
DeepAR: Probabilistic forecasting with autoregressive recurrent networks
概率预测是一个关键工具,它可以根据过去的数据估计时间序列的未来概率分布。在零售业务中,概率性需求预测对于在正确的时间、正确的地点保持适当库存至关重要。
模型的出发点在于应用深度学习技术来解决传统方法在预测问题上面临的许多挑战。通过对大量相关时间序列的训练,模型可以学习到复杂的时间序列模式,从而更准确地预测未来的概率分布。与传统方法相比,模型在需要较少的手动工作的情况下能够生成更准确的预测。
是一种基于自回归递归神经网络的概率预测方法,用于处理具有不同速度分布的多个时间序列的挑战性问题。通过适应性地调整模型架构,能够更好地应对这些挑战,从而提供更准确的预测结果。
RNNs是一类使用递归结构来建模时间序列数据的神经网络,其中隐藏层的状态在每个时间步都会更新,以捕捉时间依赖性。
,
其中表示系统在时间步的状态,表示转移函数的参数。
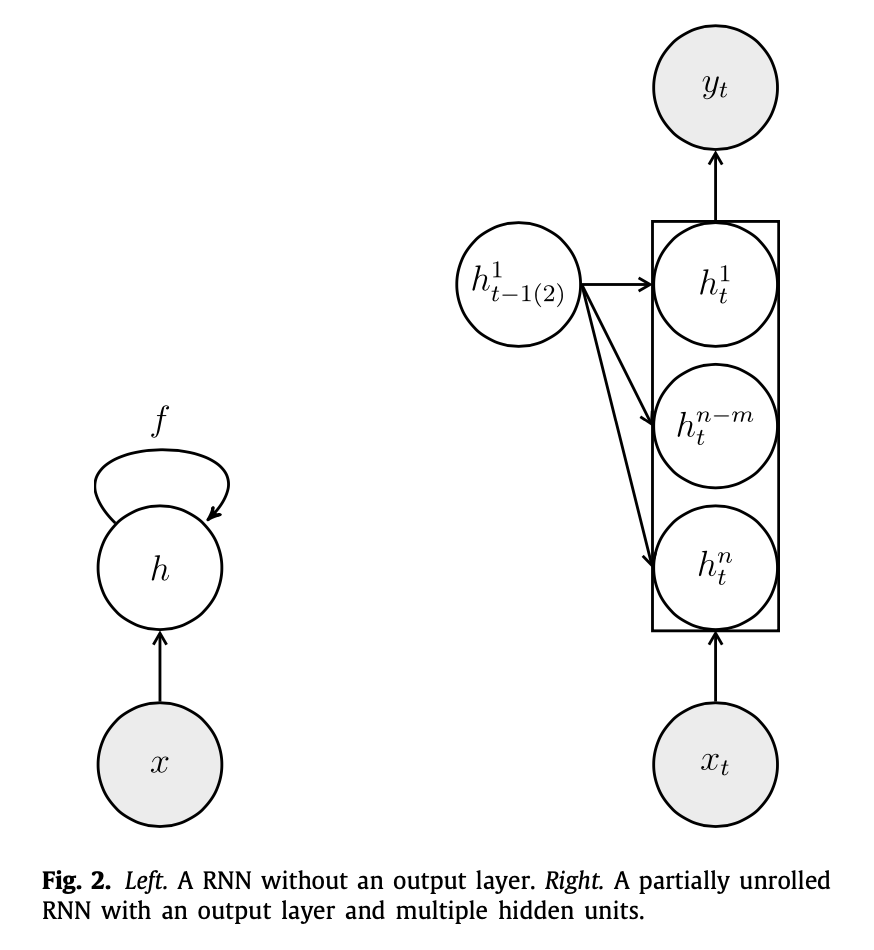
RNN的递归结构意味着需要学习的参数较少,但在通过梯度优化过程训练RNNs时会出现技术难题。RNNs的递归性质经常导致病态优化问题,长短期记忆(LSTM)模型缓解了这个问题,同时具有其他有利的性质。
DeepAR目标是建立一个能够预测每个时间序列(项目)在未来时间点的条件分布,即:
其中:
表示未来时间点的时间序列值 表示过去时间点的时间序列值 是已知的协变量 表示从该时间点开始, 在预测时是未知的。
为了限制混淆,文中避免使用“过去”和“未来”这些术语,将时间范围 称为条件范围,时间范围 称为预测范围。
在训练过程中,这两个范围都必须位于过去,以便观测到 。但在预测时, 只在条件范围内可用。需要注意的是,时间索引 是相对的,即 对应于每个 的不同实际/绝对时间段。
DeepAR基于一个自回归循环网络架构,模型的核心是一个自回归的循环神经网络,其中隐藏层状态会在每个时间步进行更新,以捕捉时间序列数据的时间依赖性。模型的目标是学习一个联合分布:
模型参数 被用来定义似然分布:
模型中的信息从条件范围传递到预测范围,这是通过初始状态 实现的。
通过模型参数 ,可以通过抽样直接获得联合样本 ,该样本满足分布:
在预测时,首先计算得到初始状态 ,然后从似然分布中进行采样,以获得未来时间点的样本。
似然 确定了“噪声模型”,应该选择与数据的统计特性相匹配的模型。在DeepAR中网络直接预测下一个时间点的概率分布的所有参数 (例如均值和方差)。
DeepAR考虑了两种选择:
对于实值数据,选择高斯似然; 对于正数计数数据,选择负二项分布似然。也可以使用其他似然模型,
使用均值和标准差对高斯似然进行参数化,,其中均值由网络输出的仿射函数给出,标准差通过应用仿射变换后紧接着进行 softplus 激活来确保 :
负二项分布是对正数计数数据的常用建模方法。我们通过均值 和形状参数 来参数化负二项分布:
其中,两个参数均由带有 softplus 激活的全连接层根据网络输出计算得到,以确保参数的正性。在这种参数化的负二项分布中,形状参数 缩放了方差相对于均值的比例,即 。虽然存在其他参数化方法,但初步实验表明这种特定的参数化方法对于快速收敛特别有利。
给定一个时间序列数据集 和相关的协变量 ,通过选择一个时间范围,使得预测范围内的 是已知的,可以通过最大化对数似然来学习模型的参数 ,其中包括 RNN 和 的参数:
。
对于数据集中的每个时间序列,我们通过从原始时间序列中选择不同起始点的窗口来生成多个训练实例。在实践中,我们保持所有训练样本的总长度 和条件范围与预测范围的相对长度不变。
例如,如果给定时间序列的总可用周期范围从2013年01月01日到2017年01月01日,我们可以创建训练实例,其中 对应于2013年01月01日、2013年01月02日、201301年03月01日等。
代码案例:https://forecastegy.com/posts/multiple-time-series-forecasting-with-deepar-in-python/
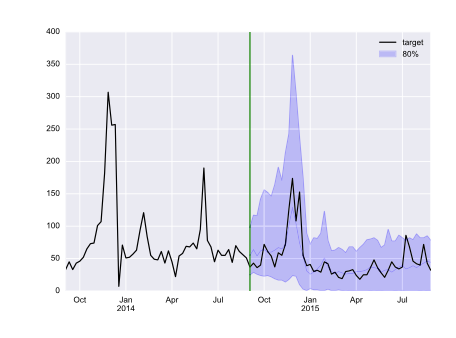
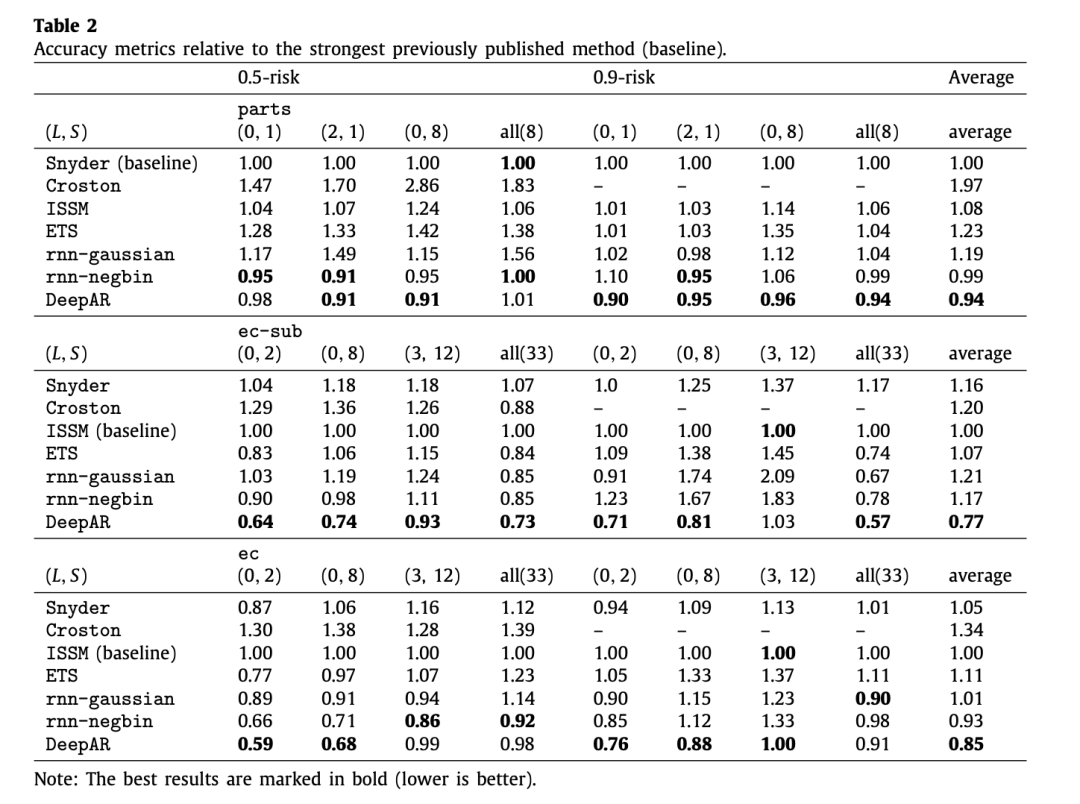
# 竞赛交流群 邀请函 #
每天大模型、算法竞赛、干货资讯

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢