
Open sourcing AudioCraft: Generative AI for audio made simple and available to all
地址:https://ai.meta.com/blog/audiocraft-musicgen-audiogen-encodec-generative-ai-audio/

一个专业的音乐家能够探索新作品,而不必在乐器上演奏一个音符。或者一个独立游戏开发人员以微薄的预算用逼真的声音效果和环境噪音填充虚拟世界。或者小企业主轻松地将配乐添加到他们最新的Instagram帖子中。这就是AudioCraft的承诺——我们简单的框架,在对原始音频信号进行训练后,而不是MIDI或钢琴卷,从基于文本的用户输入中生成高质量、逼真的音频和音乐。
AudioCraft由三种型号组成:MusicGen、AudioGen和EnCodec。MusicGen受过Meta拥有和专门许可的音乐培训,从基于文本的用户输入中生成音乐,而受过公共音效培训的AudioGen则从基于文本的用户输入中生成音频。今天,我们很高兴发布EnCodec解码器的改进版本,它允许以更少的工件生成更高质量的音乐;我们预先训练的AudioGen模型,允许您生成环境声音和声音效果,如狗叫、汽车喇叭或木地板上的脚步声;以及所有AudioCraft模型的重量和代码。这些模型可用于研究目的,并促进人们对该技术的了解。我们很高兴为研究人员和从业者提供访问权限,以便他们能够首次用自己的数据集训练自己的模型,并帮助推进最先进的技术。
论文地址:https://ai.meta.com/resources/models-and-libraries/audiocraft/
代码:https://github.com/facebookresearch/audiocraft
AudioCraft:从文本中生成高质量的音频和音乐
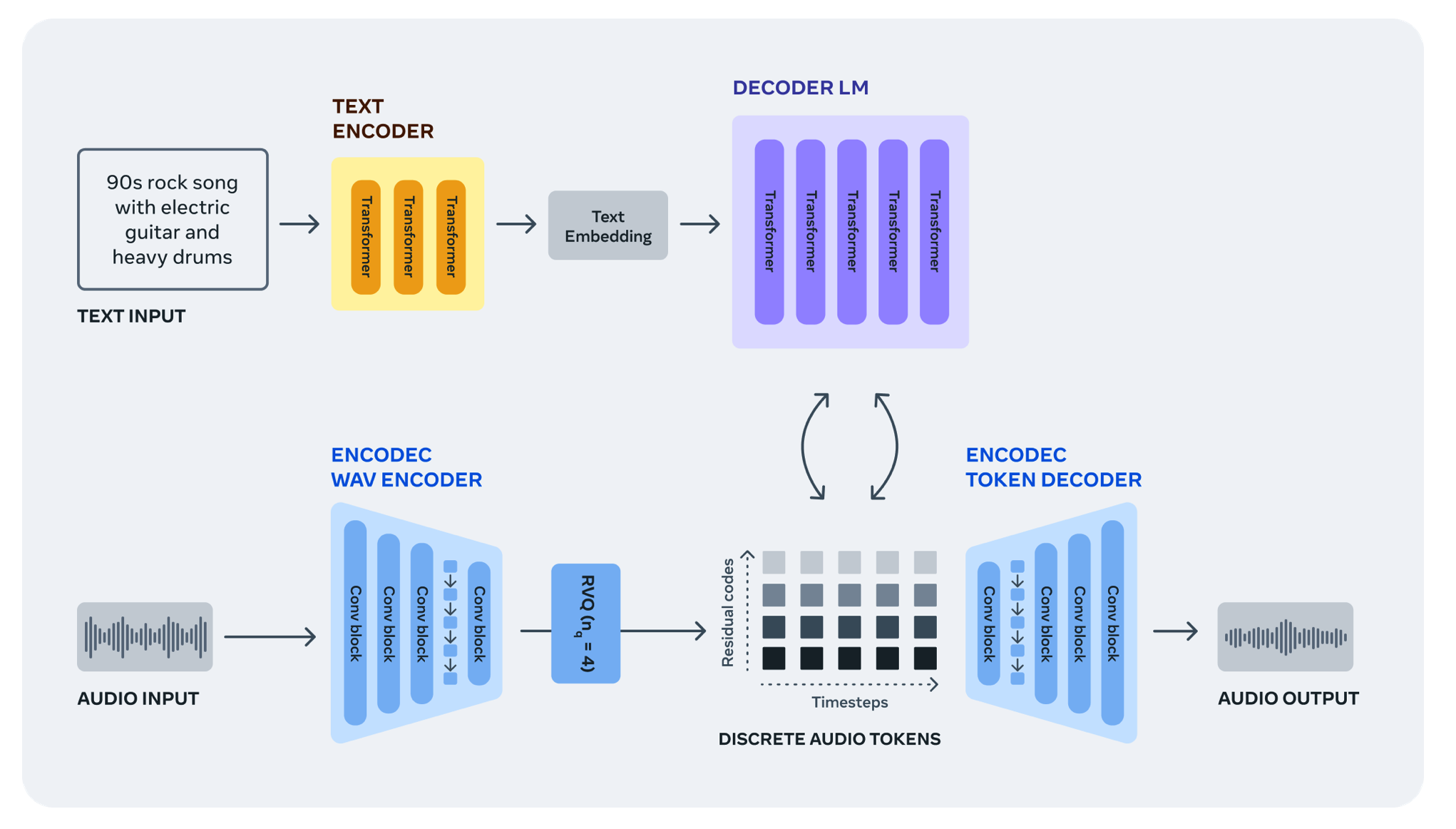
轻松地从文本到音频
近年来,包括语言模型在内的生成性人工智能模型取得了巨大的进步,并表现出非凡的能力:从表现出空间理解的文本描述中生成各种各样的图像和视频,到执行机器翻译甚至文本或语音对话代理的文本和语音模型。然而,虽然我们看到很多关于图像、视频和文本的生成人工智能的兴奋,但音频似乎总是有点落后。那里有一些工作,但它非常复杂,不是很开放,所以人们不能轻易玩它。
生成任何类型的高保真音频都需要以不同的规模对复杂的信号和模式进行建模。音乐可以说是最具挑战性的音频类型,因为它由本地和长距离模式组成,从一组音符到具有多种乐器的全球音乐结构。使用人工智能生成连贯的音乐通常通过使用MIDI或钢琴卷等符号表示来解决。然而,这些方法无法完全掌握音乐中富有表现力的细微差别和风格元素。最近的进步利用自我监督的音频表示学习和一些分层或级联模型来生成音乐,将原始音频输入一个复杂的系统,以便在生成高质量音频的同时捕获信号中的远程结构。但我们知道在这个领域可以做更多事情。
AudioCraft系列模型能够产生具有长期一致性的高质量音频,并且可以通过自然界面轻松交互。与之前在该领域的工作相比,使用AudioCraft,我们简化了音频生成模型的整体设计——为人们提供了使用Meta在过去几年中开发的现有模型的完整配方,同时也使他们能够突破极限并开发自己的模型。
AudioCraft适用于音乐和声音生成以及压缩——所有这些都在同一个地方。因为它易于构建和重用,想要构建更好的声音生成器、压缩算法或音乐生成器的人可以在相同的代码库中完成这一切,并在其他人所做的基础上进行构建。
虽然在简化模型方面做了很多工作,但团队同样致力于确保AudioCraft能够支持最先进的技术。人们可以轻松地扩展我们的模型,并使其适应他们的研究用例。一旦你让人们访问模型,根据他们的需求调整他们,就几乎有无限的可能性。这就是我们想用这个模特家族做的事情:赋予人们扩展工作的权力。
音频生成的简单方法
从原始音频信号中生成音频具有挑战性,因为它需要对极长的序列进行建模。以44.1 kHz(这是音乐录音的标准质量)采样的几分钟的典型音乐曲目由数百万个时间步组成。相比之下,Llama和Llama 2等基于文本的生成模型被输入了作为子词处理的文本,每个样本仅代表数千个时间步。
为了应对这一挑战,我们使用EnCodec神经音频编解码器从原始信号中学习离散音频令牌,这为我们提供了一个新的音乐样本的固定“词汇”。然后,我们可以通过这些离散音频令牌训练自动回归语言模型,以便在使用EnCodec的解码器将令牌转换回音频空间时生成新令牌、新声音和音乐。
从波形中学习音频令牌
EnCodec是一种有损神经编解码器,专门用于压缩任何类型的音频并以高保真度重建原始信号。它由一个具有残余矢量量化瓶颈的自动编码器组成,该瓶颈产生几个具有固定词汇的并行音频令牌流。不同的流捕获音频波形的不同级别的信息,使我们能够从所有流中以高保真度重建音频。
培训音频语言模型
然后,我们使用单个自回归语言模型对EnCodec的音频令牌进行递归建模。我们引入了一种简单的方法来利用并行令牌流的内部结构,并表明通过单一模型和优雅的令牌交错模式,我们的方法有效地对音频序列进行建模,同时捕获音频中的长期依赖性,并允许我们产生高质量的声音。
从文本描述中生成音频
通过AudioGen,我们证明了我们可以训练人工智能模型来执行文本到音频生成的任务。给定声学场景的文本描述,该模型可以生成与描述相对应的环境声音,具有逼真的录制条件和复杂的场景上下文。
MusicGen是专门为音乐生成量身定制的音频生成模型。音乐曲目比环境声音更复杂,在创作新颖的音乐作品时,在长期结构上生成连贯的样本尤为重要。MusicGen接受了大约40万次录音以及文本描述和元数据的培训,相当于Meta拥有或专门为此目的授权的20,000小时的音乐。
在这项研究的基础
我们的团队继续研究高级生成AI音频模型背后的研究。作为本次AudioCraft发布的一部分,我们进一步提供了新的方法,通过基于扩散的离散表示解码方法来提高合成音频的质量。我们计划继续研究音频生成模型的更好可控性,探索其他调理方法,并推动模型捕获更远范围依赖的能力。最后,我们将继续调查这些受过音频训练的模型的局限性和偏见。
该团队正在努力改进当前模型,从建模的角度提高其速度和效率,并改进我们控制这些模型的方式,这将开辟新的用例和可能性。
责任和透明度是我们研究的基石
对我们的工作保持开放态度很重要,这样研究界才能在此基础上再接再厉,并继续我们关于如何负责任地构建人工智能的重要对话。我们认识到,用于训练我们模型的数据集缺乏多样性。特别是,使用的音乐数据集包含更大比例的西式音乐,并且只包含用英语编写的文本和元数据的音频文本对。通过共享AudioCraft的代码,我们希望其他研究人员能够更轻松地测试新的方法,以限制或消除生成模型中的潜在偏见和滥用。
开源的重要性
负责任的创新不能孤立地发生。开源我们的研究和由此产生的模型有助于确保每个人都有平等的机会。
我们正在向研究界提供多种尺寸的模型,并共享AudioGen和MusicGen模型卡,这些模型卡详细介绍了我们如何根据负责任的人工智能实践方法构建模型。我们的音频研究框架和培训代码是在麻省理工学院许可证下发布的,以使更广泛的社区能够在我们的工作基础上进行复制和构建。通过开发更先进的控件,我们希望这些模型能够对音乐爱好者和专业人士都有用。
拥有坚实的开源基础将促进创新,并补充我们未来制作和收听音频和音乐的方式:用音效和史诗音乐思考丰富的睡前故事阅读。有了更多的控制,我们认为MusicGen可以变成一种新型乐器——就像合成器首次出现时一样。
我们将AudioCraft系列模型视为音乐家和声音设计师专业工具箱的工具,因为它们可以提供灵感,帮助人们快速集思广益,并以新的方式迭代他们的作品。
与其将工作作为一个不可逾越的黑匣子,不如公开我们如何开发这些模型,并确保它们易于人们使用——无论是研究人员还是整个音乐社区——有助于人们了解这些模型可以做什么,了解他们不能做什么,并有权实际使用它们。
在未来,生成人工智能可以帮助人们在早期原型和灰盒阶段更快地获得反馈,从而极大地缩短迭代时间——无论他们是为元宇宙构建世界的大型AAA开发人员,还是正在创作下一个作品的音乐家(业余、专业或其他),还是希望提升其创意资产的中小型企业主。AudioCraft是生成人工智能研究向前迈出的重要一步。我们相信,我们为成功生成强大、连贯和高质量的音频样本而开发的简单方法将对考虑听觉和多模态接口的先进人机交互模型的开发产生有意义的影响。我们迫不及待地想看看人们用它创造了什么。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢