


作者使用OpenAI的GPT-3模型生成关于电子游戏艺术体验的开放式问卷回答,这是传统计算用户模型无法处理的主题。作者测试了合成回答是否可以与真实的回答区分开来,分析合成数据的错误,并调查合成数据和真实数据之间的内容相似性。得出的结论是,在这种情况下,GPT-3可以产生可信的HCI体验。鉴于LLMs数据生成的低成本和高速度,尽管任何发现都必须用真实数据进行验证,但是合成数据应该有助于构思和试验新的实验。这一结果也引发了人们的担忧:如果被众包服务的恶意用户利用,LLMs可能会使众包自我报告数据从根本上变得不可靠。
1. 绪论
HCI研究员:亲爱的AI,你认为你能为我扮演一个用户研究参与者吗?
AI:LaTeX是一个很好的排版工具,但我发现它比Word更难使用。有了Word,我可以很容易地按照我想要的方式格式化文档,而且我不必担心代码。
实际上,我们将LLMs视为一种新的搜索引擎,用于搜索其互联网规模训练数据中描述的信息、观点和经验。与传统的搜索引擎不同,LLMs可以以叙事的形式进行查询,如功能性采访。此外,LLMs对新任务和数据至少表现出一定的泛化能力。这为反事实提供了一个尚未开发的机会。例如,允许研究人员或设计师探索诸如“如果我问他们X,用户会说什么?”或“采访主题X会带来有趣的答案吗?”之类的问题。这种基于模型的探索的好处是数据生成的高速低成本,而明显的缺点是数据质量:任何基于生成数据的模糊推理都应该由真实的人类参与者进行验证,因为语言模型会表现出偏见并产生事实错误。尽管如此,我们认为值得在这种情况下探索LLMs的功能,并研究生成的数据有多人性化。
每一个问题都是在参与者描述电子游戏艺术体验的特定背景下进行调查的。这使我们能够将GPT-3与真实的人类数据进行比较。选择电子游戏艺术体验作为研究领域,是因为这对任何现有的用户建模或模拟方法来说都是具有挑战性的。我们只使用真实数据来评估GPT-3,而不进行任何训练或微调,也不在提示中引入数据来指导GPT-3。
我们工作的一个明显限制是,我们只使用一个特定的数据集来检查LLMs的功能。我们没有声称我们的结果对所有其他可能的用例的可推广性;尽管如此,我们相信我们的研究对于评估GPT-3和LLMs作为合成HCI数据源的应用潜力是有用的,也是必要的。我们的研究结果还应有助于了解LLMs可能存在的滥用潜力和风险,例如,如果机器人和恶意用户在Prolifc或Amazon Mechanical Turk等在线研究众包平台上采用LLMs生成虚假答案。如果LLMs的回答非常像人,那么检测虚假答案可能变得不可能,平台需要新的方法来验证其用户和数据。
2. 数据
我们将GPT-3与Bopp等人[1]最近一项关于电子游戏艺术体验的研究中的真实人类参与者的反应进行了比较。Bopp等人要求参与者写下他们将数字游戏视为艺术的经历,数据集中包含178个对此问题的回答。我们不根据任何质量指标过滤数据集中的回复,因为我们想将GPT-3生成的数据与通常从在线研究中收到的(原始)数据进行比较。
我们选择Bopp等人的数据集是因为它的近期性:该数据是在GPT-3之后发布的,因此不在GPT--3训练数据中。这也是为什么我们在实验中使用原始的GPT-3模型,而不是OpenAI最近添加的模型。
体验艺术是一个深刻的、主观的、从根本上讲是人类的话题,因此从人工智能用户建模的角度来看应该是一个挑战。它还提供了与广泛使用的语言模型基准任务(如事实问答)的对比。
2.2. 实验任务及研究设计GPT-3 数据
用于生成GPT-3数据的提示如Table 1所示。

提示包括直接来自研究的问题(“你有没有经历过……”、“请记住……”,“游戏的标题是什么?”、“……是什么让你把这种经历视为艺术?”),前面还有一些额外的背景。对于真正的人类参与者,将通过实验/研究说明提供类似的背景。注意,我们的实验1和实验2只使用了Table 1中的第一个提示。总的来说,所有三个实验都使用相同的过程来生成GPT-3数据。
一般方法如下所述,为了生成合成数据,我们使用Python脚本与GPT-3公共API进行交互。我们使用了500个token的最大连续长度,并实现了以下启发式方法来自动提高数据质量:
为了避免在回答中产生后续问题,我们只使用每个回答的部分,直到字符串“研究人员:”第一次出现;
完成后,我们会自动剪切第一个换行符后的任何标记。也就是说,我们只包括了案文的第一段。
如果得到的响应长度小于10个单词,我们将其丢弃,并生成一个全新的回复长度,重新应用上面的启发式方法。
如果响应包含超过10个字符的连续唯一重复,我们也会丢弃并重新生成回复。
3. 实验一:区分GPT-3和真实数据
我们的第一个实验对GPT-3与真实人类反应的区别进行了定量研究。对于GPT-3合成数据的有用性,我们认为GPT-3反应与人类反应不能清楚区分是必要的(但并不充分)。尽管GPT-3生成的文本与人类文本的可区分性之前已经进行了研究,但在这里,我们特别关注HCI领域中文本研究数据的可区别性。
3.1参与者和刺激措施
参与者
最终样本量为155。55.48%的最终参与者是男性,43.23%是女性,1.3%是其他人或不愿透露自己的性别。从1(我几乎听不懂)到5(我是母语为英语的人),43.23%的参与者将他们的英语阅读和理解能力评为5,52.9%的参与者评为4,3.87%的人评为3。大多数参与者年龄在35岁以下(18-25岁:56.77%,26-35岁:34.84%,36-45岁:5.81%,46-55岁:2.58%)。
刺激
3.2过程
每个参与者总共评估了20个刺激,其中10个从人类刺激集中随机选择,10个从GPT-3产生的刺激集中随机挑选。按照随机顺序,一段接一段地向参与者展示课文。对于每一篇文本,他们的任务是决定他们是否认为有问题的文本更有可能是由人类编写的,还是由人工智能系统生成的。他们的回答是(用电脑鼠标)按下一个写着“由人类参与者编写”或“由人工智能生成”的按钮。
在开始任务之前,参与者被告知,他们将看到的文本段落有一半是人类写的,一半是人工智能生成的,并且呈现顺序是随机的。
3.3.数据分析与结果
在分析中,我们根据反应时间和质量,排除了一些样本。
总的来说,人类书写的文本在54.45%的情况下被正确识别,95%的置信区间不包括50%的机会水平(95%置信区间:51.97%-56.93%)。将GPT-3生成的文本识别为人工智能书写的平均准确率低于40.45%的机会水平(95%可信区间:38.01%-42.89%)。因此,参与者倾向于回答文本是人类书写的,57%的回复是“由人类参与者撰写的”(见Table 2)。参与者的平均bias为c=-0.2,在单样本t检验中,参与者的bias值与零有显著差异(t(154)=7.74,p<0.001)。

与我们的预期相反,基于d'值,GPT-3文本被认为更像人类。测试d'值与零的单样本t检验具有统计学意义,影响大小较小(t(154)-2.52,p=0.013,d=-0.2)。平均d'值为负(d'=-0.15),也就是说,参与者更有可能以假警报(即GPT-3文本由人类编写)而非正确点击(即人类文本由人类撰写)做出反应。这种趋势也可以从Figure 2中直观地看出,Figure 2中为100种刺激中的每一种绘制了“人类参与者书写”的平均比例。
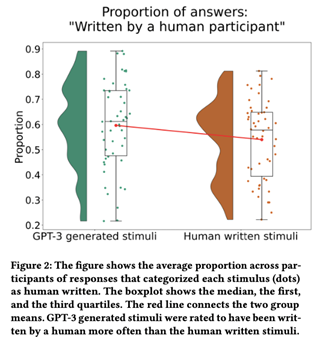
对开放式问题答案的探索性分析表明,确定文本是否由人类撰写的一个常见标准是文本是否包括对情感体验的描述。尽管我们没有对开放式问题的答案进行彻底的分类,但情绪的重要性可以从单词频率中看出。总的来说,54.19%的回答“是什么让你认为答案是人类写的?”包含字符串“情感”或字符串“感觉”。此外,在对同一问题的回答中,词干emot是第二常见的词干,仅次于词干human(见Figure 3)。
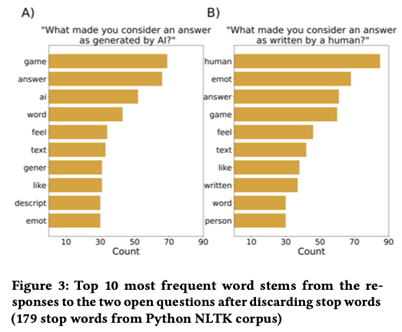
4.实验二:GPT-3会产生什么样的错误?
很明显,尽管最好的GPT-3反应看起来很像人类,但并非所有模型都具有高质量。为了更好地理解其局限性,我们对合成数据进行了定性调查。我们生成了两组100个响应,并调查了GPT-3产生的错误类型。实验1的参与者已经反思了是什么让他们对人工智能生成的回答或真人写的回答进行了评分,但这提供了有限的信息,因为1)参与者对人工智能产生的文本缺乏经验,2)参与者在对所有回答进行评分后,事后提供了评分。作为补充,以下内容确定了合成数据中的常见故障模式,并引用了哪些故障模式可以自动识别和消除。
4.1 方法
我们使用了Table 1中描述的PROMPT1的两个版本,一个简单地以“Participant:”结尾,另一个以“Partition:
I’m thinking the game”结尾。这样做的动机是检查提供额外的指导是否会提高回复的质量。一般来说,更具体的提示往往会产生更高质量的结果。两个提示版本都生成了100个回复。
三位注释者(作者)将回复分为有效或无效。如果一个回答表现出一些明显的异常,例如,模型生成了不同问题的答案,则该回答被视为无效。我们忽略了语法和流利性问题,这些问题可以被视为真实人类参与者的不同样本中的自然变化。最初的分类是由两个注释器分两次执行的。在第一次传递中,注释器独立地进行分类并识别不同类型的异常。然后讨论异常类型,并将其合并到第二次分类/引用过程中使用的代码簿中。最后,第三个注释器将回复分为有效或无效,并以代码簿为指南对异常进行分类。

一些异常现象,如回避问题,很容易被人类评论者发现,人们很可能会使用一些自动方法来检测和重新生成这样的答案。即使GPT-3本身也可能做到这一点,如果提示的是有效和无效答案的few-shot示例。然而,也有一些情况下,很难区分有效/无效。想象中的游戏描述可能是最重要的例子,因为识别它们可能需要对所讨论的游戏有深入的了解。
5. 实验三:真实内容和GPT-3内容的差异
提到的游戏(RQ:“玩家体验什么游戏作为艺术?”)
将游戏视为艺术的原因(RQ:“是什么让玩家认为游戏是艺术?”)
5.1方法
在这个实验中,我们继续对实验1和2进行综合访谈,并提出后续问题,使我们能够更深入地研究人类和GPT-3生成的数据之间的相似性。在这个实验中,我们使用了Table 1中显示的所有三个提示。
在数据生成的第一步中,我们生成了与先前实验一样的艺术体验描述(PROMPT 1,Table 1)。这些回答包含在下一个提示中,该提示“继续”采访“游戏标题是什么?”(prompt 2,Table 1)。这些答案也被附加到下一个提示中,进一步询问“在你看来,是什么让你把这种经历视为艺术?”(prompt 3,Table 1)。
因此,在所有模型中,结束提示2和3的问题都保持不变,但各个提示根据之前的GPT-3完成情况而有所不同。我们生成了178个“完整访谈”(即对三个提示中的每一个都有178个回复),以匹配Bopp等人数据集中的人类回复数量。为了检查模型大小和类型如何影响结果,使用五种不同的GPT-3变体(ada、babbage、curie、davinci和text-davinci-002)创建了一组178个响应。
在这个实验中,我们允许回复包括三段文本,除了关于游戏标题的问题,其中回复是在第一个换行符之后剪切的,就像之前的实验一样。由于有关游戏标题的提示预计会导致较短的延续,因此对于该提示,最大延续长度设置为50个tokens。
自动定性编码。我们对“为什么是艺术?”答案(即PROMPT 3的完成)的分析是基于这样的观察,即GPT-3可以被提示使用Table 5中给出的提示对数据进行一种形式的定性生产编码。这些代码提供了所述原因的紧凑描述符,并允许灵活的进一步分析,例如分组到更广泛的主题和计算主题频率。

主题异同。我们独立地对比较的数据集进行编码和分组,并根据它们的频率对代码组进行排序。然后,我们使用循环图(Figure 7)来可视化排序的组和数据集之间的连接。可视化的连接强度对应于组的全维均值归一化嵌入向量的余弦相似性。我们在这项分析中只包括了davinci GPT-3变体,因为根据上述数据质量指标,它是最像人类的模型。
回答一致性。重要的是,单独询问的答案以一致的方式继续面试或调查。我们的提示是为此而设计的,因为同一合成“参与者”之前生成的答案包含在下一个答案的提示中。重要的是,“为什么是艺术?”提示(prompt 3,Table 1)始终包括先前生成的艺术体验描述(使用prompt 1,Table 1生成)。
游戏频率。最后,我们还统计了人类和GPT-3数据中提到的每个游戏的频率。对于人类数据,我们纳入了主题分析中178名参与者的回答。对于GPT-3数据,游戏的频率是从178次完成中计算出来的,这些完成是通过提示“游戏的标题是什么?”来查询的。游戏的频率是从数据中手动计算出来的。如果在同一回复中有两个或多个游戏被提及,则这些游戏被视为单独提及。如果很明显,回应指的是同一款游戏,那么回应中的小差异就会被丢弃(例如,《荒野之息》被归类为与《塞尔达传说:狂野之息》相同的答案)。如果响应不包括特定的游戏标题,或者我们无法找到游戏标题以引用已发布的游戏,则会忽略响应。为了简洁起见,我们只报告davinci和text-davinci-002变体的结果。注意,游戏频率分析不利用上述的自动编码步骤。
6. 结果
真实数据和GPT-3数据中都出现了高度相似的组/主题。Figure 7显示了人类数据中有多少最频繁的组对应于GPT-3数据中也是最常见的组,例如与故事(人类和GPT-3的数据中最频繁)和音乐(人类和GPT-3的数据第二频繁)相关的组。Figure 4中代码嵌入向量的可视化还表明,对两个数据集进行编码会产生很大程度上相似的代码。
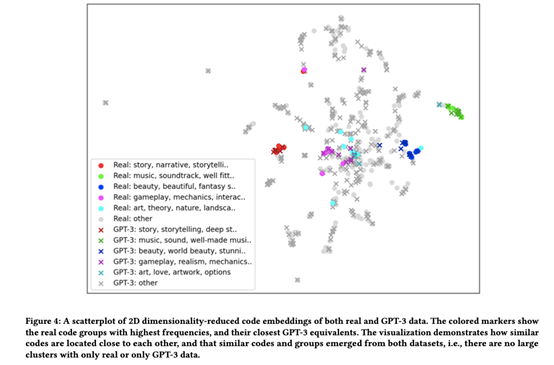
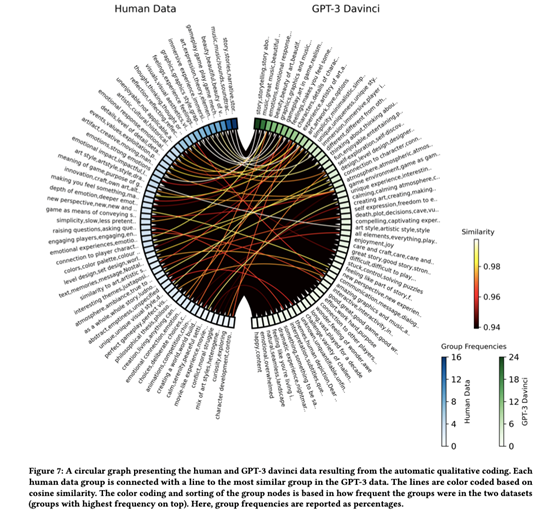
Table 6(最常提到的游戏)显示,真实和GPT-3数据讨论了一些相同的游戏,如Journey、Bioshock和Shadow of the Colossus。然而,GPT-3生成的数据中缺少人类数据中的许多游戏,这表明LLM生成的合成数据可能比真实数据具有更少的多样性。在人类数据中,只有17.3%的游戏在GPT-3 davinci数据中被提及。 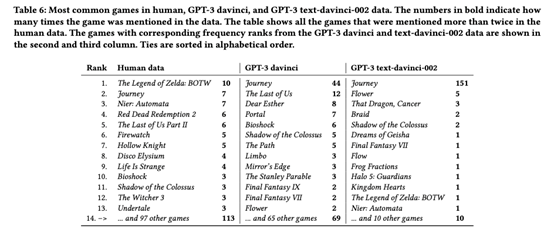
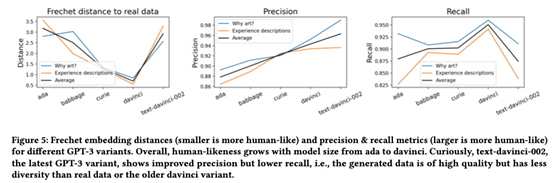
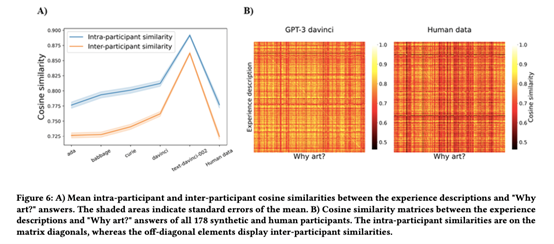
如Figure 6所示,人类数据和所有GPT-3变体都显示出参与者内部比参与者之间更高的答案相似性,这表明在回答连续问题时至少有一定程度的一致性。对于所有数据源(ada、babbage、curie、davinci、text-davinci-002、人类数据),在所有5000种不同的参与者间排列中,参与者间平均相似性低于真正的参与者内平均相似性。总体上略高于人类GPT-3的相似性,以及显著高于text-davinci-002的相似性可能反映了上述数据多样性问题。
更大的GPT-3变体产生更多类似人类的数据(Figure 5)。OpenAI没有披露通过其API提供的GPT-3模型的确切大小,但ada、babbage、curie和davinci模型已被推断为对应于原始论文中评估的越来越大的模型的连续体。模型的排序也对应于文本生成成本的增加,支持ada是最小的模型,davinci是最大的模型的结论。 最新的text-davinci-002模型的召回率较低,而且明显不如真实数据的多样性。这一点在提到的游戏列表中很明显,178个答案中有151个讨论了《征途》(真实数据中只有7个提到)。尽管OpenAI建议将该模型作为默认模型,但我们的数据表明,出于用户建模的目的,应该避免使用该模型,至少当人们关心数据多样性时是这样。
7. 结论
我们探索并评估了一种通用大语言模型(GPT-3),该模型用于生成合成的HCI研究数据,其形式是关于将电子游戏体验为艺术的开放式问答。我们的结果表明,GPT-3的反应在最好的情况下可以非常像人,并且可以讨论与真实人类反应基本相似的主题,尽管未来的工作需要用其他数据集和研究主题来验证这一点。另一方面,GPT-3反应的多样性可能低于真实反应,并包含各种异常和偏差。需要更多的研究来修剪异常反应和/或引导模型做出更好、更少偏差的反应。
参考文献:
[1] Julia A. Bopp, Jan B. Vornhagen, and
Elisa D. Mekler. 2021. "My Soul Got a Little Bit Cleaner": Art
Experience in Videogames. Proc. ACM Hum.-Comput. Interact.
5,CHIPLAY,Article237(oct2021),19pages. https://doi.org/10.1145/3474664
论文链接:https://dl.acm.org/doi/10.1145/3544548.3580688
助手微信

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢