
论文题目:LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models 作者:Zhiqiang Hu, Yihuai Lan, Lei Wang等 机构:新加坡科技设计大学,新加坡管理大学等 代码:https://github.com/AGI-Edgerunners/LLM-Adapters

本文提出了LLM-Adapters,一个将各种适配器集成到大型语言模型中的框架,可以用于不同任务的参数高效微调。该框架包含了最先进的开放访问大型语言模型,如LLaMA、BLOOM、OPT和GPT-J,以及广泛使用的适配器,如串联适配器、并行适配器和LoRA。
该框架设计在研究,efficient、模块化和可扩展方面表现良好,允许集成新的适配器和用新的更大规模的语言模型进行评估。此外,为了评估LLM-Adapters中的适配器的有效性,作者在6个数学推理数据集上进行了实验。
结果表明,在简单的数学推理数据集上,使用较小规模语言模型(7B)的参数高效微调仅需要很少的可训练参数,就能达到强大语言模型(175B)在零样本推断中可比性能。总体而言,作者提供了一个有希望的框架来微调大型语言模型用于下游任务。
大型语言模型(LLM)在各种自然语言处理任务中展现出了强大的能力。但是目前最强大的LLM往往是封闭源代码的,无法供研究人员直接使用。为了解决这个问题,一些研究尝试使用指令学习的方式针对开放源代码的LLM进行微调。但是LLM的参数数量巨大,使得全量微调非常困难。因此,本文提出了LLM-Adapters框架,集成了各种适配器技术,可以仅调整很少的外部参数而不改变LLM本身的参数,从而实现参数高效的微调。该框架的主要贡献是:1)提供一个友好的LLM适配器研究平台;2)评估不同适配器在数学推理任务上的效果。
本文框架包含3种适配器:
串联适配器(Series Adapter):在每个Transformer块的多头自注意力层和前馈层后串联地添加瓶颈前馈层,如图1(a)所示。
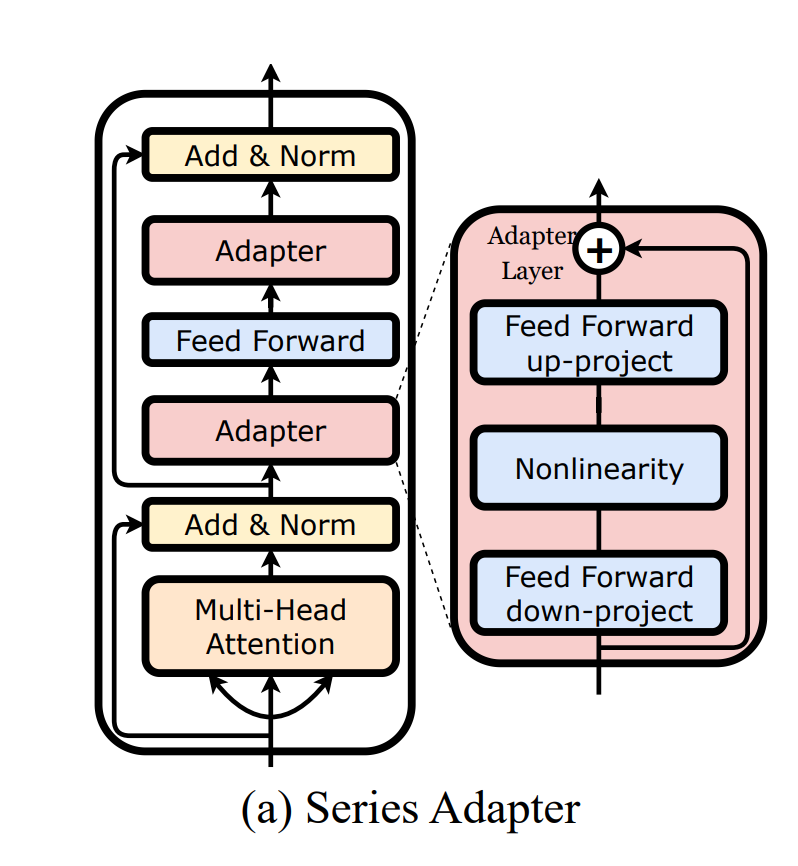
其中,
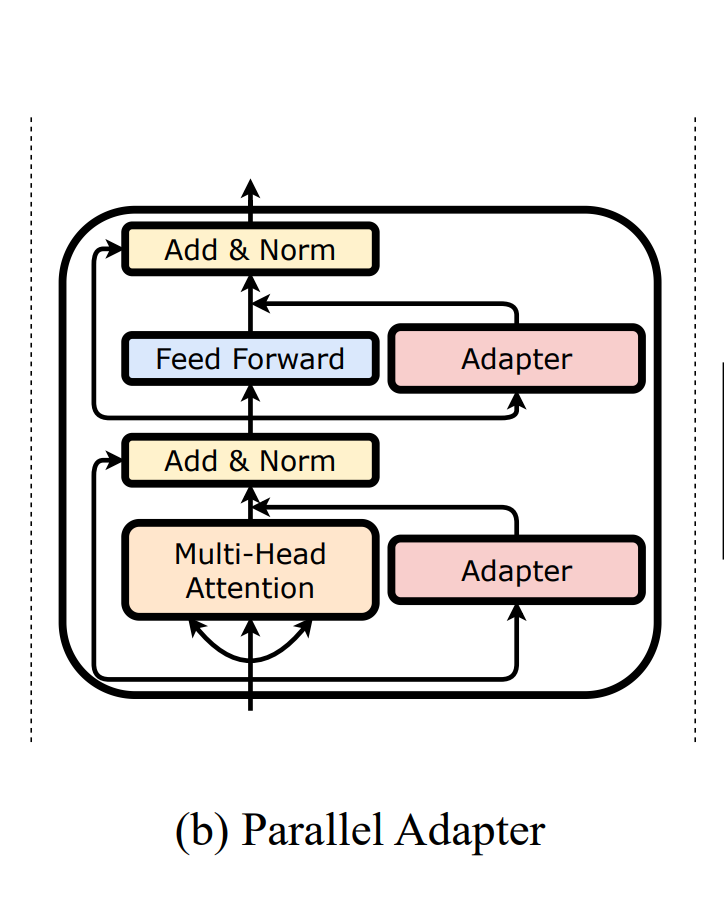
并行适配器(Parallel Adapter): 如图1(b)所示,将瓶颈前馈层与每个Transformer层的多头自注意力层和前馈层并行地集成。
LoRA:如图1(c)所示,向现有层中注入低秩可训练矩阵,实现参数高效微调。
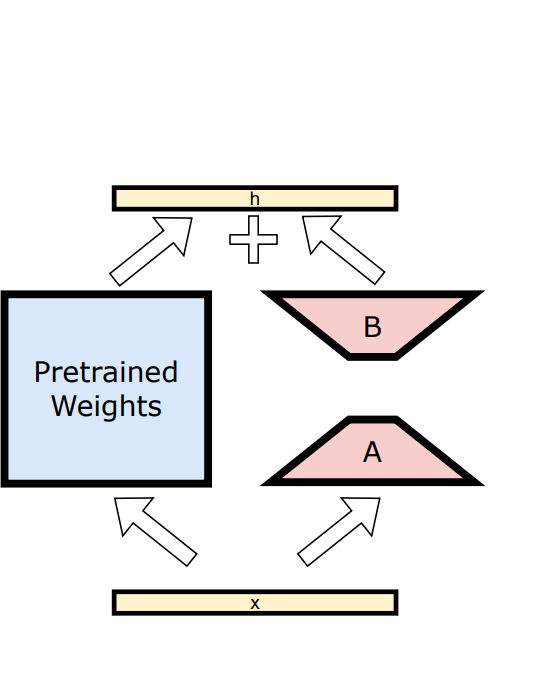
其中,和为低秩矩阵。
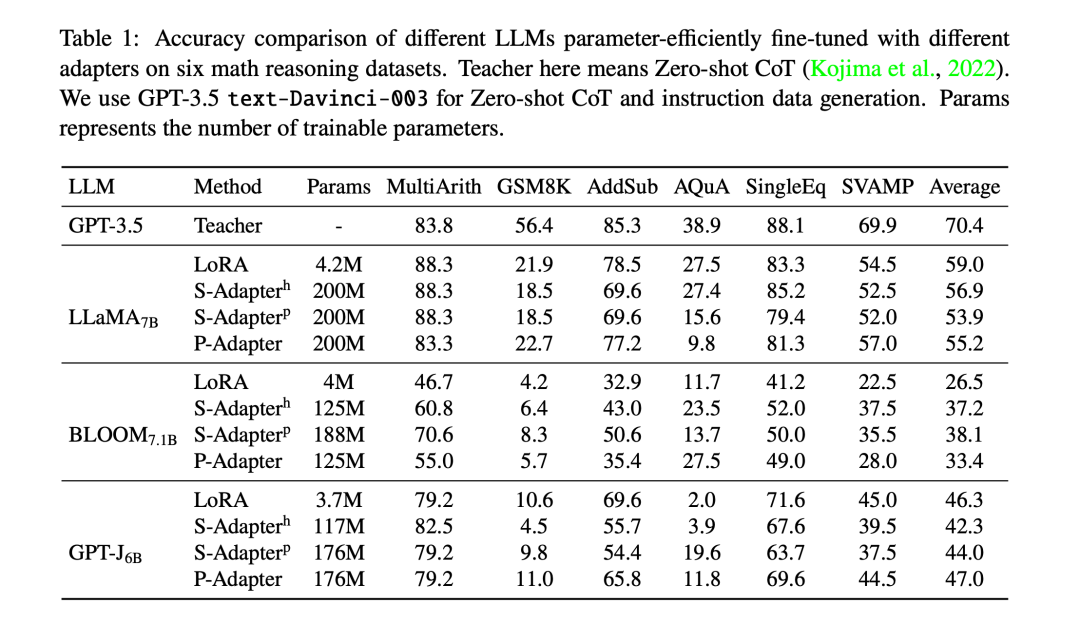
在6个数学推理数据集上比较了不同适配器的参数高效微调效果,发现在简单的任务上,较小LLM(7B)的参数高效微调能达到大LLM(175B)在零样本推断的可比性能。另外,LoRA由于需要的参数更少,效果也较好。
本文提出了LLM-Adapters框架,集成了多种适配器技术用于LLM的参数高效微调。实验表明该框架能够使较小规模LLM在简单任务上实现与大规模LLM可比的性能。未来工作将集成更多适配器和语言模型,在更多任务上进行评估。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢