

作者:Chengsong Huang, Qian Liu, Bill Yuchen Lin, Tianyu Pang, Chao Du, Min Lin 机构:Sea AI Lab, Singapore; Washington University in St. Louis, MO, USA; Allen Institute for AI, Seattle, WA, USA 代码: https://github.com/sail-sg/lorahub
本文提出了LoraHub,这是一种动态组合在各种上游任务上训练的多个LoRA(低秩自适应)模块的方法。其目标是在新的下游任务上,只需要很少的例子,就可以实现适应性的性能,而不需要额外的模型参数或梯度。
该方法有两个主要阶段:
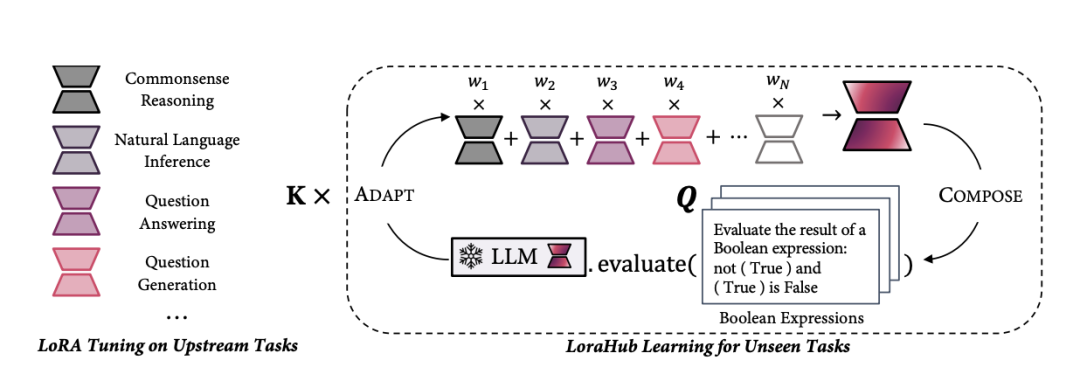
组合:将可用的LoRA模块组合成一个模块,使用可训练的标量权重。这允许流体地组合各种技能。
自适应:对新任务的几个例子评估组装好的模块。使用无梯度算法优化其权重以提高性能。
在Flan-T5上进行的BigBench Hard实验表明,LoraHub可以在使用远少得多的标记时匹配上下文学习的性能,而且优于零样本学习。
LoraHub的组成性和模块性允许轻松共享和重用LoRA模块。这可以支持一个协作平台,可以集体增强LLM的能力。
本文的主要动机是探索LoRA模块的内在模块性和可组合性。 之前的方法通常将LoRA模块特化用于单个任务和域。但是LoRA模块的内在模块性提出了一个有趣的研究问题:是否可以组合LoRA模块来高效地推广到未见过的任务? 本文的主要贡献是利用LoRA模块的模块性进行广泛的任务推广,通过对多个任务上训练的LoRA模块进行有目的的组装,以实现对未见任务的适应性能力。
该方法包含两个主要阶段:
训练:在各种上游任务上单独训练N个LoRA模块,用于任务。
组合:将所有可用的LoRA模块合成一个模块,使用系数。即。这里是一个可正可负的标量权重。
评估:将组装的LoRA模块与LLM 合并,在新任务的少量样本上评估其性能。
优化:使用无梯度黑盒优化算法更新,以提高在少量样本上的性能(例如损失)。
得到最终适合新任务的LLM 。
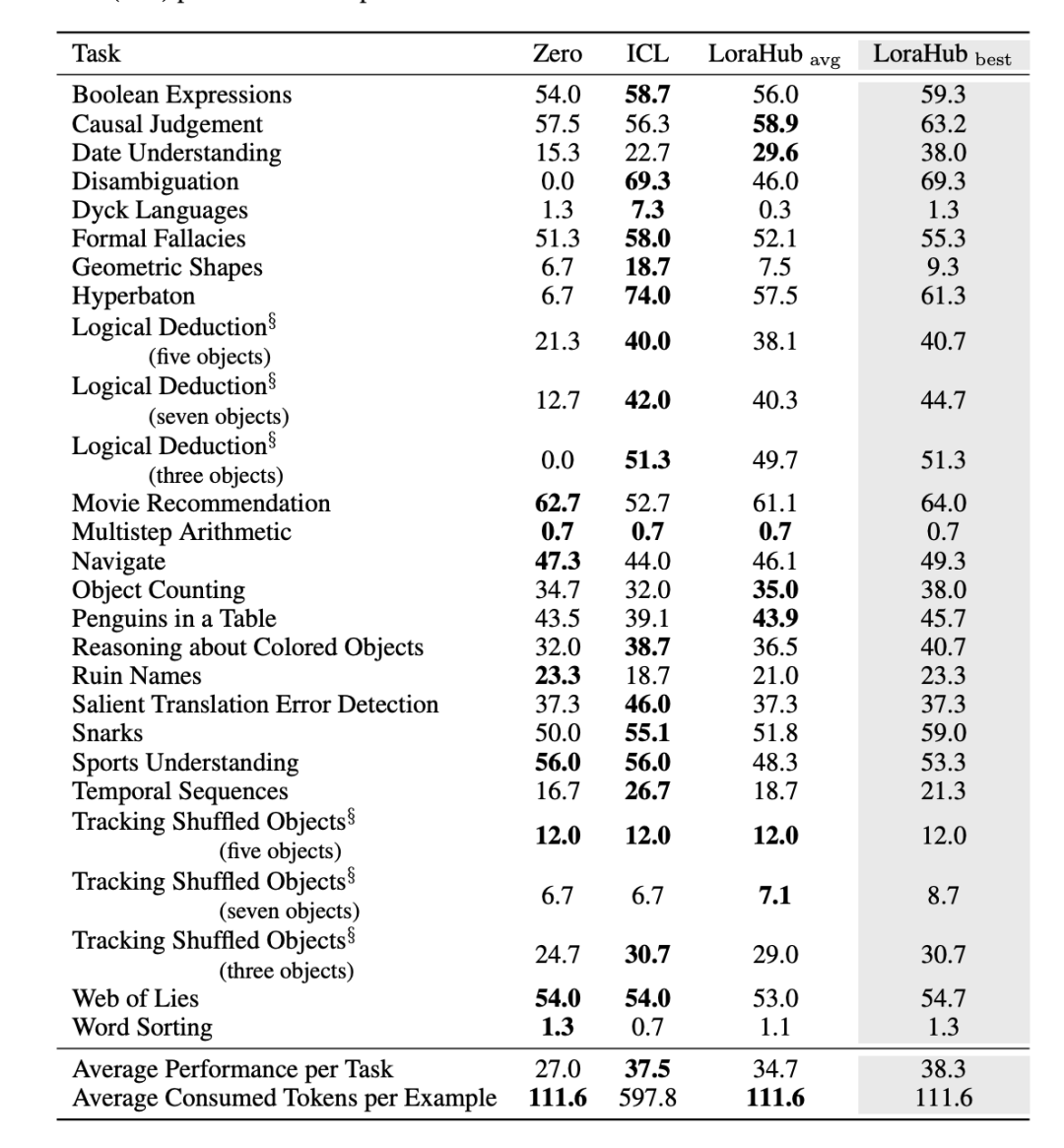
在BigBench Hard基准测试上,与零样本学习相比,该方法实现了更好的性能。
在少样本场景下,该方法可以有效地模仿上下文学习的性能,而无需在每次推理时提供上下文示例。
与上下文学习相比,该方法大大减少了推理成本,无需为LLM提供示例作为输入。
学习过程计算高效,使用无梯度方法获得LoRA模块的系数,对未见任务只需要很少的推理步骤。
本文提出了LoraHub,这是一个新的框架,通过对多种任务上的LoRA模块进行有目的的组装,以实现对新任务的适应性能力。该方法仅需要很少的示例就可以自动组合多个LoRA模块,无需人工专业知识。实验结果表明,LoraHub可以在少样本场景中有效地模仿上下文学习的性能,而无需在每次推理时提供上下文示例。总的来说,本文表明了LoRA组合的战略性,可以用于快速适应LLM到各种任务,模块的重用方法可以帮助建立更普适和适应性强的LLM。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢