
CoDeF: Content Deformation Fields for Temporally Consistent Video Processing
CoDeF是英文“the content deformation field”的缩写,即作者在此提出了一种叫做内容形变场的新方法,来用于视频风格迁移任务。比起静态的图像风格迁移,这种任务的复杂点在于时间序列上的一致性和流畅度。
本篇论文的目的是提出一种新的视频表示方法——CoDeF,以便于进行视频处理。同时,通过引入一些正则化方法,保证了视频处理过程中的语义一致性。该方法的核心思路是将视频分为静态内容和时间变形两个部分,通过优化这两个部分来重构目标视频。相比现有的视频处理方法,该方法能够更好地保持视频的一致性。
只在一张图像上部署算法,再将图像-图像的转换,提升为视频-视频的转换,将关键点检测提升为关键点跟踪,而且不需要任何训练。相较于传统方法,能够实现更好的跨帧一致性,甚至跟踪非刚性物体。
具体而言,CoDeF将输入视频分解为2D内容规范场(canonical content field)和3D时间形变场(temporal deformation field)
项目链接:https://qiuyu96.github.io/CoDeF/
论文地址:https://arxiv.org/pdf/2308.07926.pdf
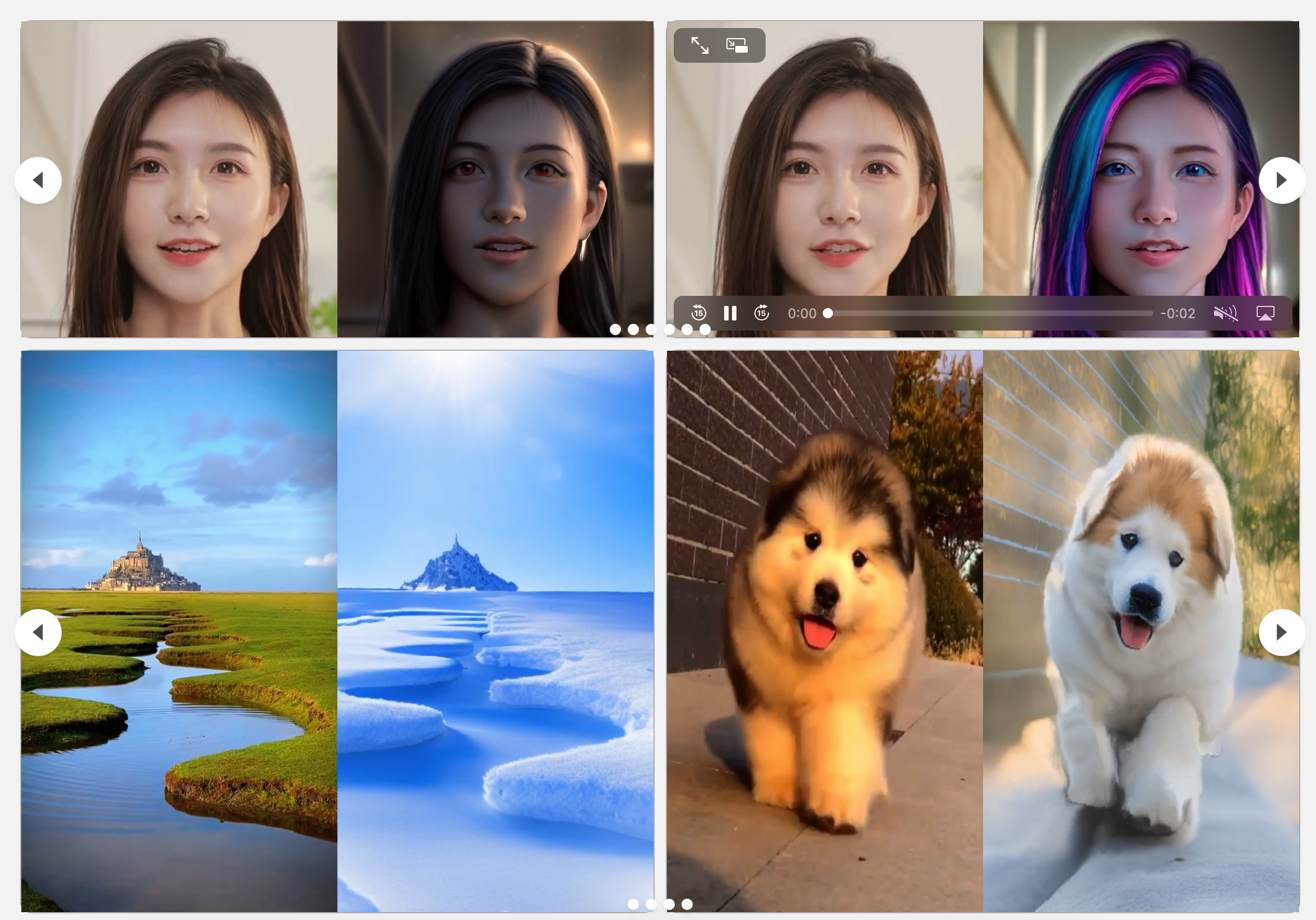
关键思路:CoDeF方法的核心思路是将视频分为静态内容和时间变形两个部分,通过优化这两个部分来重构目标视频。通过引入一些正则化方法,保证了视频处理过程中的语义一致性。该方法的亮点在于,它能够将图像处理的算法扩展到视频处理中,同时能够更好地保持视频的一致性。
其他亮点:本篇论文的实验结果表明,CoDeF方法能够将图像翻译扩展到视频翻译,并且能够将关键点检测扩展到关键点跟踪,而无需进行训练。该方法还能够更好地保持视频的一致性,尤其是在处理非刚性物体(如水和烟雾)时表现更佳。该方法已经开源,项目页面链接为https://qiuyu96.github.io/CoDeF/。该方法值得进一步深入研究。
作者:
Hao Ouyang、 Qiuyu Wang、Yuxi Xiao、Qingyan Bai、Juntao Zhang、Kecheng Zheng、Xiaowei Zhou、 Qifeng Chen、Yujun Shen
香港科技大学、蚂蚁团队、浙江大学CAD&CG实验室
这项研究由香港科技大学、蚂蚁团队、浙江大学CAD&CG实验室共同带来。共同一作有三位,分别是欧阳豪、Yujun Shen和Yuxi Xiao。其中欧阳豪为港科大博士,师从陈启峰(本文通讯作者之一);本科导师为贾佳亚。曾在MSRA、商汤、腾讯优图实验室实习过,现在正在谷歌实习。
另一位是Qiuyu Wang。Yujun Shen是通讯作者之一。他是蚂蚁研究所的高级研究科学家,主管交互智能实验室,研究方向为计算机视觉和深度学习,尤其对生成模型和3D视觉效果感兴趣。
第三位一作为Yuxi Xiao才刚刚从武大本科毕业,今年9月开始在浙大CAD&CG实验室读博。

本文介绍了一种新型的视频表示方法——内容变形场(CoDeF),它由一个聚合整个视频静态内容的规范化内容场和一个记录从规范化图像(即从规范化内容场渲染的图像)到每个单独帧的变换的时间变形场组成。给定目标视频,这两个场通过一个精心设计的渲染管道进行联合优化,以重建目标视频。我们在优化过程中有意引入一些正则化,促使规范化内容场从视频中继承语义(如对象形状)。
这种设计使得CoDeF自然地支持将图像算法用于视频处理,即可以将图像算法应用于规范化图像,并借助时间变形场轻松地将结果传播到整个视频。我们的实验表明,CoDeF能够将图像到图像的转换提升到视频到视频的转换,并将关键点检测提升到关键点跟踪,而无需任何训练。更重要的是,由于我们的提升策略仅在一个图像上部署算法,因此与现有的视频到视频转换方法相比,我们在处理后的视频中实现了更优异的跨帧一致性,甚至能够跟踪非刚性物体,如水和烟雾。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢