

号外号外!LMDeploy 推出了 4bit 权重量化和推理功能啦。它不仅把模型的显存减少到 FP16 的 40%,更重要的是,经过 kernel 层面的极致优化,推理性能并未损失,反而是 FP16 推理速度的三倍以上。
https://github.com/InternLM/lmdeploy
(欢迎使用,文末点击阅读原文可直达)
到底有多快呢?我们在 NVIDIA Gerforce RTX 4090上,测试了 4bit Llama-2-7B-chat 和 Llama-2-13B-chat 的 token 生成速度。测试配置 batch 为 1,context window大小为 2048,prompt token 和 completion token 分别为1、512。
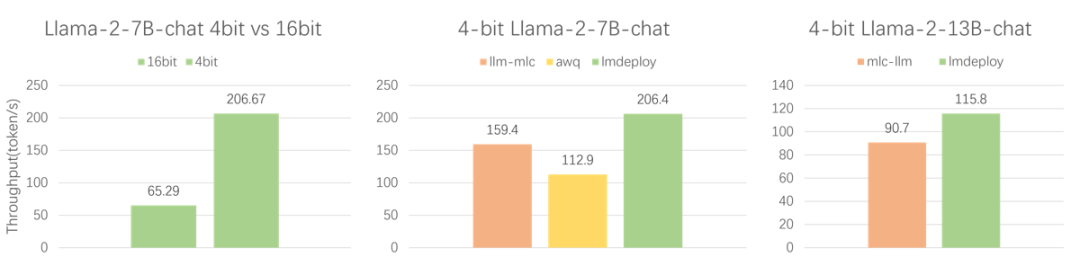
从图中可以看出,LMDeploy 的 4bit 推理是 16bit 的 3.16 倍。而同样是 4bit 推理,LMDeploy 比 llm-mlc 快近 30%。
到底多省呢?我们测试了 context window size 分别为 1024、2048、4096 的情况。4-bit 7B 模型一块 Geforce RTX 3060 足矣。
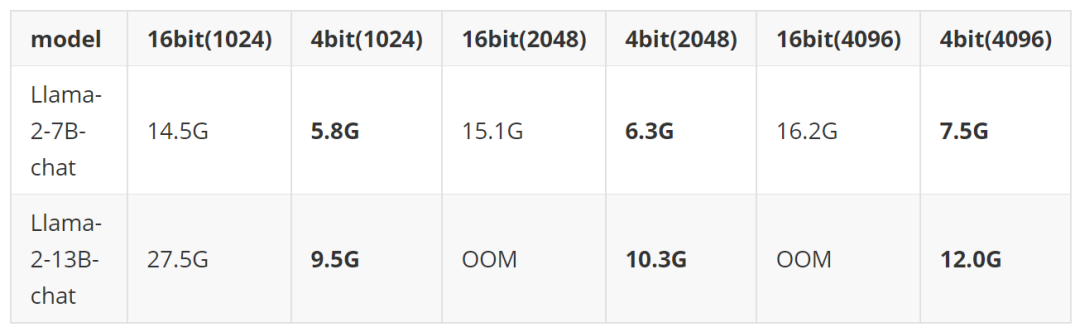
更多测试结果参考本文性能测试章节。
快速上手
安装
LMDeploy 推理 4bit 权重模型,对 NVIDIA 显卡的最低要求是 sm80,比如A10,A100,Gerforce RTX 30/40系列。
在推理之前,请确保安装了 lmdeploy >= v0.0.5
pip install lmdeploy获取 4bit 模型
您可访问 LMDeploy 的 model zoo:https://huggingface.co/lmdeploy,直接下载 4bit 模型。
git-lfs installgit clone https://huggingface.co/lmdeploy/llama2-chat-7b-w4
或者,根据文档 https://github.com/InternLM/lmdeploy#quantization,一键式把模型权重量化为 4bit。
推理
# 转换权重layout,并对模型打包python3 -m lmdeploy.serve.turbomind.deploy \--model-name llama2 \--model-path ./llama2-chat-7b-w4 \--model-format awq \--group-size 128# 推理python3 -m lmdeploy.turbomind.chat ./workspace
搭建 gradio 服务
python3 -m lmdeploy.serve.gradio.app ./workspace --server-ip {ip_addr} --server-port {port}然后,在浏览器中打开 http://{ip_addr}:{port},即可在线对话。
性能测试
LMDeploy 使用 2 个评测指标,用来衡量推理 API 的性能。分别是 completion token throughput(也称 output token throughput)和 request throughput。其中,前者测试的是在指定输入、输出 token 数量时,推理引擎生成 token 的速度。后者测试的是在真实对话数据下,每分钟处理的请求数。
completion token throughput
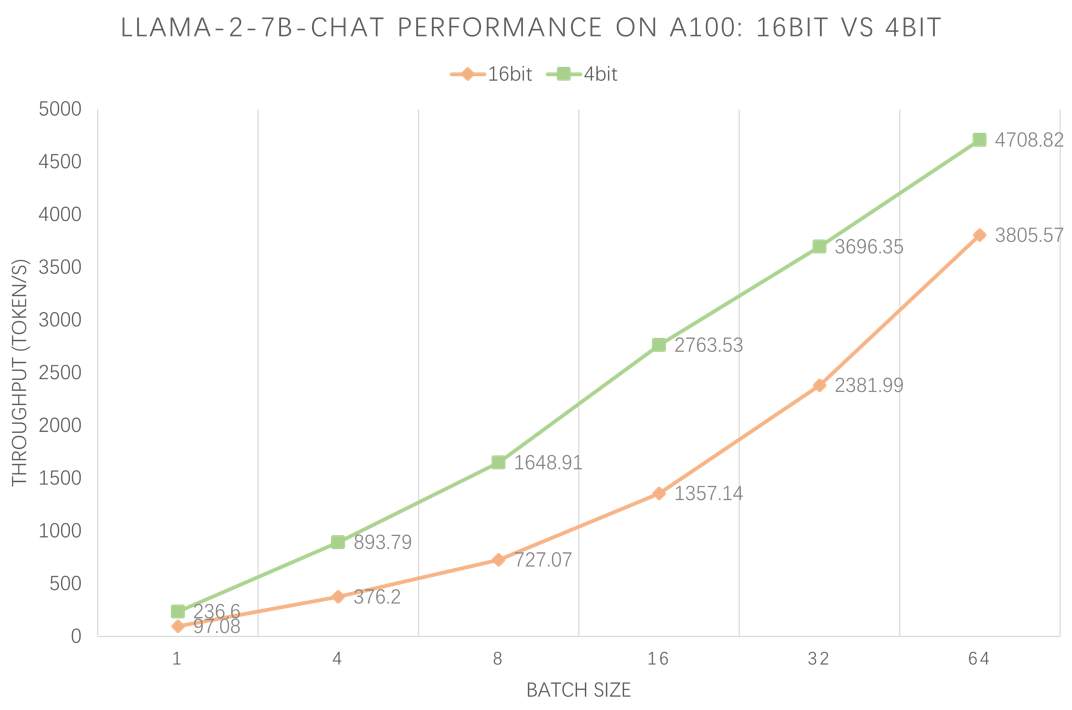
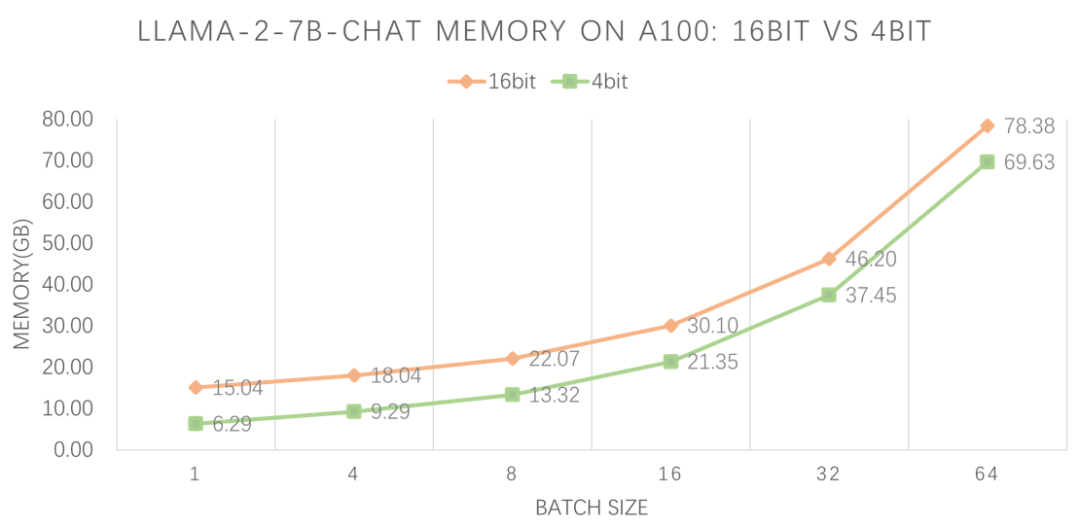
我们使用 LMDeploy 的 profile_generation.py,在 A100-80G 上分别测试 4bit 和 16bit Llama-2-7B-chat 模型在不同 batch 下的 token 生成速度,以及显存占用情况。prompt token 和 completion token 分别为 1、512。
吞吐量和显存对照结果如下:
request throughput
使用 LMDeploy 的 profile_throughput.py,在A100-80G 上分别测试 4bit 和 16bit Llama-2-7B-chat 的 request 处理速度,对照结果如下:

最后
除了 4bit 权重量化,LMDeploy 还支持了 k/v cache int8 量化。两者结合,相信在推理性能方面会有更进一步的提升。更详细的精度和速度评测报告,我们将在不久之后公布。
欢迎大家关注 https://github.com/InternLM/lmdeploy,动态资讯第一时间掌握!
The more you star, the more you get :)

点击下方“阅读原文”直达 LMDeploy,欢迎体验
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢