

杜克-新加坡国立大学医学院(Duke-NUS Medical School) Daniel Shu Wei Ting等研究人员近日在nature medicine发表综述,阐述了大语言模型(Large language models (LLMs))在医学领域的潜在应用[1]。
作者们从大语言模型开发历史、现状出发,以ChatGPT为代表阐释了在医学等领域表现优异的大语言模型的训练以及fine-tuning过程;并剖析其医学应用存在的信息不准确、不及时、不一致、不透明(缺乏来源解释)以及伦理相关问题,并展望潜在缓解这些问题的进一步开发方案[1]–[3]。
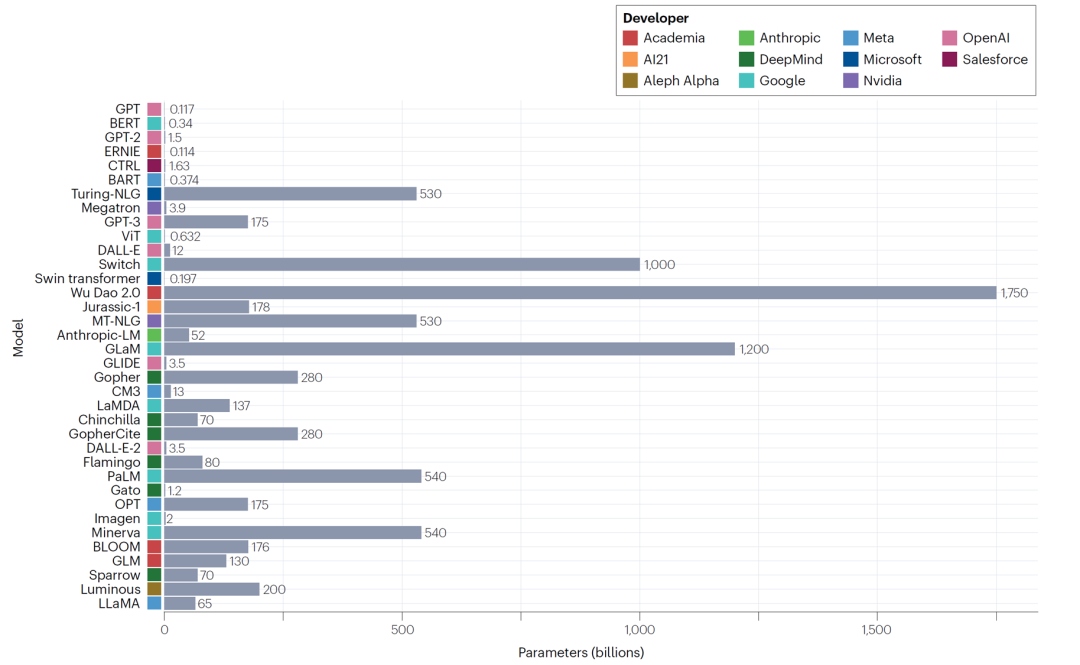
近来开发的大语言模型概览[1]
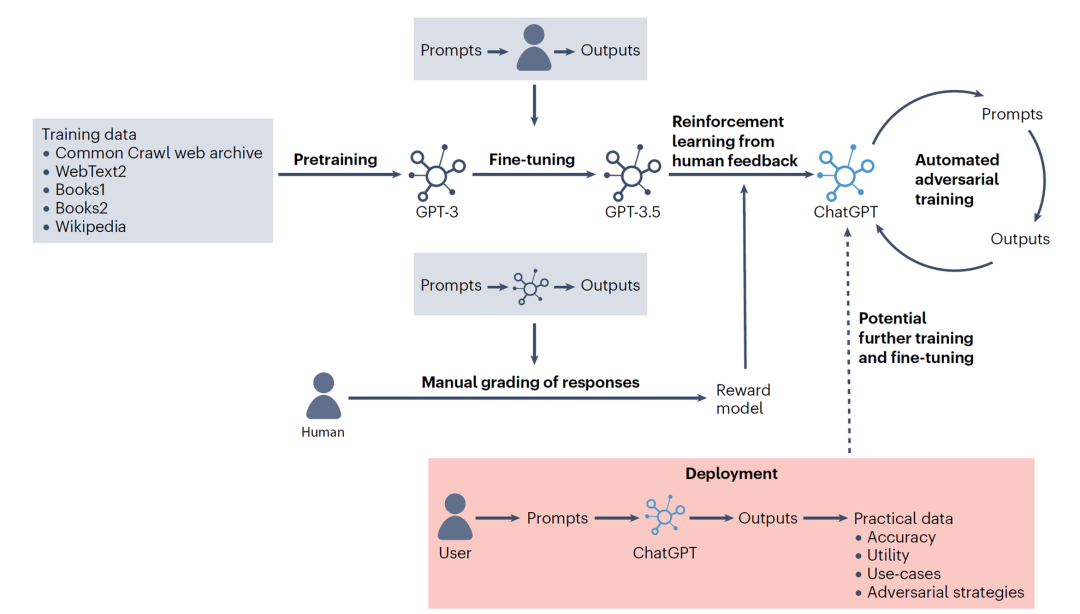
ChatGPT的 “诞生”[1]
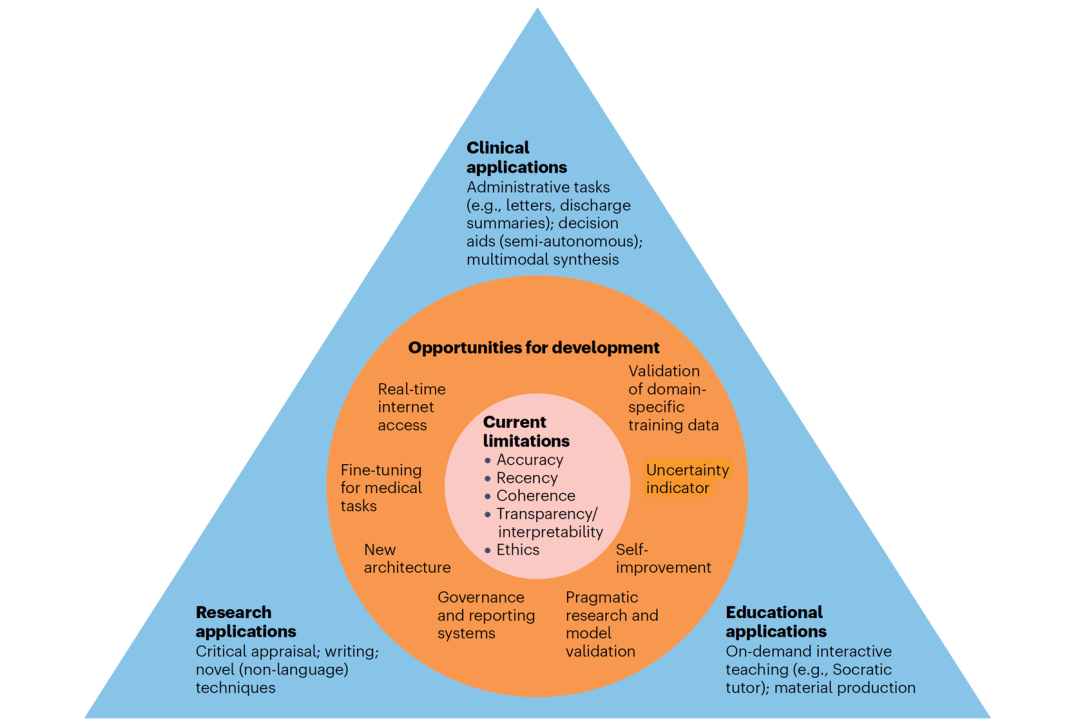
大语言模型医学应用的局限,进一步开发机遇及潜在应用场景[1]
该项工作2023年7月17日发表在nature medicine;作者们进一步提出需要务实的对照试验来分析在医学领域引入大语言模型工具对医疗质量/效率的影响[1]。
Comment(s):
系统、涵盖面广且富有见解的综述。
LLMs医学应用的随机对照试验确实是很切实很重要的后续工作;MIT Shakked Noy等对ChatGPT提高写作生产力的对照试验(Science | 对照试验解析ChatGPT如何提高生产力)可以做重要参考[4];但是需要关注衡量指标的选择,以及考虑工具迭代的影响。
通讯作者简介:
 https://scholar.google.com/citations?user=CrPNLmIAAAAJ
https://scholar.google.com/citations?user=CrPNLmIAAAAJ
参考文献:
[1] A. J. Thirunavukarasu, D. S. J. Ting, K. Elangovan, L. Gutierrez, T. F. Tan, and D. S. W. Ting, “Large language models in medicine,” Nat. Med., no. March, 2023, doi: 10.1038/s41591-023-02448-8.
[2] Y. Shao et al., “Hybrid Value-Aware Transformer Architecture for Joint Learning from Longitudinal and Non-Longitudinal Clinical Data,” J. Pers. Med., vol. 13, no. 7, p. 1070, 2023, doi: 10.3390/jpm13071070.
[3] A. Glaese et al., “Improving alignment of dialogue agents via targeted human judgements,” pp. 1–77, 2022, [Online]. Available: http://arxiv.org/abs/2209.14375
[4] S. Noy and W. Zhang, “Experimental evidence on the productivity effects of generative artificial intelligence,” Science (80-. )., vol. 381, no. 6654, pp. 187–192, Jul. 2023, doi: 10.1126/science.adh2586.
原文链接:
https://www.nature.com/articles/s41591-023-02448-8
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢