思维的方式在运行。快速思维涉及本能、自动且通常基于启发式的决策,而慢思维涉及深思熟虑、分析和努力的过程。
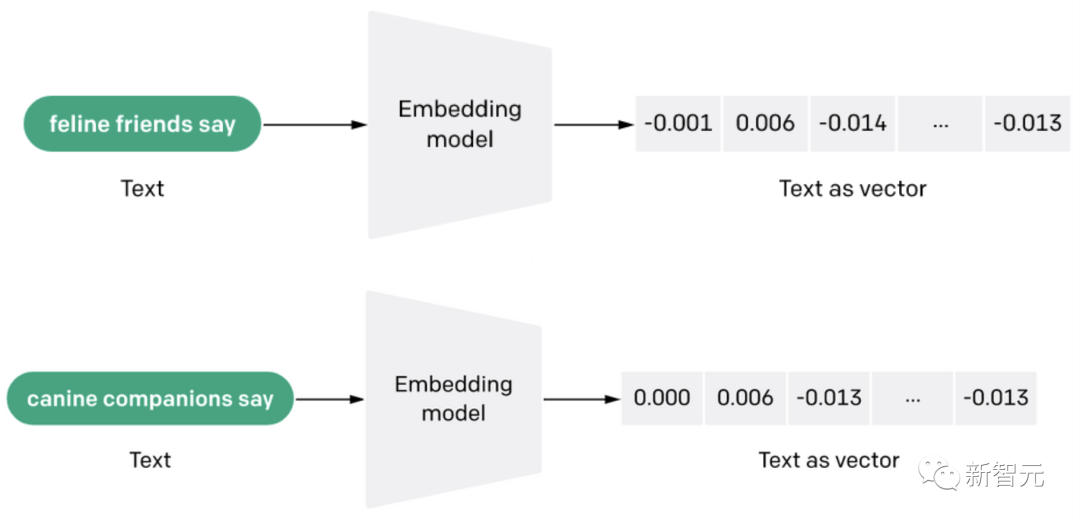
LLM根据从训练数据中学习的模式快速生成响应,而没有内省或理解其输出背后的底层逻辑的能力。这意味着大语言模型缺乏深思熟虑、深入推理或像人类那样从单一经验中学习的能力。
虽然这些模型在文本生成任务取得了显著的进步,但快速思维的特性可能会限制它们在需要深度理解或灵活推理的任务上的潜力。
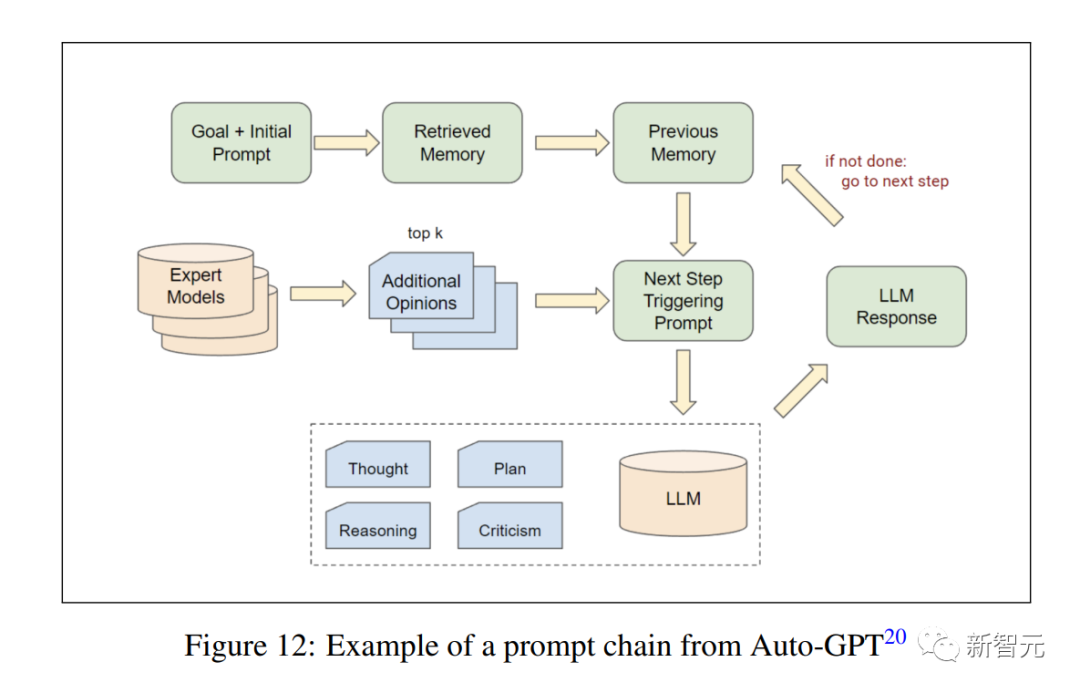
最近模仿慢思维能力的方法,如提示链工程(见Auto-GPT)就显示了很有前景的结果。
大语言模型可以在多步骤过程中充当自己的鉴别器。这能显著改善它在不同情境下的推理能力,例如解决数学问题。
在此项研究中,研究者大量使用GPT-4来影响模拟中的智能体,以及生成南方公园剧集的场景。

由于大多数南方公园剧集的转录是GPT-4训练数据集的一部分,它已经对角色的个性、谈话风格以及节目的整体幽默感有很好的把握,无需再进行定制微调。
而我们通过多步创作过程来模拟慢思维。为此,我们使用不同的提示链来比较和评估不同场景的事件,以及它们如何推动整个故事朝着令人满意的、与IP一致的结果发展。
我们尝试通过提示链生成剧集,但故事生成是一个高度不连续的任务。这些是内容创作无法以渐进或连续的方式完成,而是需要一个「恍然大悟」的想法,来解决任务的进展上一个不连续的飞跃。
内容生成涉及发现或发明一种看待或构建问题的新方法。这可以启用剩余内容的生成。
不连续任务的例子有,需要开创性的观点或创造性应用公式的数学问题,撰写笑话或谜语,想出科学假说或哲学论点,或开拓出一种新的写作流派或风格。
Diffusion模型的运作原理是随着时间的推移,逐渐从数据中添加或去除随机噪声,以生成或重构输出。图像开始作为随机噪声,经过许多步骤后逐渐变换成一个连贯的图片,反之亦然。

为了训练我们定制的Diffusion模型,我们收集了一个全面的数据集,包含来自动画剧《南方公园》约1200个角色和600个背景图像。这个数据集为模型学习该剧的风格提供了原始材料。
为了训练这些模型,我们使用了Dream Booth。此训练阶段的结果是创建了两个专门的Diffusion模型。
第一个模型专门用于生成单个角色,角色将会站在可抠背景颜色前。这有助于提取生成的角色进行后续处理和动画,使我们能够无缝地将新生成的角色集成到各种场景和设置中。

此外,角色的Diffusion模型允许用户通过Stable Diffusion的图片到图片过程,创建一个基于自己外观的南方公园角色,并作为平等参与的智能体加入模拟。
由于能够克隆自己的声音,可以轻松想象到一个基于用户外貌、书写风格和声音的完全实现的自主角色。

第二个模型经过训练可以生成干净的背景,而且能够特别聚焦于外部和内部环境。该模型提供了一个「舞台」,我们生成的角色可以在上面互动,从而可以创建各种潜在的场景和情景。

但需要注意的是,因为这些模型的产出是基于像素的性质,这些模型生成的图像在分辨率本质上是有限的。
为了克服这个限制,我们使用AI升级技术对生成的图像进行再处理,特别是R-ESRGAN-4x+-Anime6B,它可以优化和增强图像质量。

对于未来的2D交互作品,训练能生成基于矢量输出的定制Transformer模型将具有以下几个优势。
与基于像素的图像不同,矢量图形在调整大小或缩放时不会降低质量,因此可以提供无限分辨率的潜力。这将使我们能够生成无论以何种比例查看都能保持质量和细节的图像。

此外,基于矢量的形状已经分成单独的部分,解决了基于像素的具有透明度和分割的后处理问题。
这简化了生成资产集成到过程化世界的构建,以及动画系统中的复杂性。
我们将一集定义为在特定地点进行的一系列对话场景,一集南方公园的播放时间总共是22分钟。
为了生成一个完整的南方公园剧集,我们通常以标题、概要和我们希望在模拟虚拟世界的1周内(=大约3小时的播放时间)发生的主要事件的形式,向故事系统提供一个高层次的想法。
基于此,故事系统会自动使用模拟数据作为提示链的一部分,推断出多达14个场景。
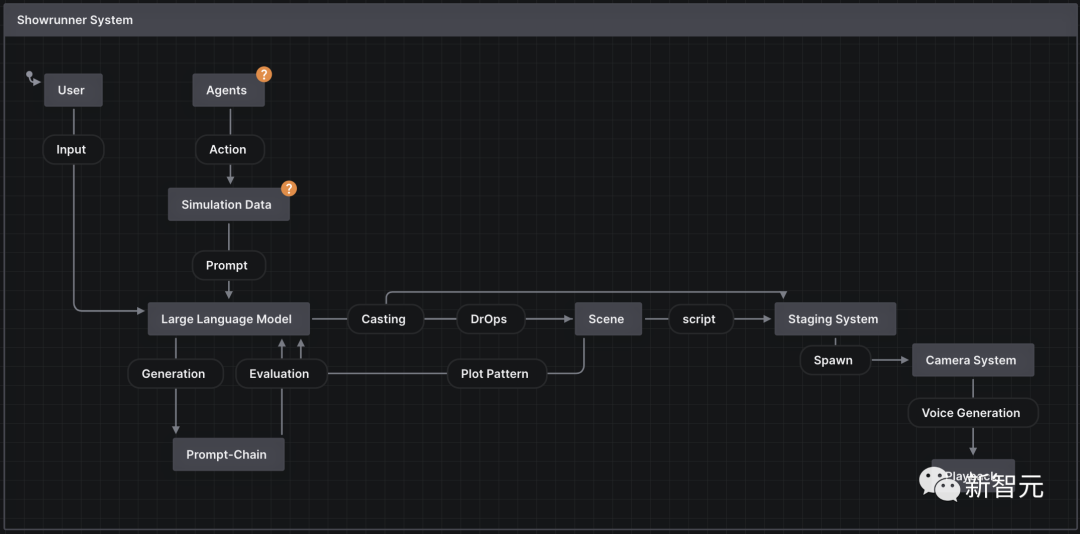
Showrunner系统负责为每个场景选派角色,以及故事应该如何通过情节模式进行。
每个场景都与一个情节字母(例如A,B,C)相关联,然后由Showrunner在一个剧集的过程中交替不同的角色组,并跟随他们的各自故事线,以保持用户的参与度。
最后,每个场景只定义了地点、角色和对话。在舞台系统和AI摄像系统进行初始设置后,根据情节模式(例如ABABC)回放场景。
每个角色的声音都已经提前克隆,并且每一条新的对话线都会即时生成语音剪辑。

如前所述,模拟产生的数据,既为撰写初始提示的用户,也为与LLM进行提示链交互的生成故事系统,提供了创新的燃料。
提示链是一种技术,它通过向语言模型提供一系列相关的提示,来模拟持续的思维过程。有时,它可以在每一步中扮演不同的角色,对前一个提示和生成的结果进行判别。
在这个例子中,我们会模仿一个非连续的创造性思维过程。
例如,要创建14个不同的《南方公园》场景,可以先提供一个概括性的提示,勾勒出总体叙事,然后再提供具体的提示,详细说明和评估每个场景的演员、地点和关键情节。
谁在推动这个故事?
参考资料:
https://fablestudio.github.io/showrunner-agents/?mc_cid=f9d1eb56dc&mc_eid=bbcd57583d
https://twitter.com/fablesimulation/status/1681352904152850437
https://twitter.com/DrJimFan/status/1682086586593443841
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢