
点关注,不迷路,用心整理每一篇算法干货~
文本图建模在现实世界中非常常用。文本图是文本和图的结合,图描述了各种类型节点之间的关系,例如在电商场景中,用户和商品的点击、转化等关系;而文本则描述了节点的核心特性。如何进行高效的文本图建模,是近年来NLP领域的一个研究重点。
这篇文章介绍KDD 2023中两篇文本图相关的工作,第一篇Heterformer是伊利诺伊大学厄巴纳-香槟分撰写,将图结构信息融合到Transformer语言模型中;第二篇由亚马逊发表,设计了一种图学习和语言模型co-train的方式,并应用到多个下游任务中。

论文标题:Heterformer: Transformer-based Deep Node Representation Learning on Heterogeneous Text-Rich Networks
下载地址:https://arxiv.org/pdf/2205.10282.pdf
进行文本图建模有两个难点,一个是有的节点有文本,有的节点没有文本,如何兼顾这两种类型的节点;另一个问题是,很多现实世界的图都有多种类型的图和多种类型的节点,如何对齐不同类型特征空间进行统一建模。
本文提出了一种异构文本图的建模方法。主体目标为,根据图结构和文本信息,训练一个模型,能够生成图中有文本或无文本信息的节点良好的表示向量,这个向量能应用于下游各类任务并提升下游任务效果。文中提出的整体模型结构如下图,主要包括对于有文本信息节点的图+文本联合建模,以及对于无文本信息节点的兼容两个部分。
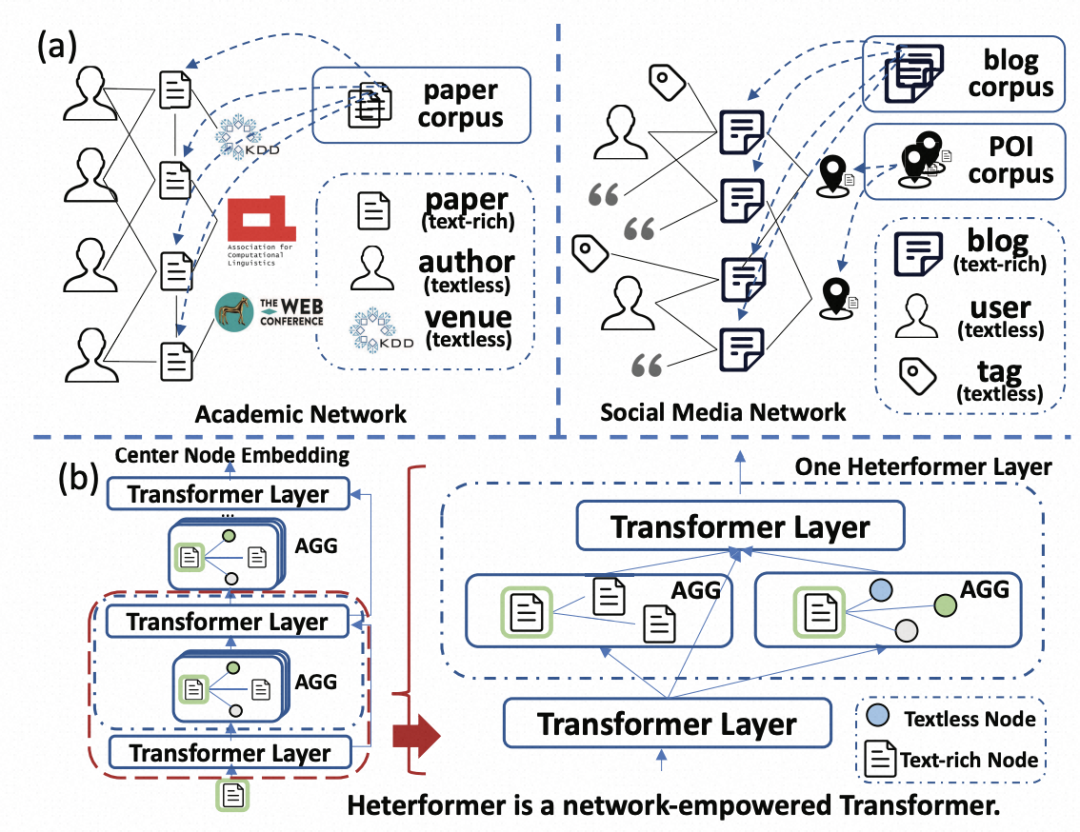
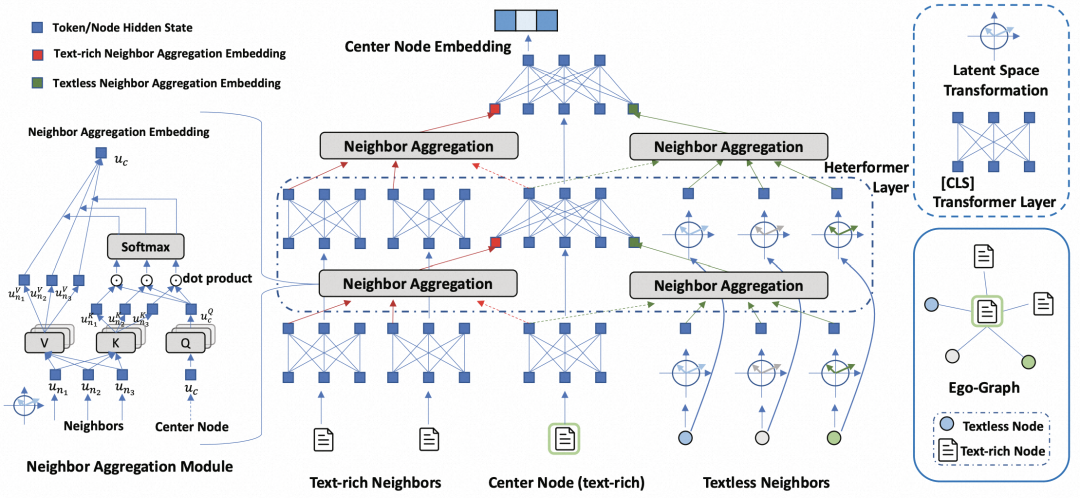
一般的文本编码器,将文本输入到transformer中获取其编码结果,但是对于文本图来说,需要同时将图结构信息考虑在内。本文提出了一种简单的在Transformer文本编码器中引入图结构信息的方式。对于一个有文本信息的中心节点,将其邻居节点分为两类,一类是有文本的节点,一类是无文本的节点。将这两类邻居节点分别过一个Neighbor Aggregation层,用来汇聚得到两类邻居节点表示。这两个表示被视为虚拟token,添加到中心节点文本的两侧,跟随文本编码一起输入到后续Transformer层中。Neighbor Aggregation采用的是多头注意力机制,利用中心节点作为Q,邻居节点作为K、V进行信息汇聚。通过这样的方式,在Transformer以token的形式引入邻居节点表征,实现了在文本Transformer中考虑图结构特征的目的。
对于无文本信息的节点,我们也希望能得到其良好的表示。文中首先给每个无文本信息节点一个低维的初始化向量,然后每种类型的节点用一个不同的全连接层进行高维映射,实现异构节点到相同空间的映射。由于图中有大量的无文本信息节点,这些节点的embedding初始化好坏对于模型训练过程至关重要。因此,文中使用Transformer获取有文本信息节点的编码,让无文本信息节点的初始化向量与其邻居的有文本节点Transformer编码近,非邻居节点的编码远,类似于用无文本节点的有文本邻居节点文本表征做一个pooling,以获取到一个中心节点有含义的初始化向量,便于后续的特征空间对齐和训练。
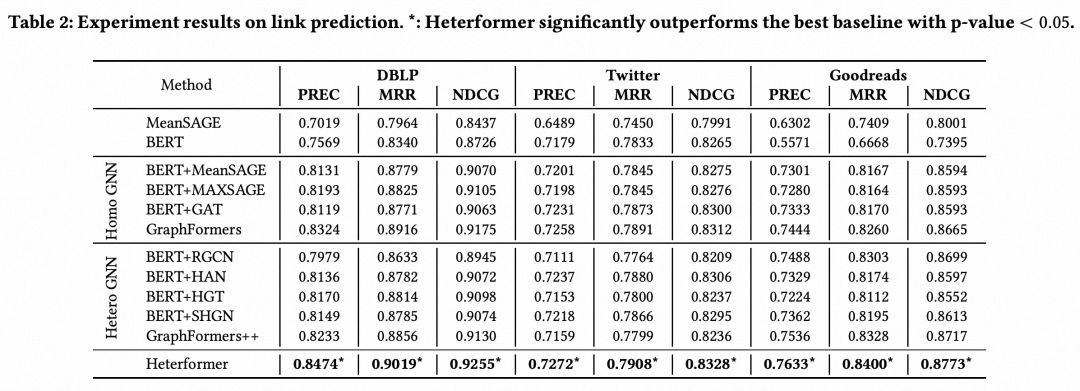
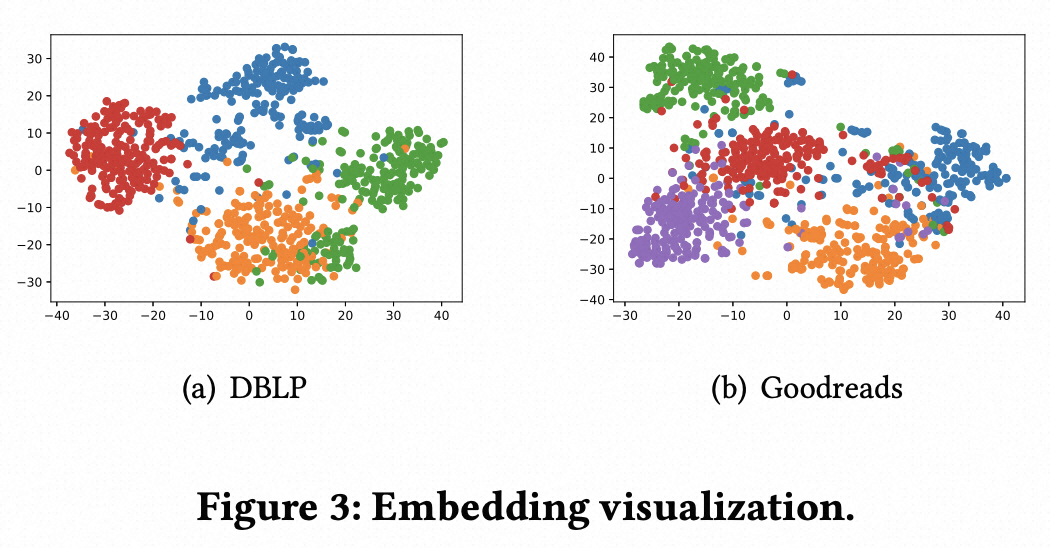
在实验结果,本文将这种方法生成的表示应用于link predition、node classification、node clustering等多个任务中,效果相比之前的图节点表示学习方法都有明显提升,生成的表征分布也更加合理。

论文标题:Graph-Aware Language Model Pre-Training on a Large Graph Corpus Can Help Multiple Graph Applications
下载地址:https://arxiv.org/pdf/2306.02592.pdf
相比上一篇HetFormer在模型结构上将图结构融入到Transformer,本文设计了一种语言模型和图神经网路联合训练的方法,在整个训练过程中Transformer感知到图结构信息,并应用到多种下游任务中。
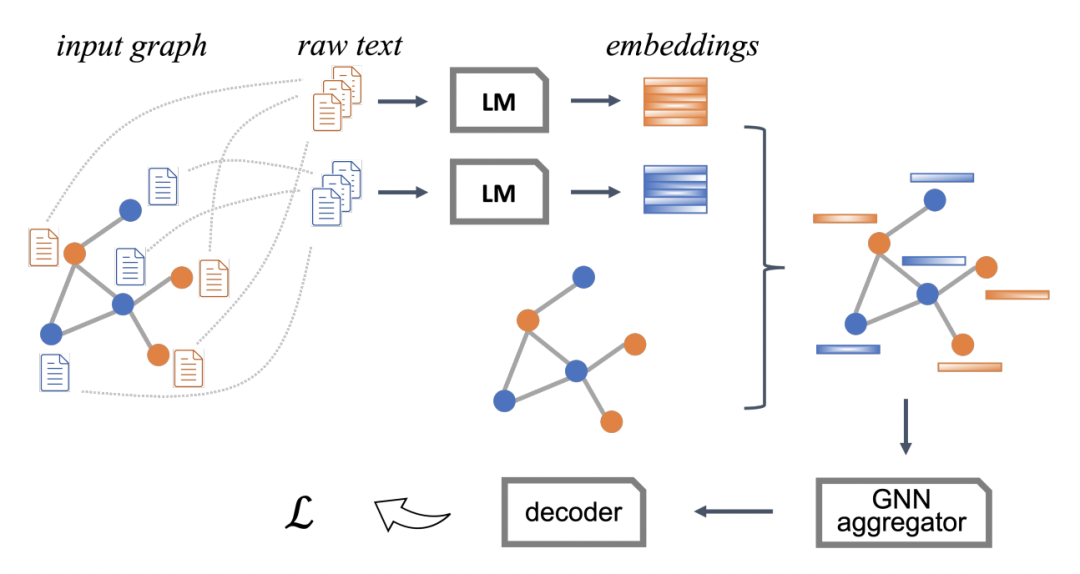
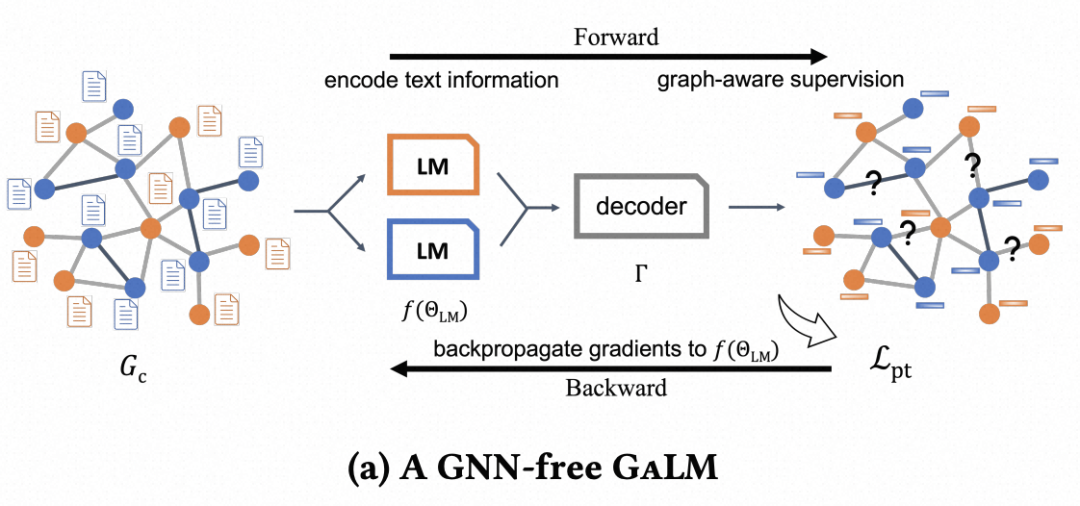
整体的训练过程有三种类型,分别是基础的语言模型训练、Graph-aware的语言模型训练、Graph和语言模型的cotrain。
首先是语言模型的预训练,这部分以BERT为基础,在亚马逊的电商图中语料上进行预训练。整个图由query和product两种类型的节点组成,边包括点击、购买等用户行为。对于不同的节点类型,文中采用了不同的模型进行训练,主要是由于query和product的文本分布差异较大,使用独立的参数可以更好的进行数据差异建模。
接下来是Graph-aware的训练过程。对于每个节点,首先通过语言模型获取到各个节点的表征。然后以一个link prediction无监督任务来做优化目标,进一步更新语言模型。这种方式通过link prediction,将图结构信息引入了语言模型,例如用户点击行为产生的query和product的匹配信息。
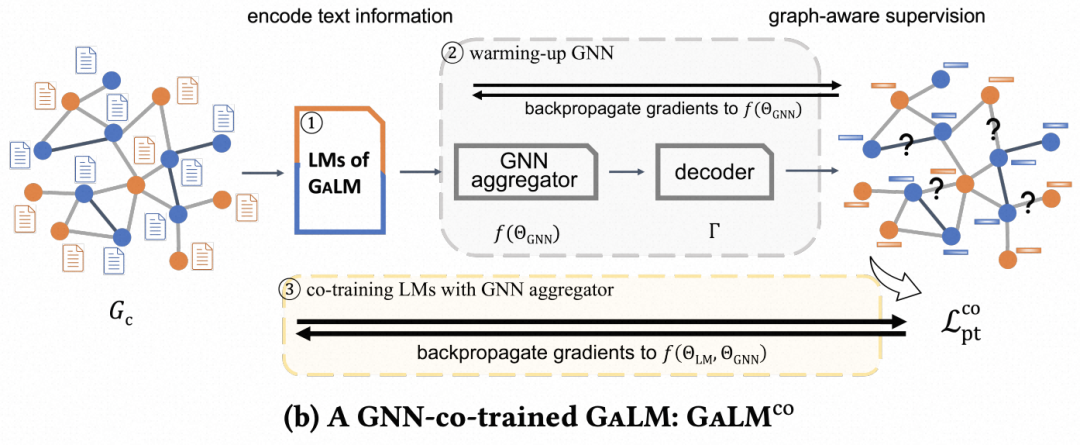
在此基础上,文中提出了一种co-train的方式,让语言模型和GNN联合训练。整体流程是使用语言模型得到节点表征后,输入到GNN中得到汇聚邻居信息的节点表征,再进行link prediction任务。为了加快训练的收敛,整体会先使用上面提到的Graph-aware方式训练一个初始的语言模型,然后固定语言模型训练几轮GNN网络做warmup,最后再端到端联合学习。
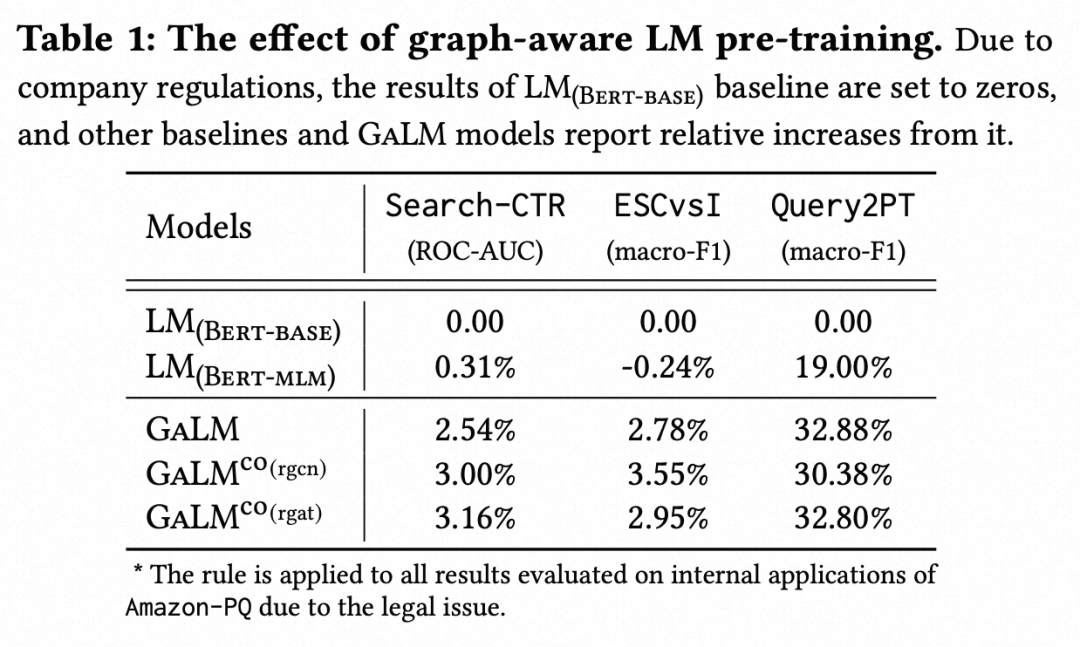
文中详细对比了这几种训练方式在3个下游任务上的效果,可以看到Graph-aware的方式相比基础的BERT语言模型预训练效果要好得多,并且引入端到端的训练可以进一步提升效果。



也欢迎添加我的私人微信进行交流&投稿,加入圆圆算法交流群~

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢