这是一篇关于评估大型语言模型的研究,文中参考了许多重要文献,值得一读。
大型语言模型(LLM)已经得到了学术界和产业界的广泛关注,而为了开发出好用的 LLM,适当的评估方法必不可少。现在,一篇有关 LLM 评估的综述论文终于来了!其中分三方面对 LLM 评估的相关研究工作进行了全面的总结,可帮助相关研究者索引和参考。

对科学家来说,理解智能的本质以及确定机器是否能具有智能是极具吸引力的课题。人们普遍认为,人类之所以有能力执行推理、检验假设以及为未来做准备,就是因为我们具有真正的智能。人工智能研究者关注的是开发基于机器的智能。正确的度量方式有助于理解智能。举个例子,为了测试人类的智能水平 / 智力,常常会用到 IQ 测试。
而在 AI 领域,AI 开发的一个长期目标是让 AI 通过图灵测试(Turing Test),这需要一个能被广泛认可的测试集,通过辨别 AI 和人类对其的响应来评估 AI 的智能水平。研究者普遍相信,如果计算机能成功通过图灵测试,那么就可以认为它具有智能。因此,从更广泛的视角看,AI 的编年史可描述为智能模型和算法的创造和评估的时间线。每当出现一个新的 AI 模型或算法,研究者都会使用有难度的特定任务来仔细评估其在真实世界场景中的能力。
举个例子,曾在上世纪 50 年代被吹捧为通用人工智能(AGI)方法的感知器算法之后被证明名不符实,因为其难以求解 XOR(异或)问题。之后兴起并得到应用的支持向量机(SVM)和深度学习都是 AI 发展图景中的重大里程碑,但它们也都各有短板。
过去的研究历程向我们揭示了评估的重要性。评估是一种重要工具,能帮助我们识别当前系统的局限性并让我们获得设计更强模型的信息。
目前而言,学术界和产业界最感兴趣的技术方法是大型语言模型(LLM)。已有的研究表明:LLM 表现优异,已经成为 AGI 的有力候选。相比于之前受限于特定任务的模型,LLM 有能力解决多种不同任务。由于 LLM 既能应对一般性自然语言任务,又能处理特定领域的任务,因此越来越受有特定信息需求的人的欢迎,比如学生和病人。
首先,评估 LLM 有助于我们更好地了解 LLM 的优势和劣势。举个例子,PromptBench 基准测试表明,当前的 LLM 对对抗性 prompt 很敏感,因此为了更好的性能,必需仔细设计 prompt。
第二,更好的评估可以为人类与 LLM 的交互提供更好的指引,这能为未来的交互设计和实现提供思路。
第三,LLM 由于广泛适用于多种任务,因此确保其安全性和可靠性就至关重要了,尤其是在金融和医疗等行业。
最后,随着 LLM 能力增多,其也在越来越大,因此现有的评估方法可能不足以评估它们的能力和潜在风险。这就引出了这篇综述论文的目标:让 AI 社区认识到 LLM 评估的重要性并指引有关 LLM 评估协议的未来新研究。
随着 ChatGPT 和 GPT-4 的推出,已经出现了一些旨在从不同方面评估 ChatGPT 和其它 LLM 的研究工作(图 2),其中涵盖很多因素,包括自然语言任务、推理、稳健性、可信度、医学应用和道德考量。尽管如此,仍然缺乏一篇涵盖整个评估图景的全面综述。此外,LLM 的持续演进还会引入需要评估的新方面,这会给现有评估带来困难,并由此更加需要彻底的和多方面的评估技术。尽管有一些研究工作宣传 GPT-4 可以被视为 AGI 的星星之火,但另一些人则反对这个说法,因为 GPT-4 的评估方法本质上还是启发式的。
这篇来自吉林大学、微软亚洲研究院和卡内基・梅隆大学等机构论文对大型语言模型评估进行了全面综述。如图 1 所示,作者从三个维度对现有研究工作进行了探索:1) 评估什么,2) 何处评估,3) 如何评估。

具体来说,「评估什么」涵盖 LLM 现有的评估任务,「何处评估」涉及对所用的数据集和基准的适当选择,「如何评估」关注的是给定任务和数据集下的评估过程。这三个维度是 LLM 评估不可或缺的一部分。之后,作者还会讨论 LLM 评估领域潜在的未来挑战。
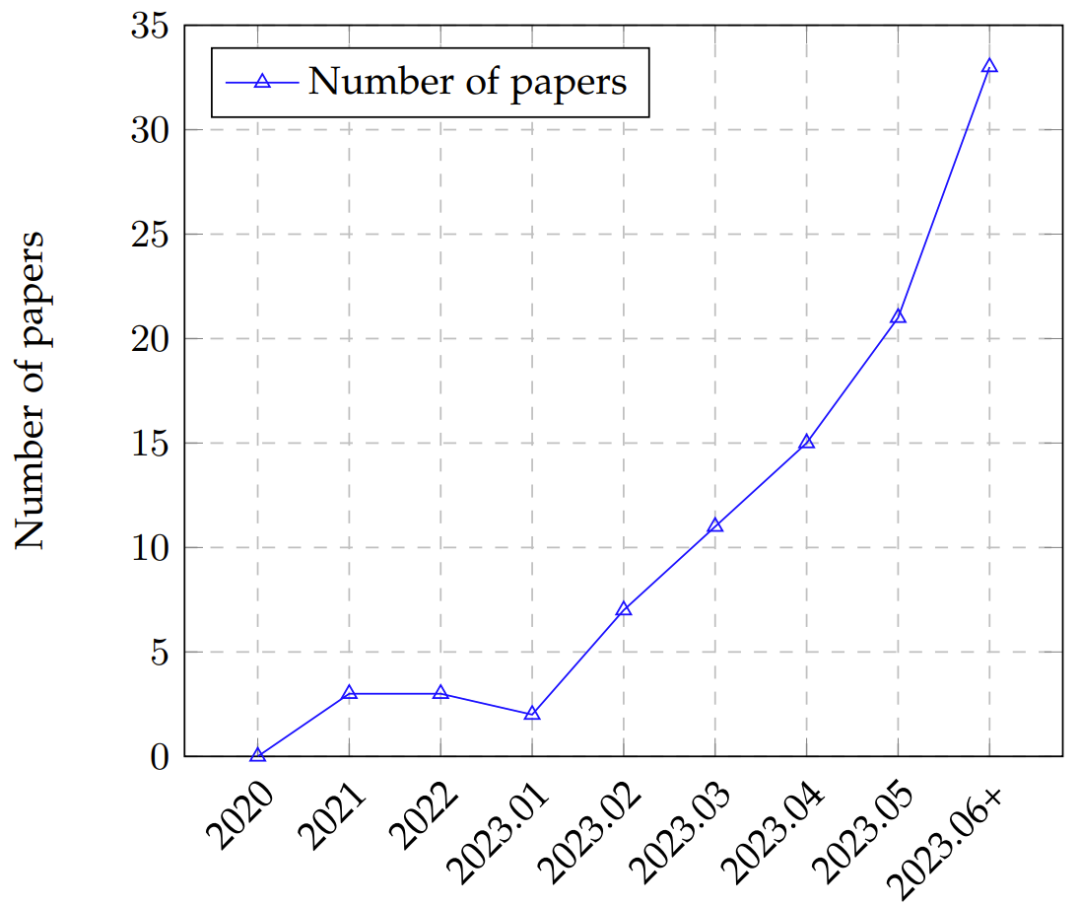
图 2:LLM 评估论文随时间的趋势,从 2020 年到 2023 年 6 月(6 月数据包含 7 月的部分论文)
-
本文从三方面全面地概述了 LLM 评估:评估什么、何处评估、如何评估。其中采用的分类方法是普适的并且涵盖 LLM 评估的整个生命周期。
-
在「评估什么」方面,本文总结了多个领域的现有任务,并得到了有关 LLM 的成功和失败案例的富有洞见的结论。
-
在「何处评估」方面,本文对评估指标、数据集和基准进行了总结,可帮助读者透彻地理解 LLM 评估的当前图景。在「如何评估」方面,本文探索了当前协议并总结了新的评估方法。
-
本文还进一步讨论了评估 LLM 方面的未来挑战。为了促进构建一个有关 LLM 评估的合作社区,作者还维护着一个 LLM 评估相关材料的资源库并已开源:https://github.com/MLGroupJLU/LLM-eval-survey
GPT-3、InstructGPT 和 GPT-4 等许多 LLM 背后的核心模块是 Transformer 中的自注意力模块,Transformer 则是语言建模任务的基本构建模块。Transformer 已经为 NLP 领域带来了变革,因为其能高效处理序列数据、支持并行化并能捕获文本中的长程依赖关系。
LLM 的一大关键特性是上下文学习,即模型可被训练基于给定的上下文或 prompt 生成文本。这让 LLM 可以生成更为连贯且更长上下文相关的响应,从而让它们更适用于交互式和会话应用。
根据人类反馈的强化学习(RLHF)是 LLM 的另一重要方面。该技术是使用人类生成的响应作为奖励对模型进行微调,从而让模型可以学习自身的错误并随时间提升性能。
AI 模型评估是评估模型性能的重要步骤。目前已有一些标准模型评估协议,包括 K-fold 交叉验证、Holdout 验证、Leave One Out 交叉验证(LOOCV)、Bootstrap 和 Reduced Set。

随着 LLM 应用增多,其可解释性却越来越差,因此现有的评估协议可能不足以彻底评估 LLM 的真实能力。
开发语言模型(尤其是大型语言模型)的最初目标是提升 AI 在自然语言处理任务上的性能,其中包含理解任务和生成任务。正因为此,大多数评估研究关注的也主要是自然语言任务。
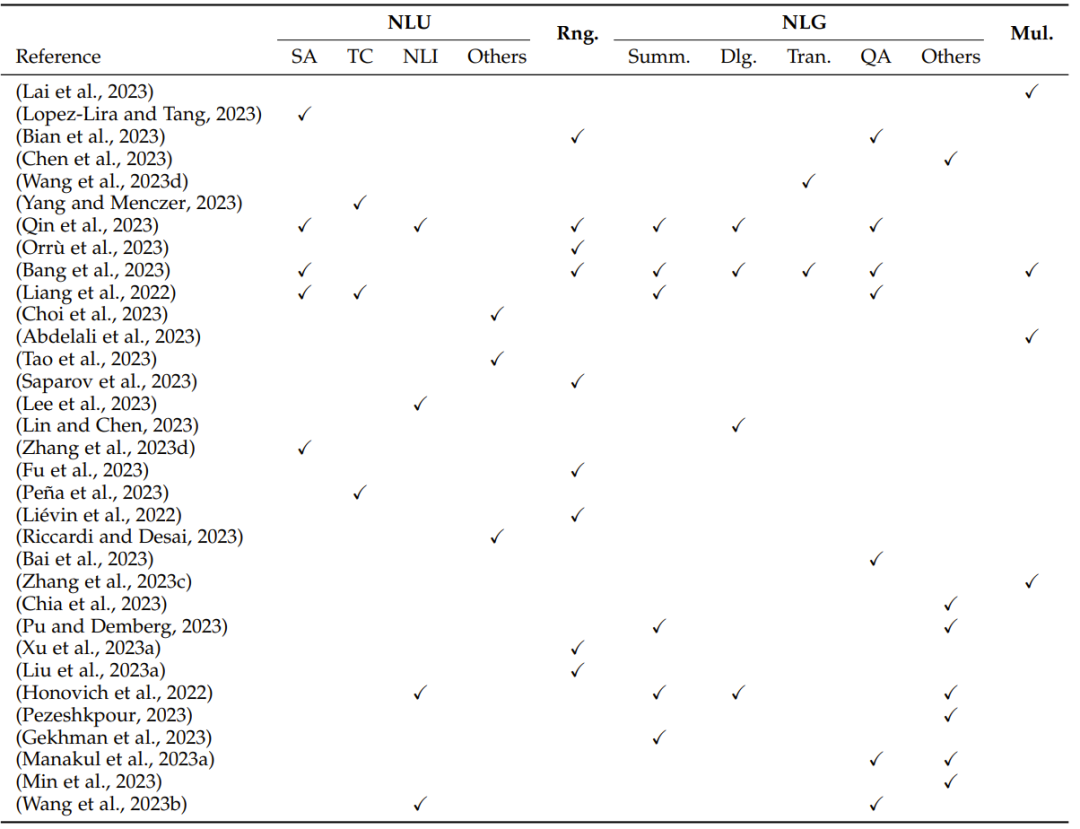
表 2:基于自然语言处理任务的评估概况:NLU(自然语言理解,包括 SA(情感分析)、TC(文本分类)、NLI(自然语言推理)和其它 NLU 任务)、Rng.(推理)、NLG(自然语言生成,包括 Summ.(摘要)、Dlg.(对话)、Tran.(翻译)、QA(问答)和其它 NLG 任务)和 Mul.(多语言任务)
LLM 的评估涵盖稳健性、道德、偏见和可信度等关键方面。为了全面评估 LLM 的表现,这些因素的重要性正在提升。
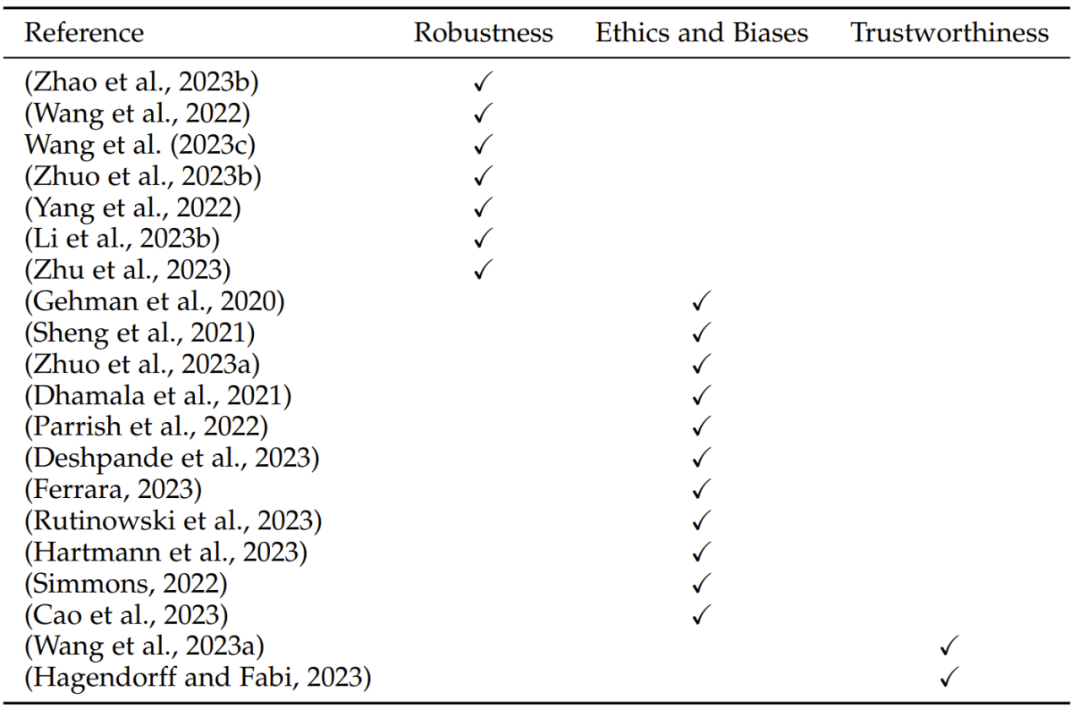
表 3:在稳健性、道德、偏见和可信度方面的 LLM 评估研究概况
社会科学研究的是人类社会和个人行为,包括经济学、社会学、政治学、法学等学科。评估 LLM 在社会科学领域的表现对于学术研究、政策制定和社会问题解决而言具有重要意义。这些评估有助于推进模型在社会科学领域的应用并改善模型的质量,提升对人类社会的理解以及推动社会进步。
评估 LLM 在自然科学和工程学领域的表现有助于引导科学研究的应用和发展、技术开发以及工程研究。
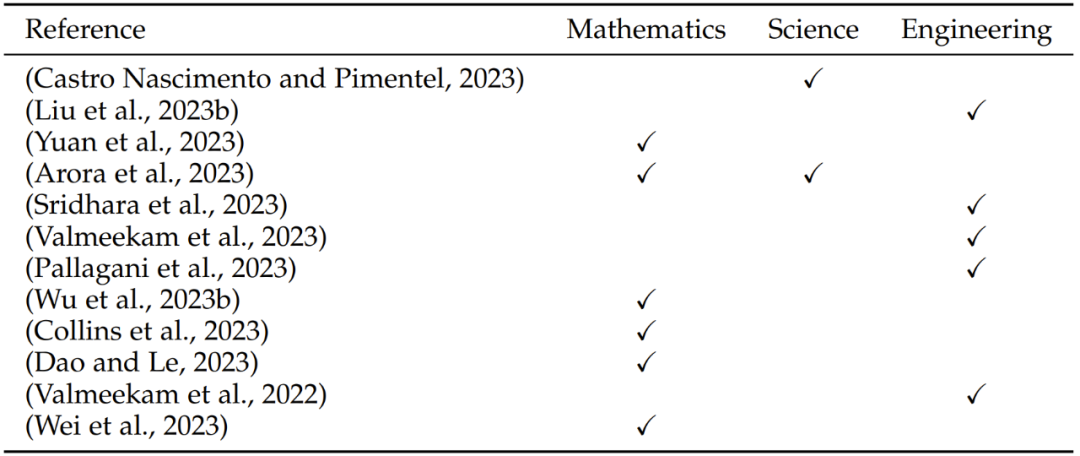
表 4:在自然科学和工程学任务方面的评估研究概况,其中涉及三个方面:数学、科学和工程学
LLM 在医学领域的应用最近引起了极大的关注。这里从四个方面介绍 LLM 在医学领域的应用:医学问答、医学检查、医学评估和医学教育。
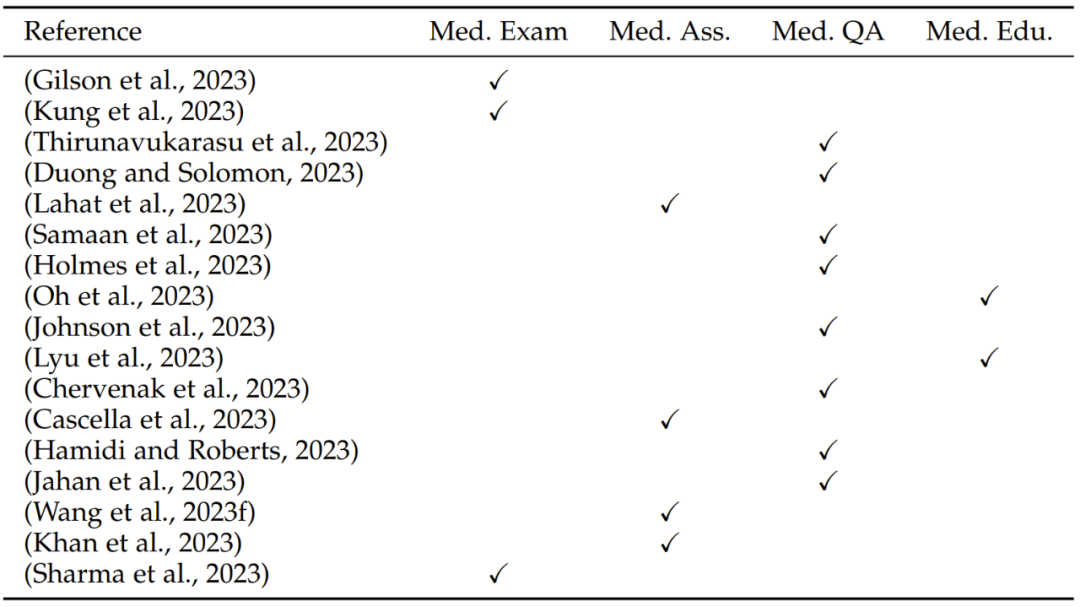
表 5:LLM 的医学应用方面的评估研究概况,其中涉及四个方面:Med. Exam.(医学检查)、Med. Ass.(医学评估)、Med. QA(医学问答)和 Med. Edu.(医学教育)
LLM 不仅专注于一般语言任务,而是可以用作一种强大工具,应对不同领域的任务。通过为 LLM 配备外部工具,可以极大扩展模型能力。
除了上述分类,LLM 还能用于其它一些不同领域,包括教育、搜索和推荐、性格测试以及特定领域的应用。
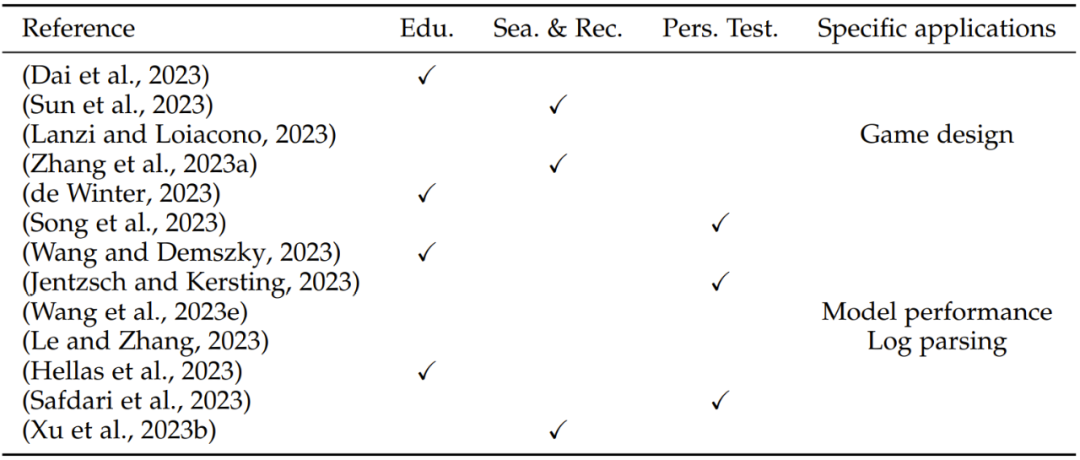
表 6:LLM 的其它应用方面的评估研究概况,其中涉及四个方面:Edu.(教育)、Sea. & Rec. (搜索和推荐)、Pers. Test.(性格测试)和 Specific applications(特定领域的应用)
LLM 评估数据集的作用是测试和比较不同语言模型在各种任务上的性能。GLUE 和 SuperGLUE 等数据集的目标是模拟真实世界的语言处理场景,其中涵盖多种不同任务,如文本分类、机器翻译、阅读理解和对话生成。这里不关注用于语言模型的任何单个评估数据集,关注的则是用于评估 LLM 的基准。
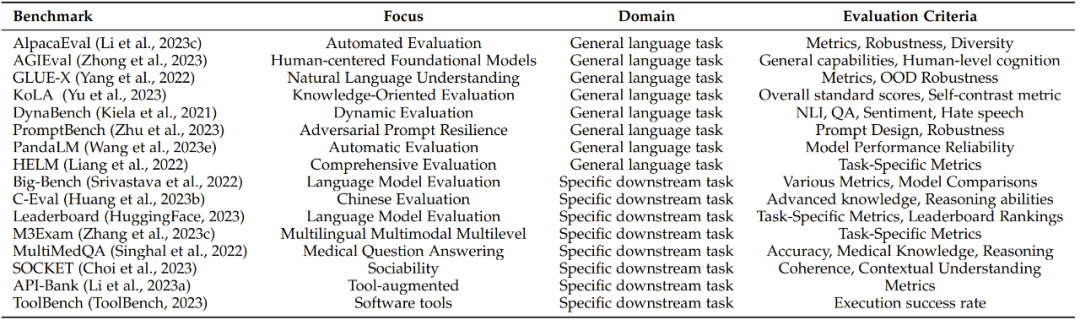
由于 LLM 在不断演进,因此基准也会变化,这里列出了 13 个常用的基准。每个基准侧重于不同的方面和评估指标,都为各自领域提供了宝贵的贡献。为了更好地进行总结,这里将基准分为两类:通用语言任务基准和特定下游任务基准。
常用的评估方法分为两大类:自动评估和人类评估。顾名思义,这里就不多介绍了。
现在总结一下 LLM 在不同任务中的成功和失败案例。注意,以下结论都是基于现有评估工作得出的,结果可能取决于具体的数据集。
-
LLM 熟练掌握了文本生成,能生成流畅和精确的语言表达。
-
LLM 能出色地应对涉及语言理解的任务,比如情感分析和文本分类。
-
LLM 展现出了稳健的上下文理解能力,让它们能生成与给定输入相符的连贯响应。
-
LLM 在多种自然语言处理任务上的表现都值得称赞,包括机器翻译、文本生成和问答。
-
LLM 可能会在生成过程中展现出偏见和不准确的问题,从而得到带偏见的输出。
-
LLM 在理解复杂逻辑和推理任务方面的能力有限,经常在复杂的上下文中发生混淆或犯错。
-
LLM 处理大范围数据集和长时记忆的能力有限,这可能使其难以应对很长的文本和涉及长期依赖的任务。
-
LLM 整合实时和动态信息的能力有限,这让它们不太适合用于需要最新知识或快速适应变化环境的任务。
-
LLM 对 prompt 很敏感,尤其是对抗性 prompt,这会激励研究者开发新的评估方法和算法,以提升 LLM 的稳健性。
-
在文本摘要领域,人们观察到大型模型可能在特定评估指标上表现不佳,原因可能在于这些特定指标的固有局限性和不足之处。
随着 LLM 的快速发展和广泛使用,在实际应用和研究中评估它们的重要性变得至关重要。这个评估过程不仅应该包括任务层面的评估,还应该包括它们在社会方面的潜在风险。表 8 总结了现有的基准和评估协议。

最后来看看 LLM 评估研究方面面临的挑战。作者认为,为了推动 LLM 和其它 AI 模型的成功发展,应当将评估当作一门关键性学科来对待。现有的协议不足以透彻地评估 LLM,还有许多挑战有待攻克,下面将简单罗列出这些挑战,但它们也是 LLM 评估方面的未来研究的新机会。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢