
【Allen AI 研究院】跨模态交互模型工作原理深入分析 【论文标题】Does my multimodal model learn cross-modal interactions? It’s harder to tell than you might think! 【作者团队】Jack Hessel ,Lillian Lee,Farzad Khalvati 【发表时间】2020/10/13 【论文链接】https://arxiv.org/pdf/2010.06572.pdf
【推荐理由】
跨模态研究大火,但多模态模型究竟是否学到了模态之间的综合交互作用?在本文中,来自Allen AI 研究院和康奈尔大学的研究人员通过大量的实验说明了多模态模型的成功不一定归功于考虑了跨模态交互,并提出了一种衡量跨模态交互的诊断方法——EMAP。
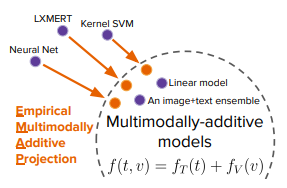
在多模态任务(如视觉问答系统)中,对富有表现力的跨模态交互进行建模是非常重要的。然而,有时性能优异的黑盒模型在很大程度上只用到了数据中单一模态的信号。为此,本文作者提出了一种新的诊断方法——经验多模态加法函数投影(EMAP),用于独立分析模态之间的交互是否能够提升给定模型在给定任务上的性能。这个函数投影修改了模型的预测结果,从而消除了跨模态的交互,独立出了可以相加的单模态结构。
在七个「图像+文本」的分类任务上,本文作者都设置了新的 SOTA 对比基准。实验结果表明,在很多情况下,删除跨模态的交互几乎不会导致性能下降。令人惊讶的是,即使具有考虑交互作用能力的富有表达性的模型具有比表达性较差的模型更好的性能,这种情况仍然存在。因此,即使性能确实有所提升,我们往往也不能将其归因于考虑了跨模态交互。本文作者建议,多模态机器学习领域的研究人员不仅要报告单模态基线的性能,还要报告他们的最佳模型的 EMAP。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢