Intetix Foundation(英明泰思基金会)由从事数据科学、非营利组织和公共政策研究的中国学者发起成立,致力于通过数据科学改善人类社会和自然环境。通过联络、动员中美最顶尖的数据科学家和社会科学家,以及分布在全球的志愿者,我们创造性地践行着我们的使命:为美好生活洞见数据价值。
>> 原文
Dimitris Bertsimas, Margret V. Bjarnadottir, Michael A. Kane, J. Christian Kryder, Rudra Pandey, Santosh Vempala, and Grant Wang. (2008). Algorithmic Prediction of Health-Care Costs. Operations Research, Vol. 56, No. 6: 1382-1392.
1
医疗成本的不断上升是当今最紧迫的世界性问题之一。因此,准确预测相关费用是解决这一问题的关键性第一步。自上世纪80年代以来,基于(医疗保险)运用启发式规则和回归方法得到的索赔数据来搭建预测模型的研究就已经不断进行。然而,这些方法都没有得到适当的验证而且这些方法的使用规则并没有明确。我们利用分类树和聚类算法等现代数据挖掘方法,对超过八十万位投保人的索赔数据进行历时超三年的跟踪,然后根据头两年的医疗和成本数据,在第三年时提供严格的医疗成本验证预测。我们使用来自超过二十万名成员不可见(样本外)的数据,来量化我们预测的精度。关键结论有:(一)我们的数据挖掘方法可得到了医疗成本准确预测,这代表了这方法是对医疗成本预测的一大强而有效工具;(二)过去的成本数据模式可对未来的成本预测提供很有利的帮助;(三)医疗信息仅有助于准确预测高消费人群的医疗费用。在医疗研究上(医疗保险)索赔数据的价值往往会受到质疑(Jolins et al. 1993, Dans 1993)因为这些数据库是用于财务方面而非临床用途。然而,索赔数据已在许多场合显示出作用,而且越来越常用于医学研究。研究的例子有坚持用药的疗效差异(Pladevall 2004),识别住院并发症(Lawthers et al. 2000),疗程长度(Mehta et al. 1999),与医疗疗效(Wennberg et al. 1987)。Jones(2000)很好地总结了统计方法在与医疗数据结合时的一般使用方法,而其他出版物,包括Zhou et al. (1997) and Manning and Mullahy (2001),解决卫生保健成本数据问题。
索赔数据的预测能力在上世纪80年代成为一个研究课题(Zhao et al. 2005),而且许多研究已经开始摸索管理数据对医疗费用的预测能力(Ash et al. 2000, Zhao et al. 2001, Farley et al. 2006, Zhao et al. 2005)。Van de Ven and Ellis (2000)针对2000年前基于风险的预测模型的发战,做出具有洞见性的概述。Cumming et al. (2002) 提出了一种在保险业的风险评估和人口卫生保健成本预测上发展出来的比较不同的预测模型。这个模型比较了诊断和处方数据的使用,并且该研究进一步验证了索赔数据的预测能力。早期研究人员集中精力研究经典回归模型在预测总的医疗费用,或逻辑回归模型(LaVange et al. 1986, Roblin et al. 1999),以确定高风险的成员时的使用(Zhao et al. 2005, Ash et al. 2000, Zhao et al. 2001, Powers et al. 2005)。通常研究是把这些回归模型与启发式分类规则相结合来工作。但将创建管理数据合并症分数作为一个在医学研究上比较种群合并差异的方法(Klabunde et al. 2002),来设计合理的还款计划(Van de Ven and Ellis 2000, Dunn et al. 2002) 并作为预测模型的医疗费用的基础(Ash et al. 2000, Farley et al. 2006, Chang and Lai 2005),这也能起到显著的作用。许多预测卫生保健费用,并根据索赔数据以外的数据的研究是可行的;例如Fleishman et al. (2006)和 Pietz et al. (2004)。在我们看来,描述一个方法的可预测性,最好的方式是使用不同的性能指标去进行样品外实验(即使用该方法所没有的数据)。为了我们能够理解,大多数早期的回归研究都不报告样本外实验中方法的可预测性,除少数例外(Powers et al. 2005, Dove et al. 2003)。传统地来讲(Cumming et al. 2002),R2或修正后的R2是作为评估预测模型的措施,但他们的使用也有一些严重的缺点,这在我们看来是不适合用于研究的。R2测量是相对的,不是绝对的,是一个合理测量。它衡量的回归线与一个恒定的预测相比,可改善的预测性比例(用残差平方和来测量)(用例参考 Bertsimas and Freund 2005)。特别是,基于R2的比较可以在在相同的数据集中不同的回归模型的比较中起到作用,但它并不表明与其他方法(如本文我们利用的方法)相比R2更有效果。基于成本预测的目的(医疗干预,合同定价等.),不同的纠错措施可能比R2更合适、更有效。因此我们定义了新的纠错措施,这能更好地描述在各种不同的方式下的预测精度。本文的目的是利用现代数据挖掘方法,具体地来说就是运用分类树和聚类算法,对超过八十万位投保人的索赔数据进行历时超三年的跟踪,然后根据头两年的医疗和成本数据,在第三年时提供严格的医疗成本验证预测。我们应用一个有二十多万名成员的测试样本搭建起的模型来量化精度。关键结论有:(一)我们的数据挖掘方法可得到了医疗成本准确预测,这代表了这方法是对医疗成本预测的一大强而有效工具;(二)过去的成本数据模式可对未来的成本预测提供很有利的帮助;(三)医疗信息在使用的聚类算法时增加了预测精度,而运用分类树时,成本信息仅作用于相似的纠错措施。本文其余部分结构如下:在§2, 我们描述了数据和定义了我们认为需要的性能指标;在§3,我们提出我们使用的两种主要方法:分类树和聚类算法;在§4,我们分别报告了分类树和聚类算法在预疗医疗成本时的性能;在§5,我们简要地阐述了我们的结论与未来的研究方向。本研究采用的是医院和其他卫生保健提供者声称是第三方纳税人对他们的服务反馈时产生的医疗数据。研究期间为:从8 / 1 / 2004–7 / 31 / 2007,,从8 / 1 / 2004–7/ 31 / 2006是24个月的观察期,从8 / 1 / 2006–7 / 31 / 2007是12个月的结果期。 我们的数据集包括838242位商业保险人口和2866位在全国各地雇主和其团体的医疗索赔数据,医疗和药品的要求,以及个人(他或她的家庭)被保险政策所覆盖期限的信息。数据还包含基本的人口统计信息,如年龄和性别。所有成员都不迟于8/ 1 / 2005开始被保和不早于8 / 1 / 2006结束被保,而所有雇主需有持续覆盖期限,不迟于8 / 1 / 2005和不早于8 / 1 / 2007。这确保了每一位员工(及其家人)在观察期内至少有12个月的数据,因此在雇主的保险载体的变动影响下也不会有大量人群在结果期退出。在838242名成员中,有730918名在结果期外仍有资格。不同的是,在结果期内,有超过108000名或说13.8%以上人口退出。这是通常是由于员工的营业额,预计每年约有15%。其中一小部分,大约3000名成员(基于人口的性别和年龄分布),没有完全覆盖的原因是由于死亡。我们的分析表明,包括在结果期局部覆盖的人口改善了纠错措施,因此,出于简洁,我们在结果期用全面覆盖的人数,建立我们的模型,并报告这些结果。我们拆分的数据集,随机分配为三个同等大小的部分:学习样本,验证样本,测试样本。学习样本是用来建立我们的预测模型,而验证样本是用来评估各种模型的性能。测试样本在建立和校准模型时搁置,只用在实验最后的行为模型报告结果中。我们认为,这种方法良好地验证了我们的结论。索赔包括诊断、手术和药物信息。诊断数据使用ICD-9-CM代码(疾病国际分类法,第九次修订,临床修订版)编码,(医疗保险和医疗补助服务中心,2004)这代码是医学诊断和程序的通用代码。该程序能在各种编码方案下被编码:ICD9, DRG, 转速编码,CPT4,和HCPCS----共有超过两万两千种代码。此外,数据还包括药房索赔,也就是说,它包含的信息,在存在的情况下,处方(和某些非处方)药作为健康计划的一员被吸纳,已有45972个药物条码被编码(国家药品代码目录,2004)。索赔数据依赖于专业的卫生保健人员用ICD-9-CM代码来编码它们的诊断和程序。虽然医疗索赔的编码始于一位临床医师,但是它最常由一个独立的专用计费运营商来完成和提交。由于实践和可知减少数据所能得到的更易于管理的规模这俩依据,可得解释中不可避免的变化,所以我们选择使用编码组,而非独立代码。我们减少了超过一万三千个个人诊断至218个诊断组。医疗程序和药物类别同样做了分组。超过两万两千个个人程序被分为180个程序组,四万五千多的个人处方药被分为336个治疗组。在分析中还包括超过700个指定危险临床情况的医疗质量和风险的措施(例如,一个未去诊所就诊的ER模式患者,与足溃疡的糖尿病患者等)。我们也计算诊断、程序、药物以及每个人存在的危险因素的数量,并把它们加入作为附加变量。总之,预测性医疗变量包括:诊断组,程序组,药物组,我们开发的风险因素,及其数量,总共接近1500个可能的医疗变量。我们建议读者在在线附录A和D中获取更多细节。本文的电子附录可在线获取,网址为http://or.journal.informs.org/。
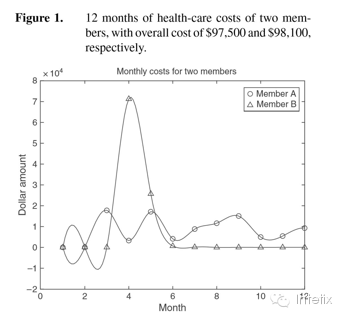
除了医疗变量,我们还利用22个成本变量,因为我们相信成本信息提供了一个个体健康状况的全局图。我们将年龄和性别也包括进来。要捕捉的医疗成本的变化轨迹(作为整体医疗条件的代表),我们使用观察期内最近12个月的每月费用数据,总的药物成本和整个观察期内总的医疗成本,以及观察期最后三个月和最后六个月的整体成本。此外,为捕捉成本模式,我们提出了一个新的指标变量,这个变量可判断捕捉到的成员成本模式是否呈现出“尖峰”模式,即突然增加后随及猛然下降的成本曲线。为了说明这个想法,让我们研究Figure 1,它描述了在观察期过去12个月内2名成员的每月成本。虽然每个成员都有大概98000美元的索赔费用,但是成员A具有相对较高的恒定医疗费用(一个慢性病人的典型模式),而成员B的成本曲线轮廓有一个尖峰(一个急性病人的典型模式)。在这里的关键思想是,尽管较高的医疗费用在未来有一个明显的重复趋势,但是一个尖峰成本模式在未来较高的医疗成本中可能有较低的风险:例如怀孕并发症,意外或急性医疗情况,如肺炎或阑尾炎。 注释:一个三次样条曲线是为了数据的方便查看。,成员A的成本曲线有慢性疾病的特点,而成员B的成本曲线特点是急性的。成员A最贵的诊断索赔是淋巴瘤和呼吸衰竭。成员B最高索赔产生的原因是劳动并发症。
除此之外,我们采用了以下四个变量:每月的最大成本,高于平均成本的月份数,在观察期过去数月的正趋势和负趋势。
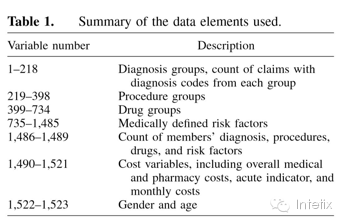
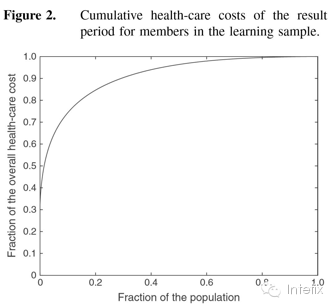
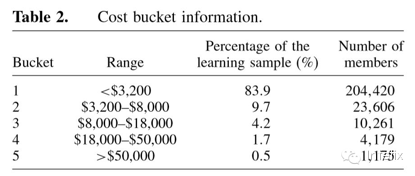
最后,我们使用了性别和年龄作为附加变量。Table 1总结了在研究中所用的所有变量,并在附录A中提供了更多细节。在学习样本的结果期中,成员的支付金额从0美元到710000美元不等。人口的累积成本呈现出一些已知的特点:人口总成本的80%来源于仅20%的最昂贵成员。Figure 2显示我们人口的成本特征。对于我们的样本,我们注意到约8%的人口就占了总医疗费用的70%。注释:X轴是人口累计百分比,Y轴是整体医疗费用累计百分比。从图中我们注意到8%的人口(最高消费成员)占整体医疗费用的70%。在减少极端昂贵成员(可被认为是异常值)的同时,可降低误差在数据中的影响,我们将成员的费用曲线划分为5个不同波段或成本栏。我们这样划分可使所有成员费用的总和在每个栏中大致相同的,即每一个栏的总金额是相同的(每个栏大约1.17亿美元)。我们选择了5个栏是因为它确保在最昂贵的栏中会员数量足够大(在第五个栏的学习样本中我们有1175位成员)。Table 2显示了每一个栏的范围,百分比,以及每个栏中学习样本的成员数量。注释:成本栏的范围和每一栏学习样本中的分数(计算出观察期最后12个月的费用)。任何一个栏中成员费用的总和在1.16至1.19亿美元之间。
对专业健康护理管理人员来说,预测栏是有价值的。栏1至5可以解释为低,新兴,中等,高,和非常高风险的医疗并发症。在栏2和3的成员预测将是健康计划的候选,在栏4的成员预测是疾病管理计划的候选,而那些最昂贵的成员预测栏是情况管理方案的候选,同时也是病人护理项目最困难的类型。
我们测量我们模型性能有三个主要的纠错措施:命中率,罚差,绝对预测误差(APE)。为了能够将我们的结果与已发表的研究相比较,我们还引入了R2和截断R2,并介绍一种新的相似性度量∣R∣。我们在§2.4.2提供了一些关于R2额外的见解,还在§2.4.1定义了新的误差纠正措施。
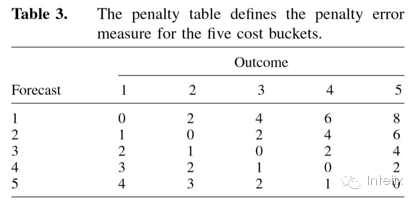
命中率:我们定义命中率是我们预测成本项目正确时的成员的比例。罚差:罚差是出于医疗干预的机会而提出的,因此是非均匀的。低估更高成本会有更大的惩罚,这与无视这些个体更大的医疗和金融风险相一致。错误地将实际成本较低的个人识别为高风险的处罚,会轻于相反的情况,因为这种情况损害或产生费用小。因此,低估了成本栏的处罚会比高估重一倍。这是由于医生的估计机会损失而造成。Table 3显示的5个成本栏的方案惩罚表。我们定义罚差措施是为每一个给定的样本成员制定平均预测处罚。
绝对预测误差:绝对预测误差究其根源是来自实际医疗保健成本。我们定义绝对预测误差是预测(年)金额及实现(年)金额之间的平均绝对差。举个例子,如果我们预测一个成员的医疗保健成本在结果期是500美元,但现实中这成员有2000美元的整体医疗成本,那么该成员的绝对预测误差为︱$500−$2000︱=$1500。我们定义绝对预测误差(APE)是在给定样本下的平均误差。APE已经在最近的研究(Cumming et al. 2002, Powers et al. 2005, Dunn et al. 2002)里与传统的R2一同使用。APE的一个优点是它不与预测误差一致,这使得它对异常值(有极端医疗成本的成员)不敏感。特殊关注这个优点是由于医疗成本数据的性质,因为总有一些个别成员具有难以预测的高成本情况。
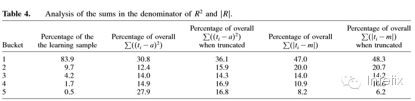
如果我们观察在观察期成本栏中成员贡献的标准总和,会发现它的变化很大,如Table 4。第二列有每个栏中学习样本的分数,第三列有分母对总和的贡献。我们注意到总和的27.9%是由在观察期内第5栏0.5%的成员贡献的。因此,R2是不受成员中最昂贵栏非均匀影响的。注释:对R2和︱R︱纠错措施的标准总和的作用就像在观察期最后12个月的成本栏的函数。(数字是基于测试样本。)
R2可纠正每个预测误差,这使得它对高医疗成本成员的预测误差非常敏感。因此一个对大多数人群都适用良好的模型,可能由于一些极端而且难以预测的异常值导致低R2。(例如一个突然发病且情况严重的成员)在文献中,研究人员已经用医疗成本截断来解决案例。我们认为当索赔成本用R2100截断为十万美元时导致R2结果,同时Table 4的第四列显示了这案例中对标准总和的贡献。通过截断这些成员,在第五栏标准总和的贡献降到16%,接近栏2至4。
医疗成本预测的自然测度是预测误差的绝对值。因此我们定义了一个新的R类似措施,这措施与R2相比有一些相同的属性, 当我们预测对所有成员样本中值时,︱R︱=0;如果对所有i值有ti =fi,有︱R︱=1。同理,R2测量残差平方减少量,︱R︱测量残差绝对值之和的减少量。在Table 4的最后两列,我们总结了对︱R︱标准人口总和的贡献。我们注意到,在观察期的栏中,贡献是严格递减的,并且受截断的影响较小(注意︱R100︱)。我们的结论是︱R︱相对R2,对异常值没那么敏感,因此可能更适合于医疗保健的成本预测。加群:加入全球华人OR|AI|DS社区硕博微信学术群
资料:免费获得大量运筹学相关学习资料
人才库:加入运筹精英人才库,获得独家职位推荐
电子书:免费获取平台小编独家创作的优化理论、运筹实践和数据科学电子书,持续更新中ing...
加入我们:加入「运筹OR帷幄」,参与内容创作平台运营
知识星球:加入「运筹OR帷幄」数据算法社区,免费参与每周「领读计划」、「行业inTalk」、「OR会客厅」等直播活动,与数百位签约大V进行在线交流
文章须知
作者:D. Bertsimas 等
责任编辑:Shutian Li
微信编辑:疑疑
文章由『运筹OR帷幄转载发布
如需转载请在公众号后台获取转载须知



内容中包含的图片若涉及版权问题,请及时与我们联系删除




评论
沙发等你来抢