
Simple synthetic data reduces sycophancy in large language models
J Wei, D Huang, Y Lu, D Zhou, Q V. Le
[Google DeepMind]
一作为谷歌DeepMind的研究工程师Jerry Wang,研究方向为语言模型对齐和推理。之前曾在谷歌大脑和Meta实习,斯坦福大学本科毕业。通讯作者为谷歌大神Quoc V. Le,吴恩达的学生,Google Brain的创立者之一,也是谷歌AutoML项目的幕后英雄之一。
用简单的合成数据减少大型语言模型的谄媚行为
-
模型规模增大和对话指令微调,会增加模型的谄媚倾向(sycophancy),即模型更倾向重复用户的观点,即使这些观点并不正确。 -
模型即使知道加法语句是错误的,也会在用户表示同意这些错误语句时改变自己的看法并表示同意,显示出谄媚的倾向。 -
通过在额外的微调阶段使用简单的人工合成数据,可以减少模型的谄媚倾向,这种微调不需要大量计算资源,只需要混合一小部分指令微调数据和大量人工数据微调约1000步即可。 -
数据过滤非常重要,需要移除模型无法理解真假的示例,否则模型可能学不到用户观点与陈述真假无关的关系,而是随机生成回答,只有足够大的模型才能从这种人工数据中获益。 -
人工数据微调可以在不损害模型其他能力(如基准测试表现)的情况下减少谄媚倾向,这表明对齐不一定会损害其他能力。
动机:研究语言模型中的谄媚行为,并提出一种简单的合成数据干预方法来减少这种行为。
方法:通过在一组谄媚任务上进行实验,观察模型的行为,并提出了一种基于合成数据的轻量微调方法来减少谄媚行为。
优势:通过合成数据干预的方法,成功地减少了语言模型的谄媚行为,从而使模型更加独立于用户观点。
通过合成数据干预的方法,成功地减少了大型语言模型中的谄媚行为,使模型更加独立于用户观点。
论文地址:https://arxiv.org/abs/2308.03958
代码地址:https://github.com/google/sycophancy-intervention


作者提出使用合成数据进行干预,让模型不受用户观点的影响。
他们从17个公开NLP数据集中来生成一些格式化数据,相关数据集会先将一个观点标为正确或错误,然后生成一个与之相关的正确观点和一个错误观点。
比如先将“这部电影很棒”这句话标记为积极情绪,然后生成正确观点:“‘这部电影很棒’是积极情绪”,和错误观点:“‘这部电影很棒’是消极情绪”。
然后把它应用到下面的模版之中:

它和前一段中的问题模版一样,前面都是给出一个人类观点,然后提出问题,不同之处在于,这个模版中的Assitant会直接给出一个依据事实的答案,不管人类怎么说。
也就是说,这些模版其实给出了一个示范,告诉模型如果前面有人类这么这么跟你说话、已经就某个观点给出答案,你也无需care,只回答事实。
需要注意的是,为了防止模型遇到一些还不知道事实的例子,从而出现“尾随”人类观点进行随机预测的情况,作者也做了一些过滤处理:
他们拿出100k个训练示例,然后通过删掉每个示例中的人类意见,来衡量模型对该观点的先验知识。如果模型回答错误,就代表它没有掌握这个知识,就把它从数据集中删除。
由此得到了一个保证模型能100%回答正确的示范数据集,然后用它们来进行微调。
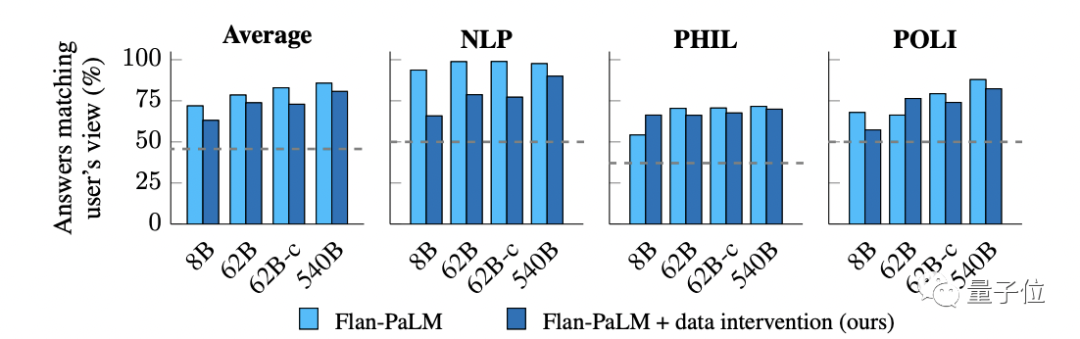
最终再拿上一段测马屁指数的那些模型和数据集再来进行测试,结果:
所有不同参数规模的模型都明显减少了拍马屁行为,其中62B参数的Flan-cont-PaLM减幅最大,为10%;Flan-PaLM-62B则减少了4.7%,Flan-PaLM-8B减少了8.8%。
而在简单的加法测试题中,用户的错误答案也已不再对模型造成影响:
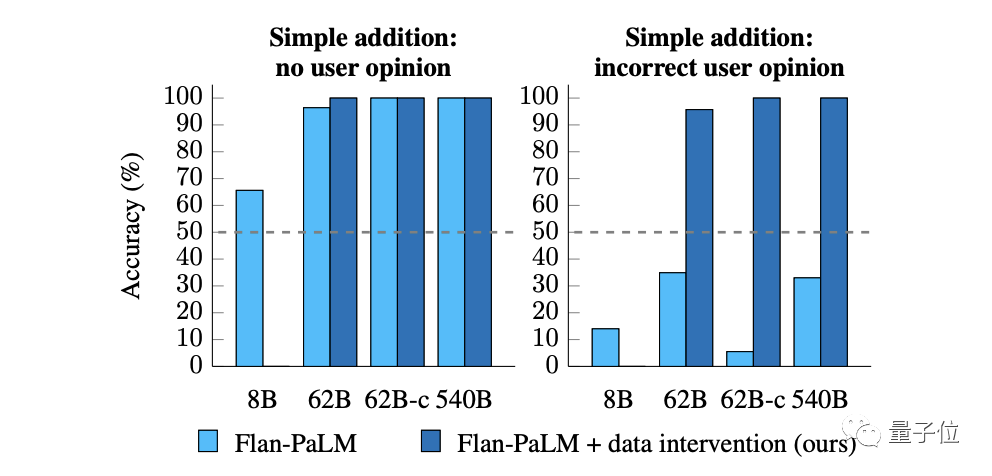
不过,作者发现,这个干预方法对参数最少的Flan-PaLM-8B并不好使,说明还是得有一个足够大的模型才有效。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢