

题目:面向结构的图Transformer用于图表示学习
作者:Dexiong Chen, Leslie O’Bray, Karsten Borgwardt
机构:瑞士苏黎世联邦工业大学生物系统科学与工程系,瑞士生物信息学研究所
Transformer架构在图表示学习中受到越来越多的关注,因为它通过避免图神经网络的结构化偏置,而通过位置编码来编码图结构,从而自然地避免了图神经网络的几个局限。
但是,Transformer仅使用位置编码无法保证生成的节点能够捕获节点之间的结构相似性。为解决这个问题,作者提出结构感知Transformer, 它建立在一种自注意力机制之上。
这种自注意力通过在每个节点提取以其为中心的子图表示,然后再计算注意力,从而将结构信息整合到原始自注意力中。
作者提出了自动生成子图表示的几种方法,理论上保证生成的表示至少与子图表示一样表达能力。
实验证明该方法在5个图预测基准测试中实现了2022年ICML之前sota性能。结构感知框架可以利用任何存在的图神经网络来提取子图表示,并且相对于基础图神经网络模型系统地改进了性能,成功地结合了图神经网络和Transformer的优点。
图神经网络通过消息传递机制聚合局部邻域信息来生成新表示。但是这类基于消息传递的图神经网络存在表达能力有限、过度平滑和过度压缩等问题。因此设计新型的超越邻域聚合的架构对解决这些问题至关重要。
Transformer架构通过自注意力层捕获任意节点对之间的交互信息,而不是仅聚合局部邻域信息,从而避免引入中间层的任何结构化偏置,解决了图神经网络的表达能力有限问题。
Transformer仅通过位置编码将结构或位置信息编码到输入节点特征中,而不是在中间层明确建模图结构。因此将结构信息整合到Transformer架构中备受关注。但是大多数现有方法仅编码节点之间的位置关系,而不是显式编码结构关系。因此,它们可能无法识别节点之间的结构相似性,从而无法对图中的结构交互进行建模。这可能解释了它们在某些任务中的表现不如稀疏图神经网络。
本文的主要贡献是引入一种灵活的结构自注意力机制,它显式考虑图结构,从而捕获节点之间的结构交互作用。与大多数仅针对位置的现有图Transformer形成对比,它可以提供对图结构感知的表示。具体来说,通过将自注意力机制改写为核平滑器,并将原始的指数核扩展到还考虑局部结构,通过提取每个节点周围的子图表示,从而实现结构感知的自注意力。作者提出了自动生成子图表示的几种方法,理论上保证生成的表示至少与子图表示一样表达能力。实验证明提出的方法实现了在多个基准测试上的最优性能。
Transformer的自注意力机制可以看作一个核平滑器:
其中是线性值函数,是在上的非对称指数核。
为同时捕获结构相似性,作者考虑更广义的核,其中引入每个节点的以为中心的子图表示:
其中
是提取以为中心的子图的表示的结构提取器。
作者提出了几种结构提取器:
k-subtree GNN extractor: 对输入图运行GNN,以每个节点的GNN表示作为其子图表示 k-subgraph GNN extractor: 对每个节点的k跳子图运行GNN,并汇总其包含节点的GNN表示作为该节点的子图表示
结构感知自注意力后接残差连接、前馈网络和规范化层组成结构感知Transformer的一个层。多个这样的层叠加构成完整的结构感知Transformer模型。
对两个节点和的代表性,作者证明了它们的结构感知自注意力表示的距离受到它们对应的子图表示的距离的约束,即如果两个节点的子图表示不同,那么它们的结构感知自注意力表示也不同。这确保模型能够捕获节点之间的结构相似性。
此外,作者还理论证明了结构感知自注意力层的表达能力至少与其结构提取器的表达能力一样强。
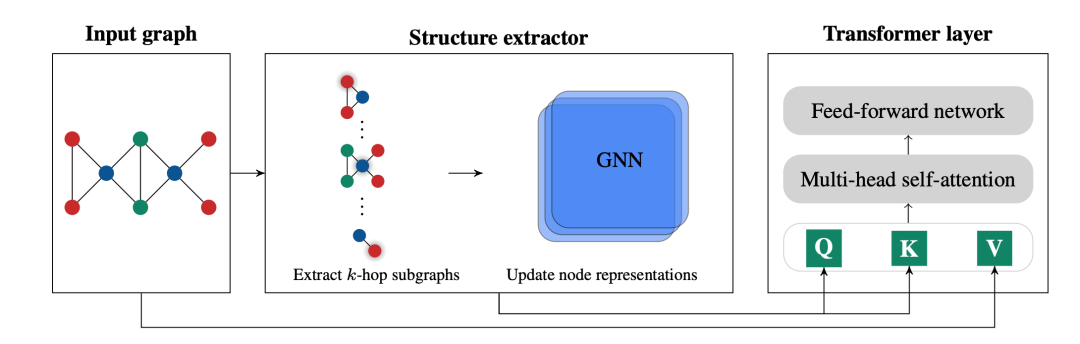
图2展示了结构感知transformer的一个示例层的示意图,其中使用k跳子图GNN提取器作为结构提取器。具体步骤包括: 1.输入图;2. 结构提取器部分。先提取每个节点的k跳子图(这里k=1),然后对每个子图运行GNN,生成融合了子图信息的节点表示;3. 将包含子图信息的节点表示作为transformer层中Query(Q)和Key(K)矩阵的输入;4. Transformer层包含多头自注意力、残差连接、前馈网络等模块。其中自注意力使用了结构感知的节点表示Q和K来计算;输出更新后的节点表示。
该图展示了结构提取器如何为Transformer层提供结构感知的节点表示,这是实现结构感知自注意力的关键。尽管这里演示的结构提取器基于k跳子图,但结构提取器可以是任何能为每个节点生成子图表示的函数。
作者在五个中等规模的图预测数据集上评估了结构感知Transformer的性能。主要发现包括:
结构感知框架实现了在图分类和节点分类任务上的最先进性能,优于当前最先进的图Transformer和稀疏图神经网络
使用k-subtree和k-subgraph作为结构提取器的两个结构感知Transformer实例始终优于它们所基于的图神经网络模型,突出了结构感知方法改进了表达能力
与仅利用节点属性相似性的经典Transformer相比,结构感知自注意力机制带来了显著的性能改进。使用较小的k值就能获得好的性能,没有过度平滑或过度压缩的问题
绝对位置编码和汇聚方法的选择可以提高性能,但程度远小于引入结构信息
作者引入了结构感知Transformer,成功地将结构信息整合到了Transformer架构中,克服了绝对编码的局限。除了在最小的超参数调优下实现最先进的实证表现,结构感知Transformer还提供了比经典Transformer更好的模型可解释性。结构感知Transformer框架灵活通用,可以与任何现有的图神经网络组合使用,是一种系统的提升任何图神经网络的方法。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢