

谷歌DeepMind带着全新的模型杀回来了!视觉-语言-动作模型(VLM)即将取代类似ChatGPT的大语言模型。
谷歌DeepMind推出的「视觉-语言-动作」(vision-language-action,VLA)模型!
论文地址:https://robotics-transformer2.github.io/assets/rt2.pdf
根据谷歌内部披露,VLA模型已经接入到机器人身上,能够和现实世界进行互动了!
这个机器人被谷歌命名为Robotic Transformer 2 (RT-2) ,它能够从网络、机器人的数据中学习,还能将这些知识自主转化为有效的指令。
简单来说,你只需要对RT-2画个饼,之后就可以等着RT-2把饼喂到你嘴边了。

谷歌DeepMind负责人表示,长期以来,计算机在分析数据等复杂任务方面表现出色,但在识别和移动物体等简单任务方面却不尽如人意。通过 RT-2,我们正在缩小这一差距,帮助机器人解读世界并与之互动,让其对人类更加有用。但俗话说,一口吃不成个大胖子,在RT-2成为RT-2之前,它的前辈Robotic Transformer 1 (RT-1)为RT-2打下了坚实的基础。
RT-1升级RT-2,VLM到VLA
RT-1是一种多任务模型,基于Transformer构建,能够将图像、自然语言指令等作为输入,并直接输出标记化动作。
RT-1 的架构:该模型采用文本指令和图像集作为输入,通过预先训练的 FiLM EfficientNet 模型将它们编码为token,并通过 TokenLearner 压缩它们。然后将这些输入到 Transformer 中,Transformer 输出操作token
因此,与一般机器相比,RT-1具有更好的性能和泛化能力。
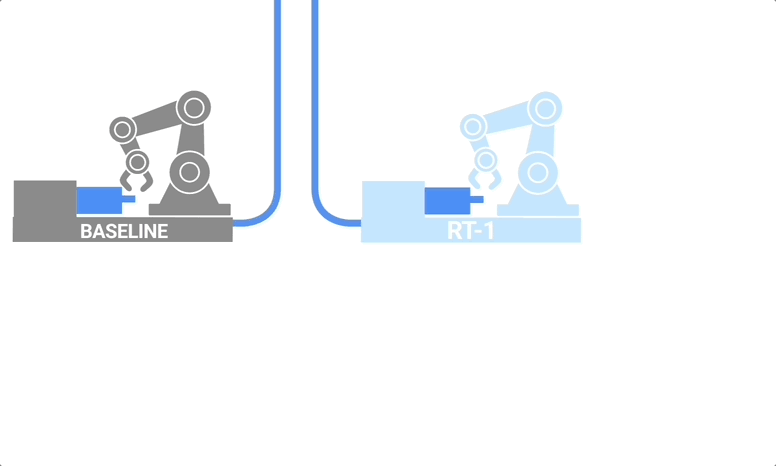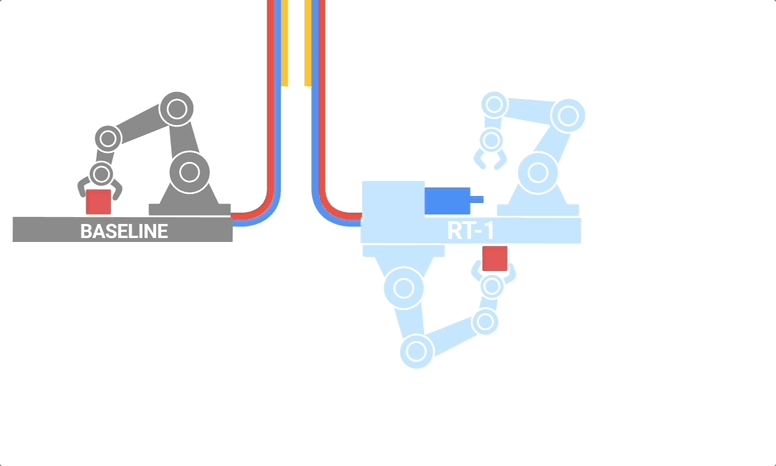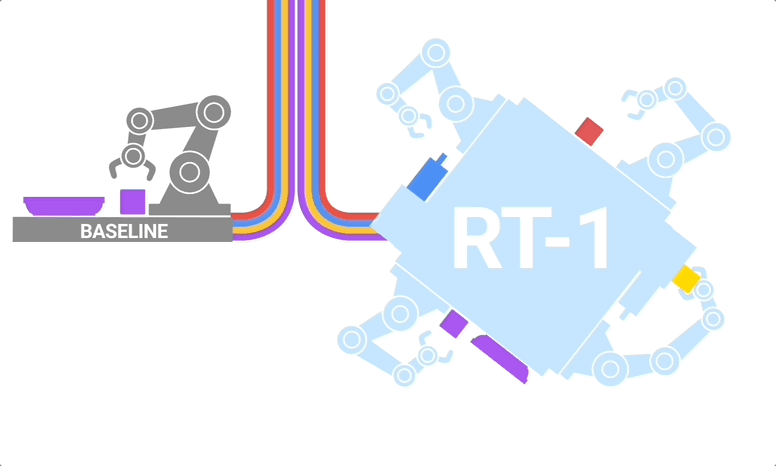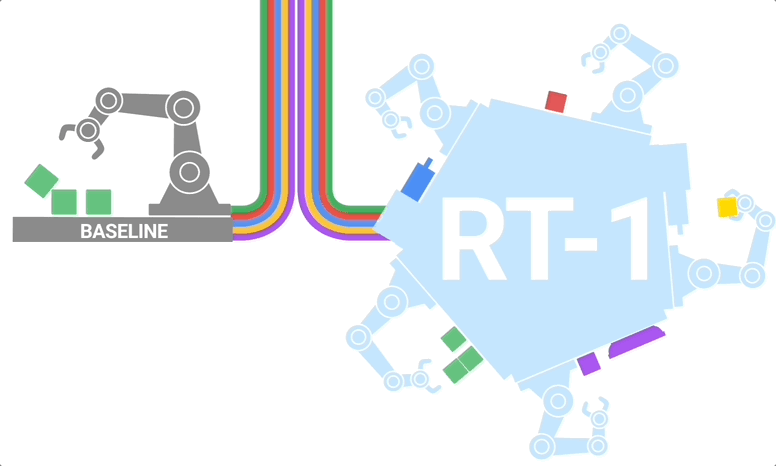
其中,RT-1所搭载的视觉语言模型(vision-language models ,VLMs)扮演了关键角色。
VLM在互联网级的数据集上进行训练,因此在识别视觉、语言和跨语言合作这块具有极高水平。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢