


FlagEmbedding:
https://github.com/FlagOpen/FlagEmbedding
https://huggingface.co/BAAI/
https://github.com/FlagOpen/FlagEmbedding
https://github.com/FlagOpen/FlagEmbedding/tree/master/benchmark
检索精度大幅领先
中英文(C-MTEB + MTEB)共87个任务上表现优异
BGE 是当前中文任务下最强语义向量模型,各项语义表征能力全面超越同类开源模型。
中文语义向量综合表征能力评测 C-MTEB 的实验结果显示(Table 1),BGE中文模型(BGE-zh)在对接大语言模型最常用到的检索能力上领先优势尤为显著,检索精度约为 OpenAI Text Embedding 002 的1.4倍。
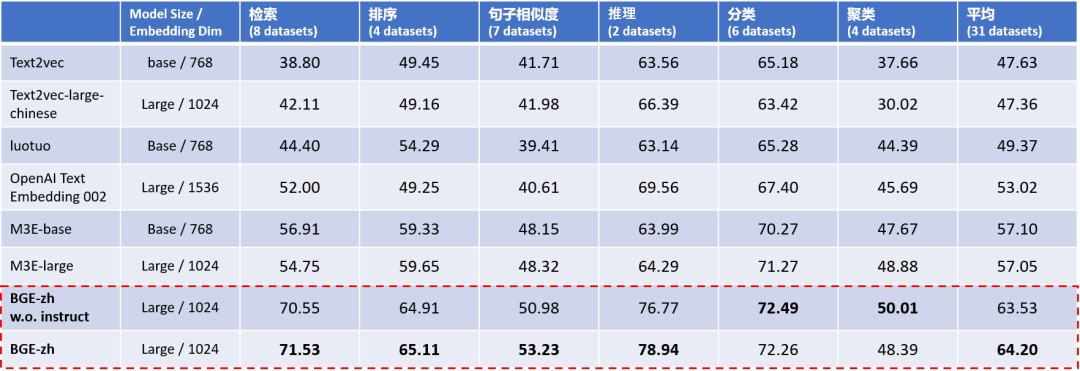
Table 1. 中文语义向量综合表征能力评测(C-MTEB)
注:Model Size一列中Base ~100M,Large ~300M,XXL ~11B
BGE w.o. Instruct: BGE输入端没有使用instruction
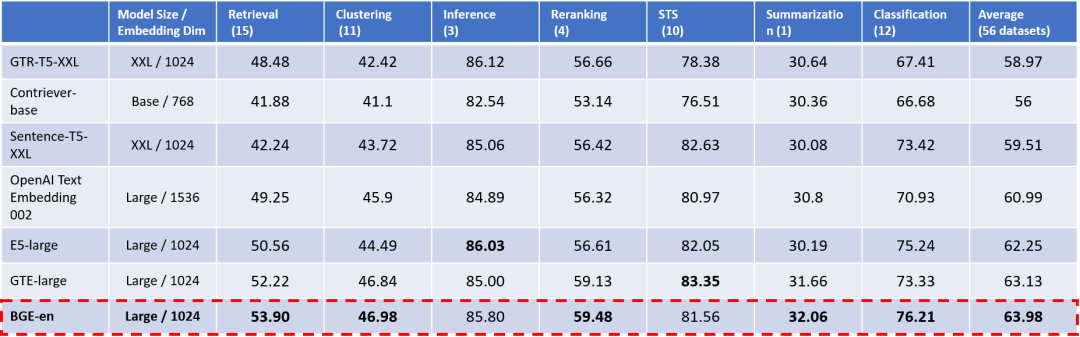
Table 2. 英文语义向量综合表征能力评测(MTEB)
注:Model Size一列中 Base ~100M,Large ~300M,XXL ~11B
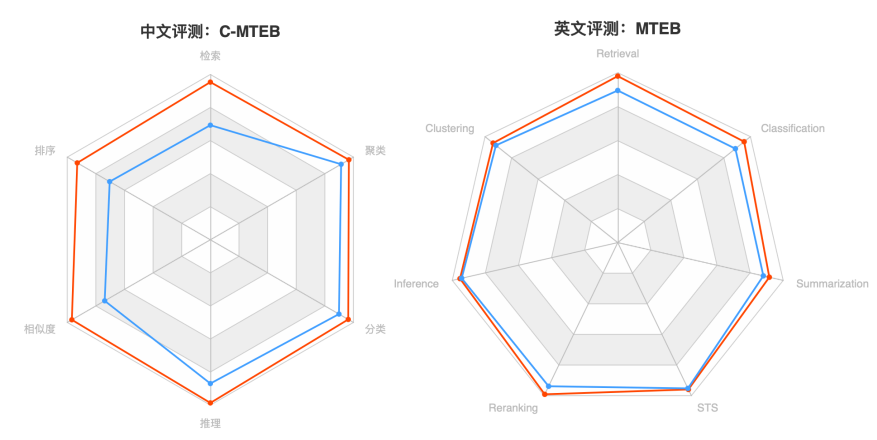
Figure 1. 中文C-MTEB(左)、英文MTEB(右)
注:BGE为红色,OpenAI Text Embedding 002为蓝色
中文语义向量
全面评测基准 C-MTEB
此前,中文社区一直缺乏全面、有效的评测基准,BGE 研究团队依托现有的中文开源数据集构建了针对中文语义向量的评测基准 C-MTEB(Chinese Massive Text Embedding Benchmark,如 Table 3所示)。
C-MTEB 的建设参照了同类别英文基准 MTEB [12],总共涵盖6大类评测任务(检索、排序、句子相似度、推理、分类、聚类),涉及31个相关数据集。
C-MTEB 是当前最大规模、最为全面的中文语义向量评测基准,为可靠、全面的测试中文语义向量的综合表征能力提供了实验基础。
目前,C-MTEB 的全部测试数据以及评测代码已连同 BGE 模型一并开源。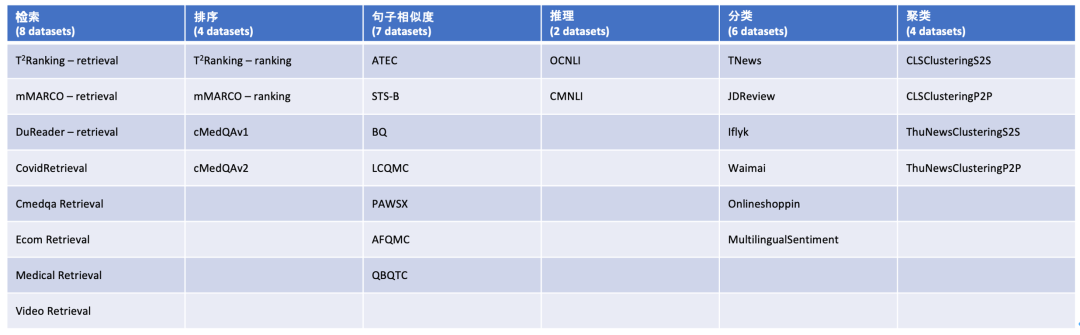
Table 3. C-MTEB 评测任务维度及数据集
技术亮点:
高效预训练+大规模文本对微调
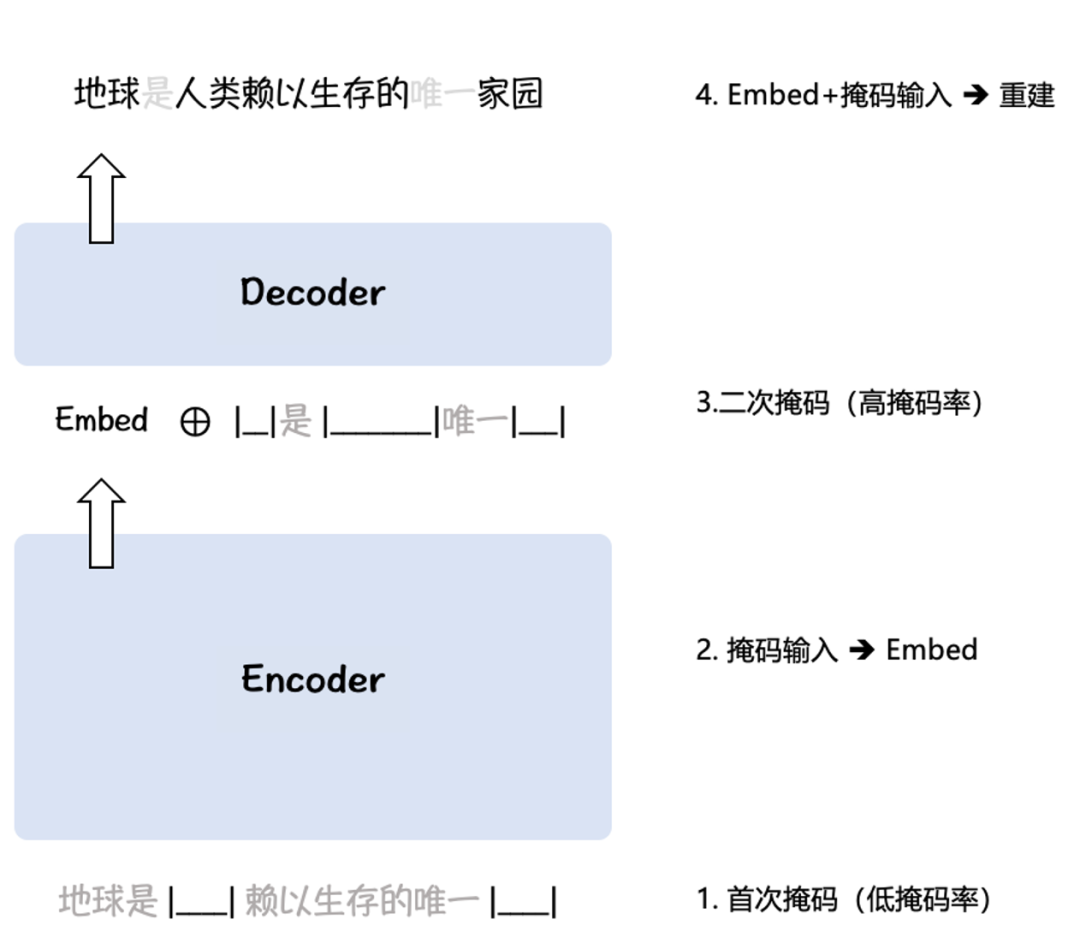
Figure 2. RetroMAE 预训练算法示意
BGE 针对中文、英文分别构建了多达120M、232M的样本对数据,从而帮助模型掌握实际场景中各种不同的语义匹配任务,并借助负采样扩增 [7] 与难负样例挖掘 [8] 进一步提升对比学习的难度,实现了多达65K的负样本规模,增强了语义向量的判别能力。
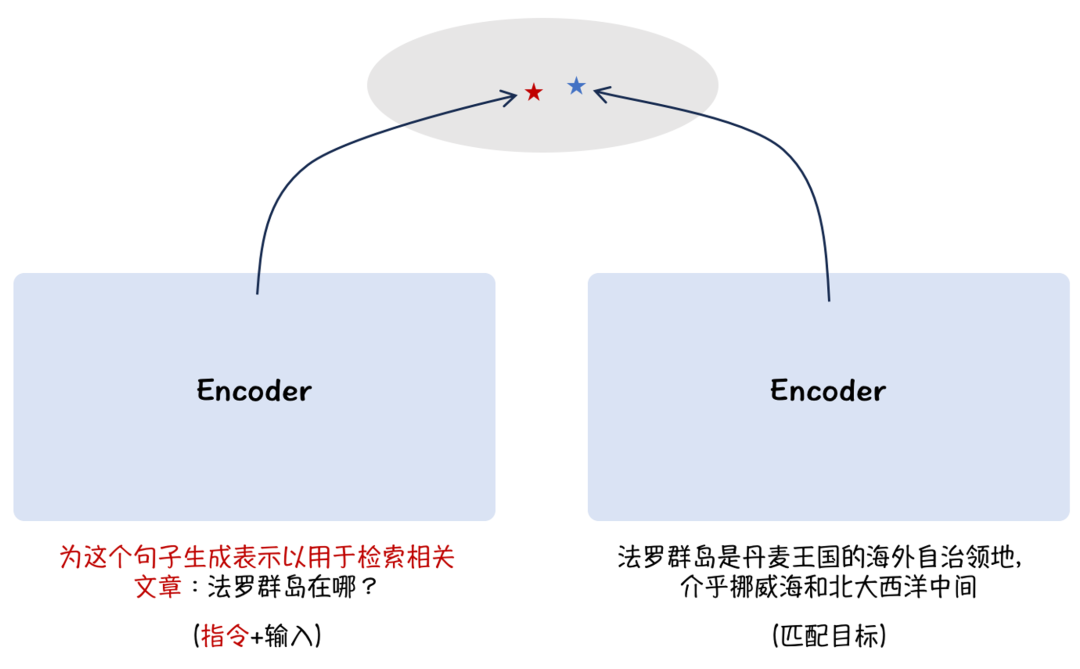
Figure 3. 注入场景提示提升多任务通用能力
综上,BGE 是当前性能最佳的语义向量模型,尤其在语义检索能力上大幅领先。其卓越的能力为构建大语言模型应用(如阅读理解、开放域问答、知识型对话)提供了重要的功能组件。相较于此前的开源模型,BGE 并未增加模型规模与向量的维度,因而保持了相同的运行、存储效率。
目前,BGE 中英文模型均已开源,代码及权重均采用 MIT 协议,支持免费商用。
作为智源「FlagOpen大模型技术开源体系」的重要组成部分,BGE 将持续迭代和更新,赋能大模型生态基础设施建设。
https://github.com/FlagOpen/FlagEmbedding
https://flagopen.baai.ac.cn/
语义向量模型知识拓展
提升大模型长期记忆
参考文献:
[1] Unsupervised Dense Information Retrieval with Contrastive Learning (Contriever), https://arxiv.org/pdf/2112.09118.pdf
[2] Large Dual Encoders Are Generalizable Retrievers (GTR), https://aclanthology.org/2022.emnlp-main.669.pdf
[3] Text Embeddings by Weakly-Supervised Contrastive Pre-training (E5), https://arxiv.org/abs/2212.03533
[4] Introducing text and code embeddings (OpenAI Text Embedding), https://openai.com/blog/introducing-text-and-code-embeddings , https://openai.com/blog/new-and-improved-embedding-model
[5] RetroMAE: Pre-Training Retrieval-oriented Language Models Via Masked Auto-Encoder (RetroMAE), https://aclanthology.org/2022.emnlp-main.35/
[6] RetroMAE-2: Duplex Masked Auto-Encoder For Pre-Training Retrieval-Oriented Language Models (RetroMAE-2), https://aclanthology.org/2023.acl-long.148/
[7] Tevatron: An Efficient and Flexible Toolkit for Dense Retrieval (Tevatron), https://github.com/texttron/tevatron
[8] Dense Passage Retrieval for Open-Domain Question Answering (DPR), https://arxiv.org/abs/2004.04906
[9] One Embedder, Any Task: Instruction-Finetuned Text Embeddings (Instructor), https://instructor-embedding.github.io
[10] Wudao Corpora (悟道), https://github.com/BAAI-WuDao/Data
[11] The Pile: An 800GB Dataset of Diverse Text for Language Modeling (Pile), https://github.com/EleutherAI/the-pile
[12] MTEB: Massive Text Embedding Benchmark (MTEB), https://huggingface.co/blog/mteb
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢