
Human-Timescale Adaptation in an Open-Ended Task Space
Adaptive Agent Team, Jakob Bauer, Kate Baumli, Satinder Baveja, Feryal Behbahani, Avishkar Bhoopchand, Nathalie Bradley-Schmieg, Michael Chang, Natalie Clay, Adrian Collister, Vibhavari Dasagi, Lucy Gonzalez, Karol Gregor, Edward Hughes, Sheleem Kashem, Maria Loks-Thompson, Hannah Openshaw, Jack Parker-Holder, Shreya Pathak, Nicolas Perez-Nieves, Nemanja Rakicevic, Tim Rocktäschel, Yannick Schroecker, Jakub Sygnowski, Karl Tuyls, Sarah York, Alexander Zacherl, Lei Zhang
[DeepMind]
开放式任务空间中的人-时间尺度自适应
-
提出AdA,一种能在一系列具有挑战性的任务中进行人-时间尺度自适应的智能体; -
在具有自动化课程的开放式任务空间中使用元强化学习大规模训练 AdA; -
表明自适应受到记忆架构、课程以及训练任务分布的规模和复杂性的影响。
提出 AdA,一个强化学习智能体,能以类似于人的时间尺度,基于用元强化学习、自动化课程和基于注意力的记忆架构,在广阔的开放式任务空间中实现快速的上下文自适应。
基础模型在监督和自监督学习问题上表现出令人印象深刻的自适应性和可扩展性,但到目前为止,这些成功尚未完全迁移到强化学习(RL)。本文证明了大规模训练强化学习智能体,会导致一种通用的上下文学习算法,该算法可以像人一样快速自适应开放式新3D问题。在广阔的固定环境动力学空间中,所提出的自适应智能体(AdA)展示出实时假设驱动的探索,对获得的知识的有效利用,可通过第一人称演示成功进行提示。其自适应源于三个要素:(1) 跨越广泛、流畅和多样化的任务分布的元强化学习,(2) 参数化为大规模基于注意力记忆架构的策略,以及 (3) 有效的自动化课程,优先考虑智能体能力前沿的任务。演示了有关网络大小、记忆长度和训练任务分布丰富性的特征缩放律。本文结果为越来越通用和自适应的R强化学习智能体奠定了基础,这些智能体在越来越大的开放域中表现良好。
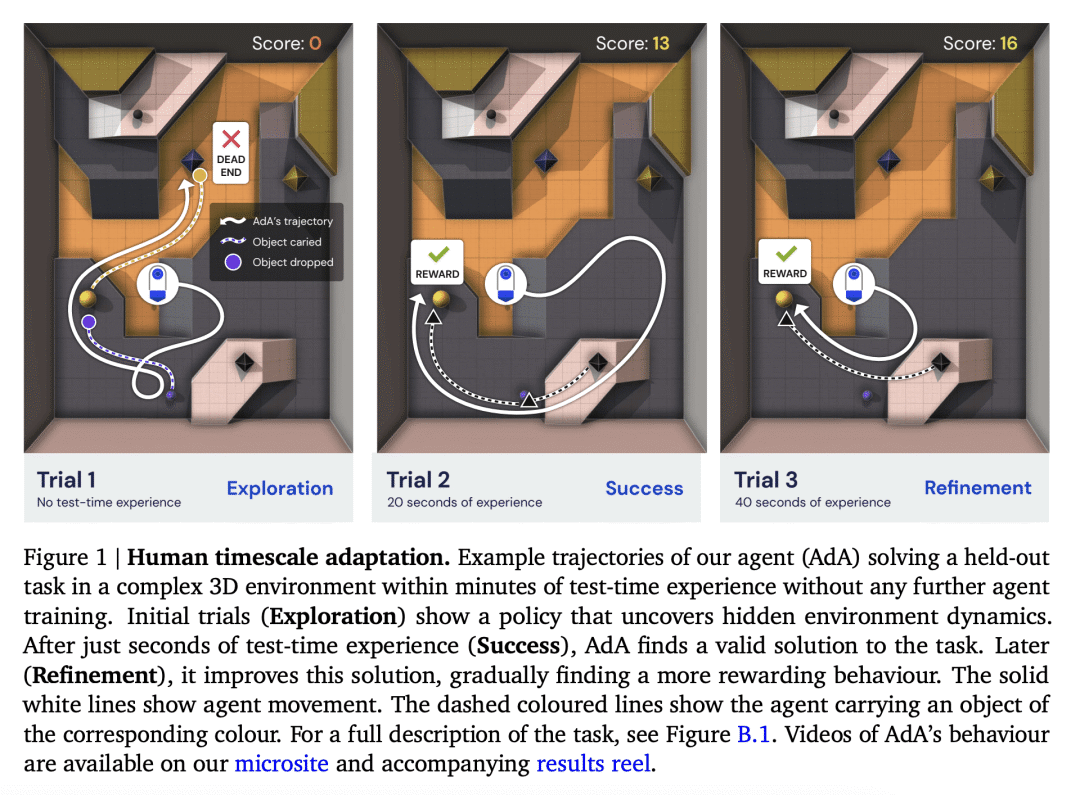
在几分钟内适应的能力是人类智能的一个决定性特征,也是通向通用智能道路上的一个重要里程碑。 给定任何级别的有限理性,都会有一个任务空间,在这个任务空间中,智能体不可能仅通过概括其策略零样本来取得成功,但是如果代理能够从反馈中非常快速地进行上下文学习,那么进展是可能的。 为了在现实世界中以及与人类的互动中发挥作用,我们的人工智能体应该能够在仅进行少量互动的情况下进行快速灵活的适应,并且应该随着更多数据的可用而继续适应。 为了使这种适应概念实用化,我们试图训练一个代理人,在测试时在一个看不见的环境中给定几个情节,可以完成一项需要反复试验探索的任务,然后可以改进其解决方案以实现最佳行为。
Meta-RL 已被证明对快速的上下文适应有效(例如 Yu 等人 (2020);Zintgraf (2022))。 然而,元强化学习在奖励稀疏且任务空间广阔且多样化的环境中取得的成功有限(Yang 等人,2019 年)。 在 RL 之外,半监督学习中的基础模型引起了极大的兴趣(Bommasani 等人,2021 年),因为它们能够适应广泛任务中演示的少量镜头。 这些模型旨在提供坚实的常识和技能基础,可以通过微调或演示提示来建立和适应新情况(Brown 等人,2020 年)。 这一成功的关键是基于注意力的内存架构,如 Transformers(Vaswani 等人,2017 年),它显示了性能随参数数量的幂律缩放(Tay 等人,2022 年)。
在这项工作中,我们为训练 RL 基础模型铺平了道路; 也就是说,一个代理已经在大量任务分布上进行了预训练,并且在测试时可以使少量镜头适应广泛的下游任务。 我们介绍了自适应代理 (AdA),这是一种能够在具有稀疏奖励的巨大开放式任务空间中进行人类时间尺度适应的代理。 AdA 不需要任何提示(Reed 等人,2022 年)、微调(Lee 等人,2022 年)或访问离线数据集(Laskin 等人,2022 年;Reed 等人,2022 年)。 相反,AdA 表现出假设驱动的探索行为,使用即时获得的信息来改进其策略并实现接近最佳的性能。 AdA 有效地获取知识,在几分钟内适应具有挑战性的稀疏奖励任务,==在具有第一人称像素观察的部分可观察的 3D 环境中。 一项人类研究证实,AdA 适应的时间尺度与受过训练的人类玩家相当。 AdA 在具有代表性的保留任务中的适应行为,AdA 还可以通过第一人称演示的零样本提示来提高性能,类似于语言领域的基础模型。

Adaptive Agent (AdA)
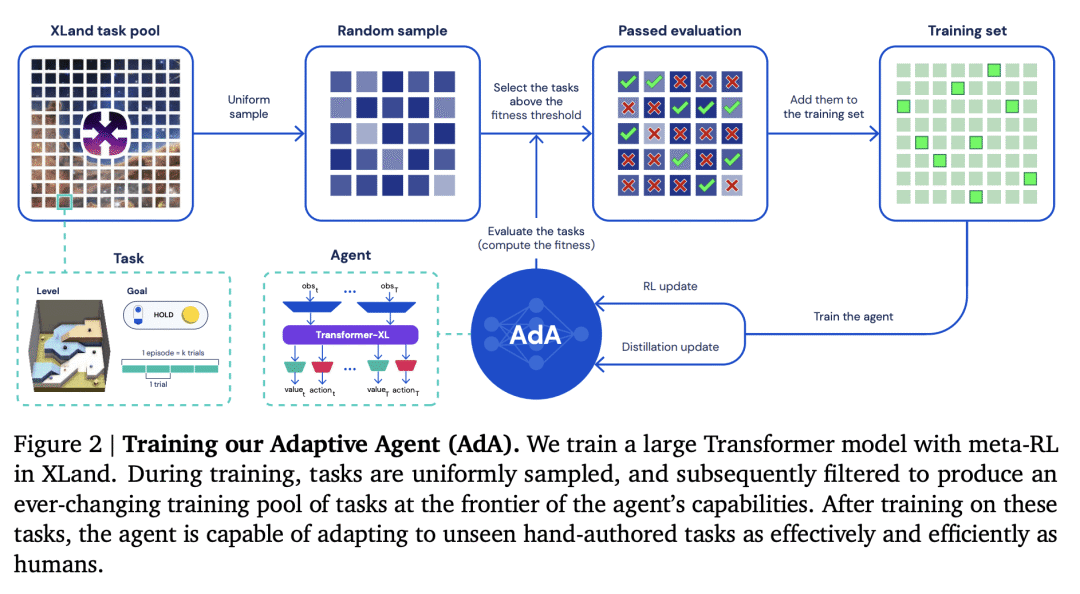
为了在广阔而多样的任务空间中实现人类时间尺度适应,我们提出了一种通用且可扩展的基于内存的元 RL 方法,生成自适应代理 (AdA)。 我们在 XLand 2.0 中训练和测试 AdA,这是一个支持程序生成多样化 3D 世界和多人游戏的环境,具有需要适应的丰富动态。 我们的训练方法结合了三个关键组成部分:指导代理学习的课程、基于模型的 RL 算法来训练具有大规模基于注意力的记忆的代理,以及蒸馏以实现扩展。
部分内容来自Wwwilling
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢