
基于D-Adaptation的免学习率(非参数)学习,Learning-Rate-Free Learning by D-Adaptation
-
机构:Meta AI、Inria Sierra
-
作者:Aaron Defazio、Konstantin Mishchenko(现为三星人工智能中心研究科学家)
梯度下降的单环方法,不需要知道从初始点到解集的距离D,可渐近地实现凸 Lipschitz 函数复杂度类的最佳收敛率;式此类的第一个非参数方法,在收敛速率中没有额外的乘性对数因子;
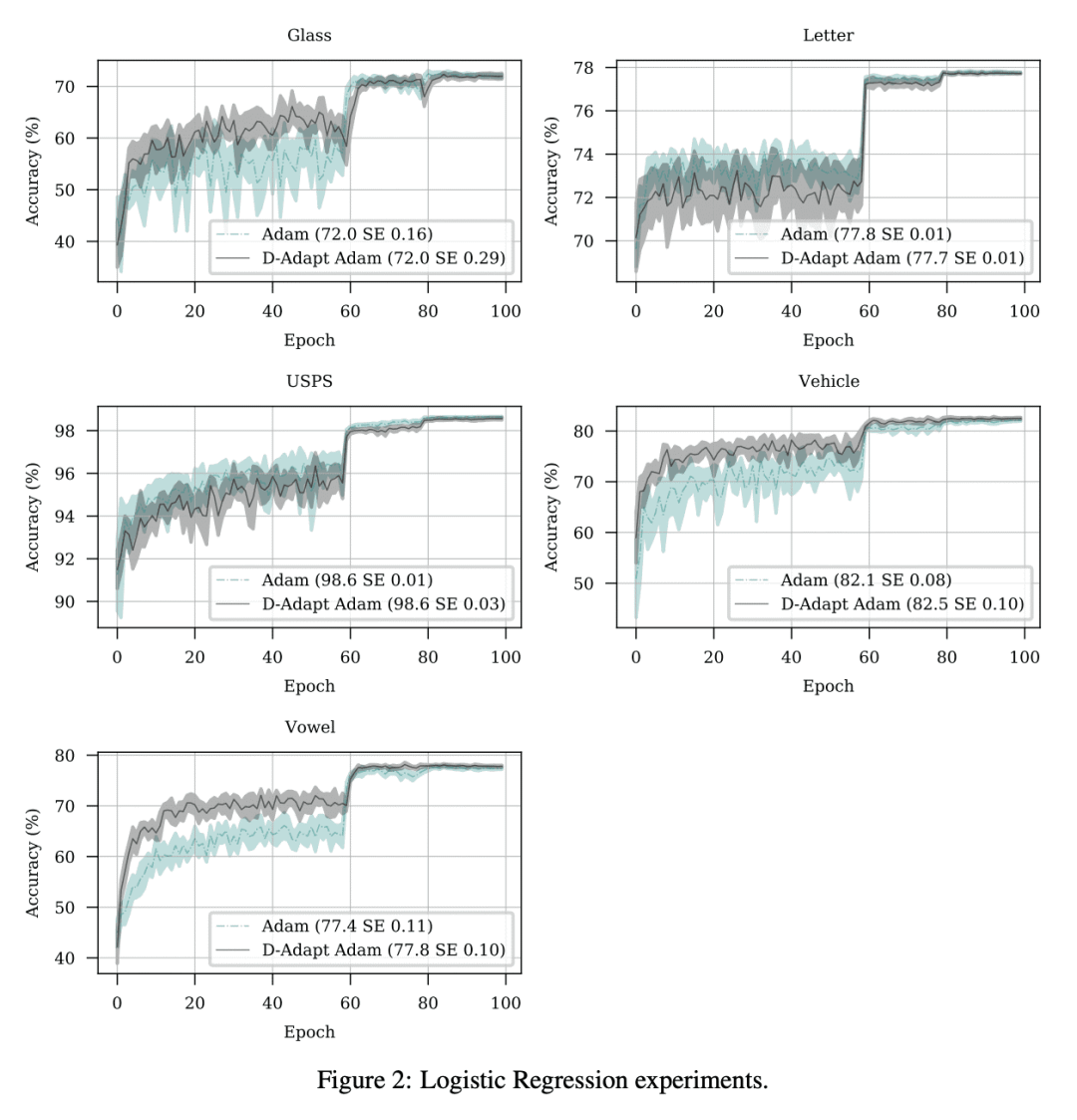
对该方法的 SGD 和 Adam 变体进行了广泛的实验,在十几个不同机器学习问题中能自动匹配手动微调的学习率,包括大规模视觉和语言问题。
该研究旨在为非光滑随机凸优化获取无学习率的最优界限,所提方法克服了优化此类问题时传统学习率选择的限制,为优化领域做出了有价值且实际的贡献。
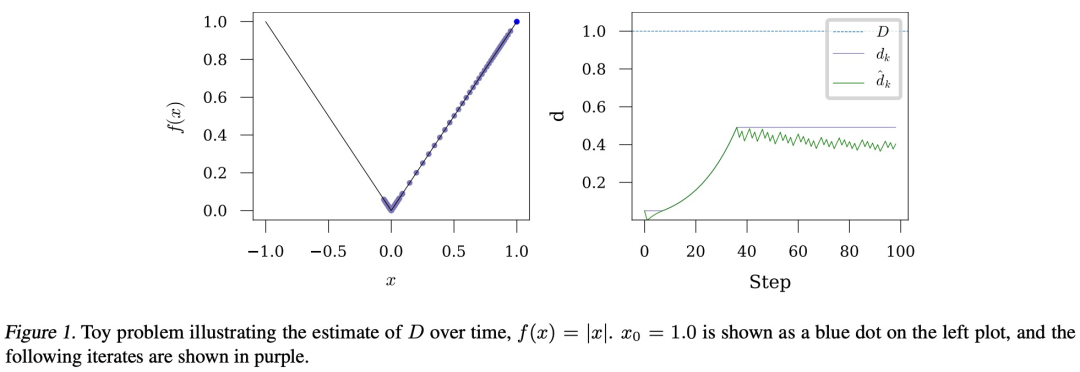
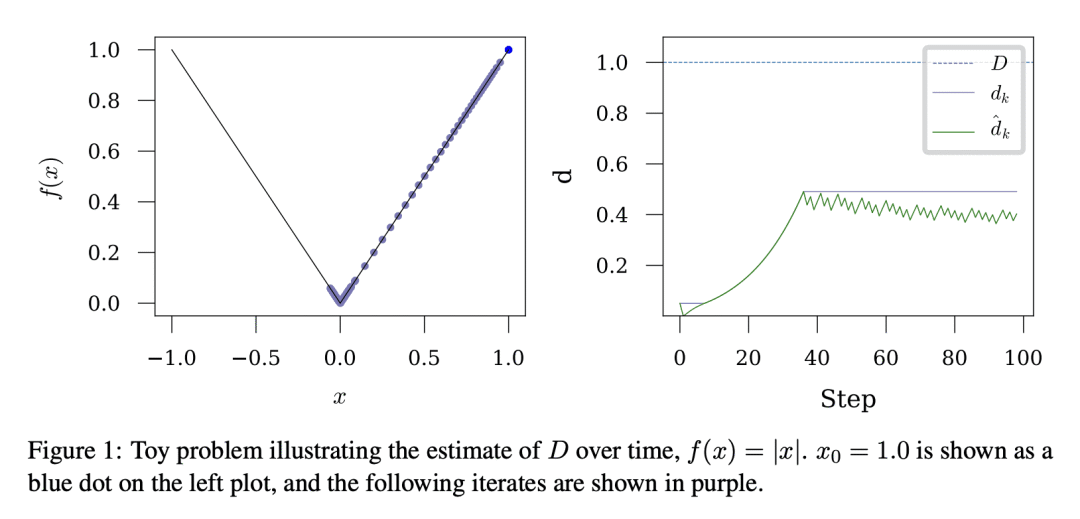
该研究还提出了新方法的 SGD 和 Adam 变体,将用于大规模 CV 和 NLP 问题。

提出一种新的梯度下降方法,不需要知道到解集的距离 D,在不同机器学习问题中能匹配手动微调的学习率,每一步无需额外的函数值或梯度评估。
Lipschitz 函数的梯度下降速度,在很大程度上取决于学习率的选择。设置学习率以实现最佳收敛率,需要知道从初始点到解集的距离D。本文描述了一种单循环方法,无需回溯或线搜索,不需要关于 D 的知识,但渐近地实现了凸 Lipschitz 函数复杂类的最佳收敛速度。该方法是此类的第一个无参数方法,在收敛速率中没有额外的乘性对数因子。对该方法的 SGD 和 Adam 变体进行了广泛的实验,在十几个不同的机器学习问题(包括大规模视觉和语言问题)中能自动匹配手动微调的学习率。该方法实用、高效,每一步不需要额外的函数值或梯度评估。
论文链接:https://arxiv.org/abs/2301.07733

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢