
【论文标题】Text Classification Using Label Names Only: A Language Model Self-Training Approach 【作者团队】Yu Meng, Yunyi Zhang, Jiaxin Huang, Chenyan Xiong, Heng Ji, Chao Zhang, Jiawei Han 【发表时间】2020/10/14 【论文链接】https://arxiv.org/pdf/2010.07245.pdf 【代码链接】https://github.com/yumeng5/LOTClass
【推荐理由】本文来自UIUC韩家炜老师组,已发表于EMNLP2020。文章提出了一种基于预训练语言模型的弱监督文本分类模型,标签的名称信息是该模型唯一需要使用的监督信息。
当前的文本分类方法通常需要大量带标签的数据作为训练数据,在实际应用中通常难以满足。而在实际生活中,人们可以只通过基于描述待分类类别的少量单词执行分类,而不需看到完整带标签的示例。基于这个动机,文章研究了在纯无标签数据上只提供每个类的标签名称来训练分类器的弱监督文本分类问题。作者使用经过预训练的神经语言模型,既作为用于类别理解的通用语言知识来源,又作为文档分类的表示学习模型。
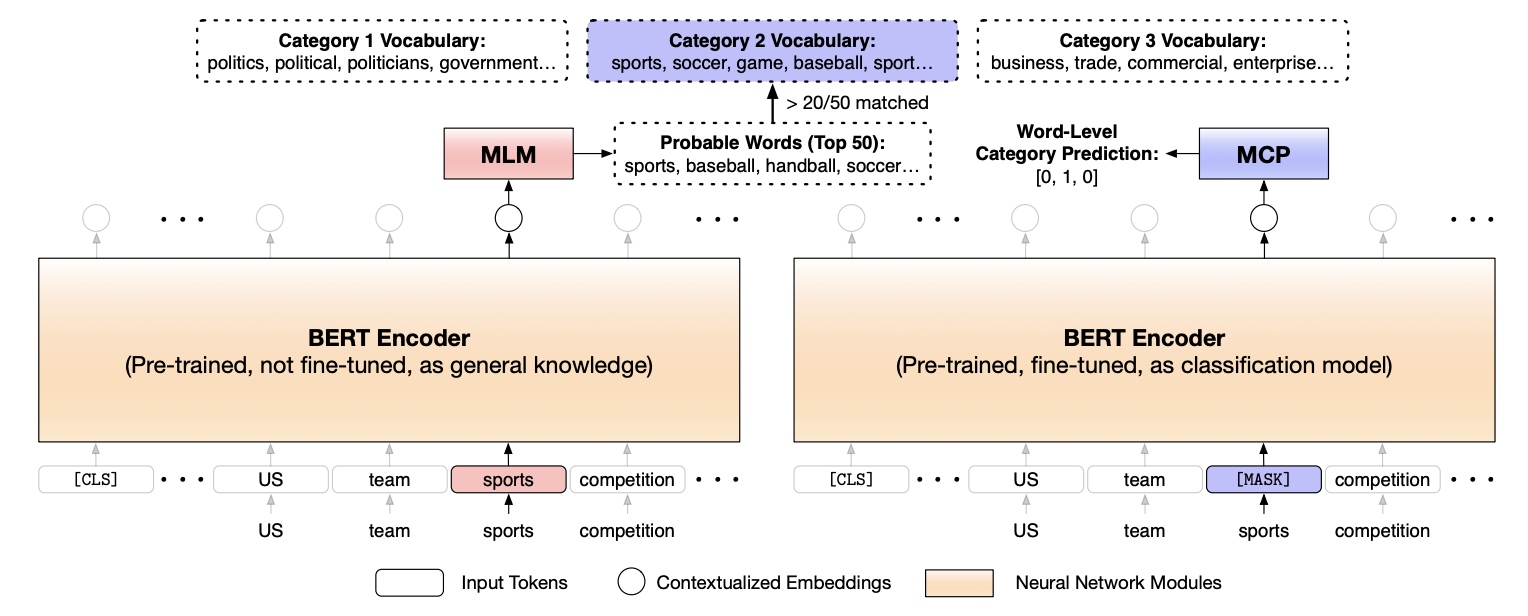
文章提出的仅用于标签名称的文本分类的LOTClass模型,该模型分三步构建:(1)首先使用预先训练的LM为每个类别构建一个类别词汇表,该类别词汇表包含与标签名称具有语义相关的单词。 (2)LM在未标记的语料库中收集高质量的类别指示词,以通过语境化的词级类别预测任务来训练自己,以捕获类别区别信息。(3)最后通过对大量未标记数据进行文档级自我训练来概括LM。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢