
Making Metadata More FAIR Using Large Language Models
Sowmya S. Sundaram, Mark A. Musen
[Stanford University]
用大型语言模型改进元数据质量
-
动机:随着全球实验数据成品的增加,以统一方式利用它们遇到的主要障碍是糟糕的元数据。
-
方法:提出一个自然语言处理(NLP)信息化的应用,FAIRMetaText,用来比较元数据。具体来说,FAIRMetaText分析元数据的自然语言描述,并提供了两个术语之间的数学相似性度量。
-
优势:所提出算法在公开可用的研究成果上定性和定量地展示了其效果,证明了通过深入研究各种大型语言模型,可以在与元数据相关的任务中取得大幅度的提升。
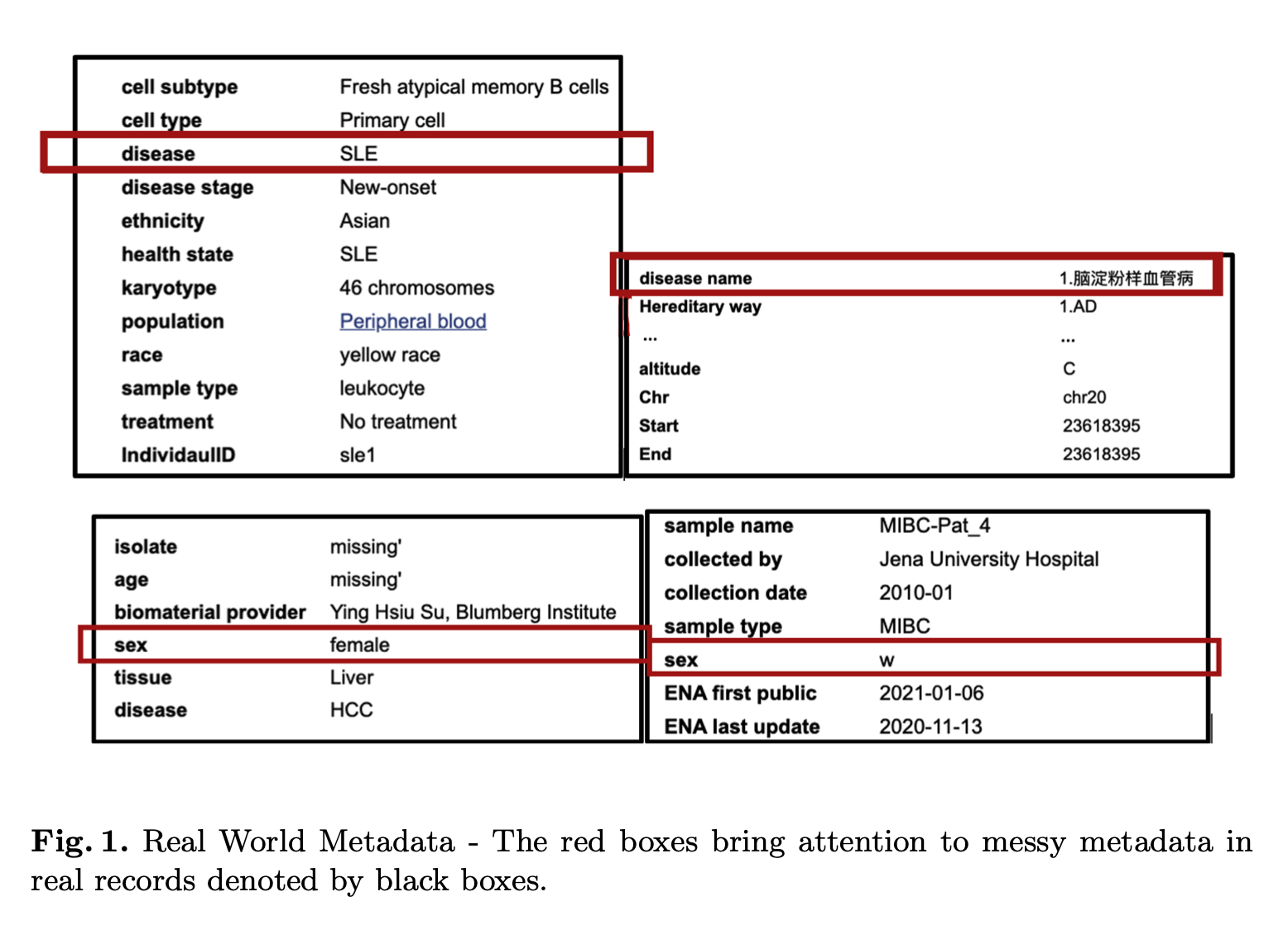
提出FAIRMetaText,一个自然语言处理应用,通过分析元数据的自然语言描述,为两个术语之间的数学相似性度量提供工具,有效地解决了元数据质量问题。
论文:https://arxiv.org/abs/2307.13085
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢