
Bayesian Design Principles for Frequentist Sequential Learning
-
机构:哥伦比亚大学
-
作者:Yunbei Xu、Assaf Zeevi

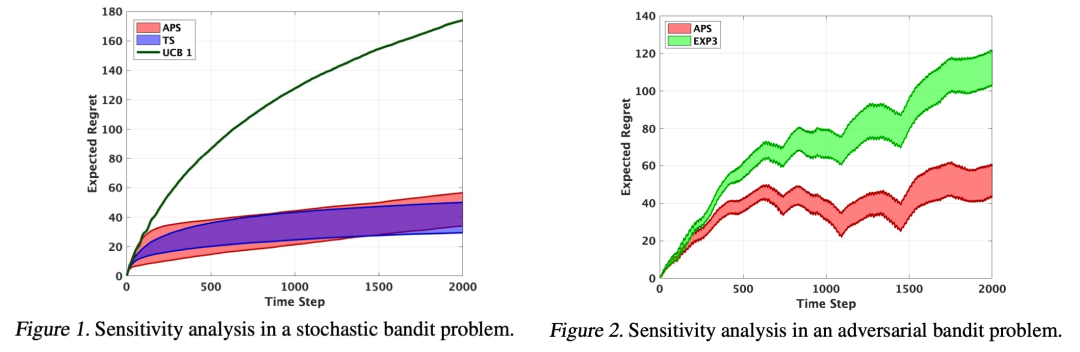
该论文探讨了设计 bandit 和其他顺序决策策略这一非常普遍的问题。论文提出使用一种称为算法信息比的新量对任何策略的遗憾进行约束的方法,并推导出优化该约束的方法。该约束比早期类似的信息理论量更为严格,而且这些方法在随机性和对抗性的 bandit 设置中都表现出色,实现了全局最优。
特别有趣的是,除了众所周知的 Thompson Sampling 和针对 bandit 的 UCB 之外,这篇论文可能为全新的 exploration-exploitation 策略打开了大门。事实上,这一原理如果扩展到强化学习领域是非常有前途的。该论文得到了专家评审的一致大力支持。
论文一作 Yunbei Xu 为哥伦比亚大学商学院博士,现为 MIT 博士后研究员,并将于 2024 年秋季开始任职 NUS 助理教授。他本科毕业于北京大学数学系。

参考链接:https://icml.cc/Conferences/2023/Awards
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢