

Machine Intelligence Research
随着大众对保护数据隐私的意识加强,作为训练模型主要范式之一的联邦学习(FL)因具有数据隐私保护功能而在近年来受到研究者们的越发关注。但是,大多数FL客户端当前还是单模态。随着边缘计算的崛起,多种多样的传感器和可穿戴设备产生了大量不同模态的数据,从而推动了对多模态联邦学习(MMFL)的研究。西安电子科技大学公茂果教授团队对多模态联邦学习(MMFL)领域的研究进行了深入剖析。文章首先分析了MMFL的主要动力。然后将当前已提出的MMFL方法根据MMFL的模态分布和模态注释进行了归类。接着讨论了MMFL的数据集和应用场景。最后列出了MMFL的局限与挑战,并为未来的研究进行了展望并提出了方法。

图片来自Springer
全文下载:
Federated Learning on Multimodal Data: A Comprehensive Survey
Yi-Ming Lin, Yuan Gao, Mao-Guo Gong, Si-Jia Zhang, Yuan-Qiao Zhang, Zhi-Yuan Li
https://link.springer.com/article/10.1007/s11633-022-1398-0
https://www.mi-research.net/en/article/doi/10.1007/s11633-022-1398-0
大数据的发展推动着人工智能领域的蓬勃发展。现代社会上大量涌现的边缘设备,如移动设备、物联网设备使得分布式信息源上的私人数据激增。充足的数据意味着能够解决不同任务的巨大机遇,故大部分数据并没有被集中管理而是分布在不同公司服务器上,而这一情况本质上是极为敏感的。
不同平台上低质量、不全面、不充分的数据只能形成数据孤岛。这对于医疗卫生领域来说尤为致命,因为医疗数据极具敏感性。这些医疗数据经常储存在不同的医疗设备中,并不对外公开。因对人们隐私保护的日益关注,为保护用户隐私与数据安全,国内外已推行了相关法律法规。
作为以保护数据隐私的方式来训练模型的主要范式之一,联邦学习(FL)受到了广泛关注。相较于集中式学习,FL提出了一个分布式学习框架。该框架不会传输每个用户端的隐私数据,只会传输模型参数或中间结果,这样一来,既降低了传输成本,又保护了客户端的隐私。核心理念就是让分布式模型直接在多种数据源中利用本地数据进行训练。全球模型通过交换模型参数或中间结果来构建,既保证了准确性又保护了隐私。FL克服了只能在单个设备上汇总所有数据的局限,允许模型从分散数据中学习,从而成功解决了隐私保护的问题。
虽然FL不需要分享本地数据就能进行全球模型的训练,但大多数现有的FL方法在训练时仍使用的是单模态数据。随着边缘计算的不断发展,不同传感器和设备产生的数据具有不同模态(如触觉、视觉、听觉等)。例如,在医学领域,理学检查通常包括X光、计算机断层扫描(CT)和核磁共振成像(MRI);在一个智能家庭中,人类活动有可能被房间里的身体传感器或RGB摄像头记录。对于配有不同设备设置的客户端,有些可能会有多模态的本地数据(如多模态客户端),还有一些可能会有单模态的本地数据(如单模态客户端)。因此,对于多模态联邦学习(MMFL)的研究是有必要的。
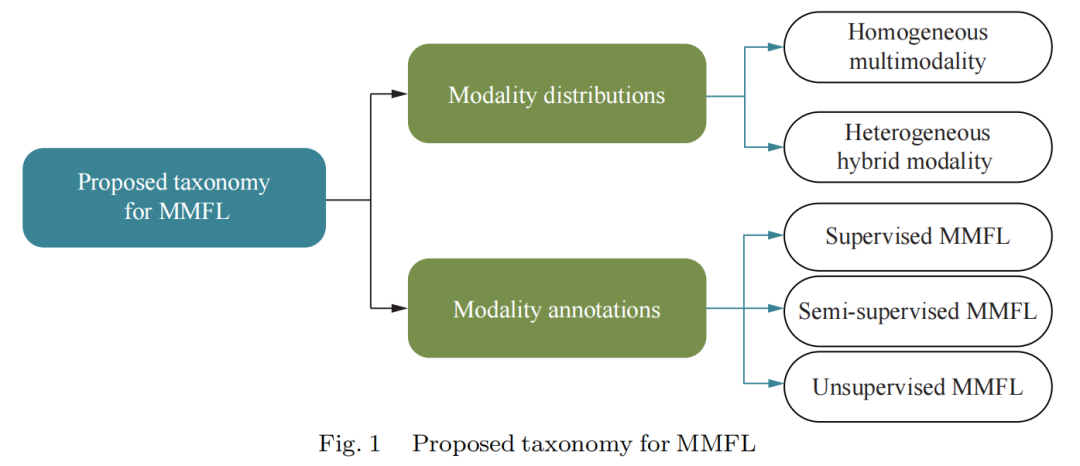 图1:MMFL的分类法
图1:MMFL的分类法
多模态学习能保证比单模态学习更高的准确性与鲁棒性,因为多模态学习接收了来自不同信息源在信号层和语义层上的信息。通过表征、对齐和融合的方式,多模态学习能更好地完成任务。表征负责通过分析由不同模态提供的额外信息来找到反映所给任务的语境属性。对齐负责明确不同模态之间的映射,而融合负责结合来自多种模态的信息从而完成预期任务。这些方法有助于FL更高效地使用从客户端传上来的数据,从而完成任务。而使用这些不同模态的客户端数据是让FL获得更好结果的关键。现实生活里,多模态的应用,比如使用可穿戴传感器的心理健康监测、使用RGB和深度图的医学影像以及使用文本和图像的语言翻译,都呈现出了比单模态模型更高的准确性和鲁棒性。
MMFL解决了当每个客户端的本地数据是不同模态时,如何进行全球模型学习的问题,因此成为了用FL来处理多模态数据领域中的一匹黑马。MMFL能够实现不同模态间互补信息的高效利用,从而获得一个优于单模态数据的全球模型。本文力求对当前MMFL的情况做一个深入研究,包括近期进展、挑战与应用。本文是首篇对MMFL进行较为细致研究的综述。本文的主要贡献总结如下:
首先,本文简要介绍了FL,并详细分析了现有FL算法在面对多模态数据时的缺点。然后介绍了将多模态数据用于FL的主要动机与应用场景。接着,详细介绍了团队对MMFL提出的一个分类方法。
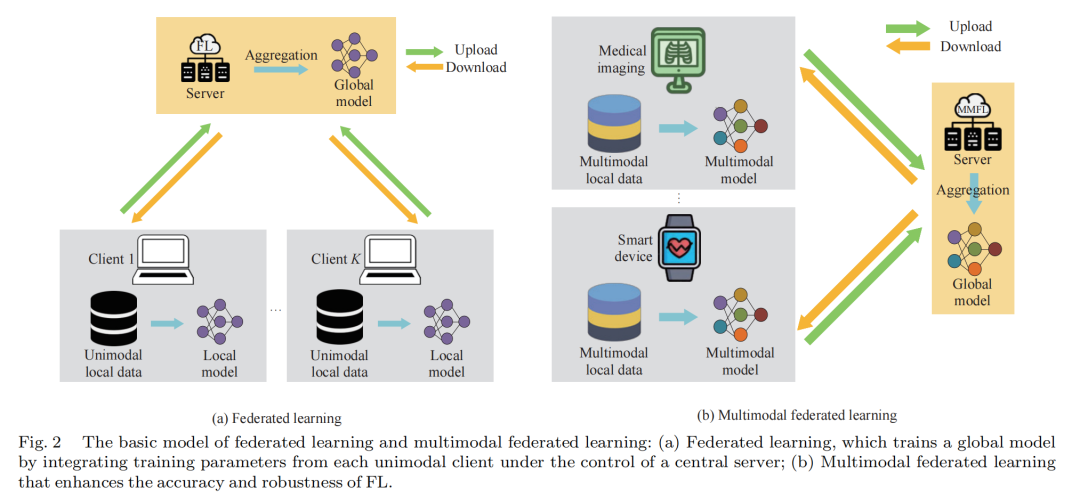 图2:联邦学习及多模态联邦学习的基本模型
图2:联邦学习及多模态联邦学习的基本模型
为了梳理当前对MMFL的现有研究,本文为MMFL提出了一个基于分布和基于注释的模态分类方法,强调了当前对MMFL现有研究中的主要观点与假设,以及所面临的挑战。
本文介绍了MMFL数据集和使用场景,并对未来MMFL的研究工作进行了展望,同时讨论了新的数据结合方法和更可靠的搭建MMFL系统的方法。
本文其余部分结构如下:第2部分介绍了相关研究,包括FL和多模态学习的基本知识,以及对用FL学习多模态数据的展望。第3部分提出了对MMFL的分类法。第4部分介绍了一些常用的多模态联邦数据集。第5部分介绍了MMFL在现实生活中的应用。第6部分介绍了MMFL的当前困难与展望。第7部分是本文的小结。
全文下载:
Federated Learning on Multimodal Data: A Comprehensive Survey
Yi-Ming Lin, Yuan Gao, Mao-Guo Gong, Si-Jia Zhang, Yuan-Qiao Zhang, Zhi-Yuan Li
https://link.springer.com/article/10.1007/s11633-022-1398-0
https://www.mi-research.net/en/article/doi/10.1007/s11633-022-1398-0
BibTex:
@Article{MIR-2022-08-261,
author = {Yi-Ming Lin and Yuan Gao and Mao-Guo Gong and Si-Jia Zhang and Yuan-Qiao Zhang and Zhi-Yuan Li},
journal = {Machine Intelligence Research},
title = {Federated Learning on Multimodal Data: A Comprehensive Survey},
year = {2023},
volume = {20},
number = {4},
pages = {539-553},
doi = {10.1007/s11633-022-1398-0}
}

MIR为所有读者提供免费寄送纸刊服务,如您对本篇文章感兴趣,请点击下方链接填写收件地址,编辑部将尽快为您免费寄送纸版全文!
说明:如遇特殊原因无法寄达的,将推迟邮寄时间,咨询电话010-82544737
收件信息登记:
https://www.wjx.cn/vm/eIyIAAI.aspx#
关于Machine Intelligence Research
Machine Intelligence Research(简称MIR,原刊名International Journal of Automation and Computing)由中国科学院自动化研究所主办,于2022年正式出版。MIR立足国内、面向全球,着眼于服务国家战略需求,刊发机器智能领域最新原创研究性论文、综述、评论等,全面报道国际机器智能领域的基础理论和前沿创新研究成果,促进国际学术交流与学科发展,服务国家人工智能科技进步。期刊入选"中国科技期刊卓越行动计划",已被ESCI、EI、Scopus、中国科技核心期刊、CSCD等数据库收录。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢