

以下文章来源于知乎:集智书童
作者:小书童
链接:https://mp.weixin.qq.com/s/3oXJ1jFj19XHwy6pgPTXHQ
本文仅用于学术分享,如有侵权,请联系后台作删文处理


作者旨在为目标检测社区提供一种高效且性能卓越的目标检测器,称为YOLO-MS。核心设计基于一系列对不同Kernel-Size卷积如何影响不同尺度上目标检测性能的研究。研究结果是一种可以显著增强实时目标检测器多尺度特征表示的新策略。
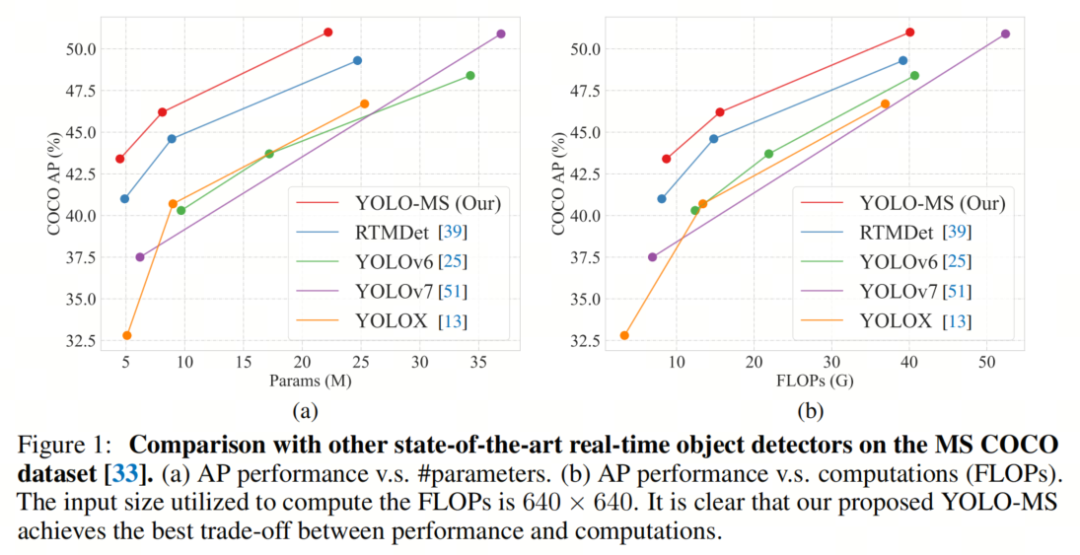
为了验证作者策略的有效性,作者构建了一个名为YOLO-MS的网络架构。作者在MS COCO数据集上从头开始训练YOLO-MS,而不依赖于任何其他大规模数据集,如ImageNet,或预训练权重。作者的YOLO-MS在使用相同数量的参数和FLOPs的情况下,优于最近的最先进的实时目标检测器,包括YOLO-v7和RTMDet。以YOLO-MS的XS版本为例,仅具有450万个可学习参数和8.7亿个FLOPs,它可以在MS COCO上达到43%+的AP得分,比相同模型尺寸的RTMDet高出约2%+。
此外,作者的工作还可以作为其他YOLO模型的即插即用模块。通常情况下,作者的方法可以将YOLOv8的AP从37%+显著提高到40%+,甚至还可以使用更少的参数和FLOPs。
论文链接:https://arxiv.org/pdf/2308.05480.pdf
1、简介
从局部视角出发,作者设计了一个具有简单而有效的分层特征融合策略的MS-Block。受到Res2Net的启发,作者在MS-Block中引入了多个分支来进行特征提取,但不同的是,作者使用了一个带有深度卷积的 Inverted Bottleneck Block块,以实现对大Kernel的高效利用。
从全局视角出发,作者提出随着网络加深逐渐增加卷积的Kernel-Size。作者在浅层使用小Kernel卷积来更高效地处理高分辨率特征。另一方面,在深层中,作者采用大Kernel卷积来捕捉广泛的信息。
2、本文方法
2.1 多尺度构建块设计
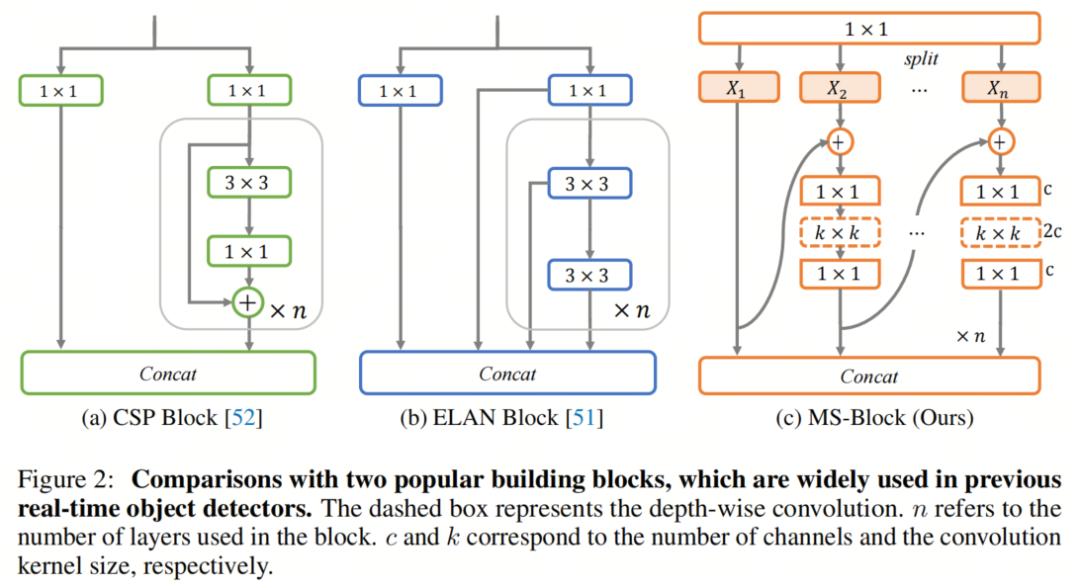
MS-Block
基于前面的分析,作者提出了一个带有分层特征融合策略的全新Block,称为MS-Block,以增强实时目标检测器在提取多尺度特征时的能力,同时保持快速的推理速度。
MS-Block的具体结构如图2(c)所示。假设是输入特征。通过1×1卷积的转换后,的通道维度增加到。然后,作者将分割成个不同的组,表示为,其中。为了降低计算成本,作者选择为3。
注意,除了之外,每个其他组都经过一个 Inverted Bottleneck Block层,用表示,其中表示Kernel-Size,以获得。的数学表示如下:
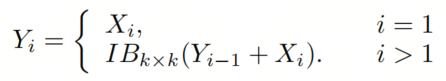
根据这个公式,作者不将 Inverted Bottleneck Block层连接到,使其作为跨阶段连接,并保留来自前面层的信息。最后,作者将所有分割连接在一起,并应用1×1卷积来在所有分割之间进行交互,每个分割都编码不同尺度的特征。当网络加深时,这个1×1卷积也用于调整通道数。
2.2 异构Kernel选择协议
除了构建块的设计外,作者还从宏观角度探讨了卷积的使用。之前的实时目标检测器在不同的编码器阶段采用了同质卷积(即具有相同Kernel-Size的卷积),但作者认为这不是提取多尺度语义信息的最佳选项。
在金字塔结构中,从检测器的浅阶段提取的高分辨率特征通常用于捕捉细粒度语义,将用于检测小目标。相反,来自网络较深阶段的低分辨率特征用于捕捉高级语义,将用于检测大目标。如果作者在所有阶段都采用统一的小Kernel卷积,深阶段的有效感受野(ERF)将受到限制,影响大目标的性能。在每个阶段中引入大Kernel卷积可以帮助解决这个问题。然而,具有大的ERF的大Kernel可以编码更广泛的区域,这增加了在小目标外部包含噪声信息的概率,并且降低了推理速度。
在这项工作中,作者建议在不同阶段中采用异构卷积,以帮助捕获更丰富的多尺度特征。具体来说,在编码器的第一个阶段中,作者采用最小Kernel卷积,而最大Kernel卷积位于最后一个阶段。随后,作者逐步增加中间阶段的Kernel-Size,使其与特征分辨率的增加保持一致。这种策略允许提取细粒度和粗粒度的语义信息,增强了编码器的多尺度特征表示能力。
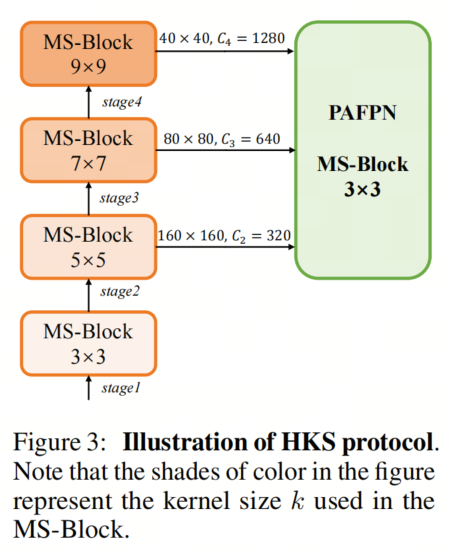
正如图3所示,作者将k的值分别分配给编码器中的浅阶段到深阶段,取值为3、5、7和9。作者将其称为异构Kernel选择(HKS)协议。
作者的HKS协议能够在深层中扩大感受野,而不会对浅层产生任何其他影响。第4节的图4支持了作者的分析。此外,HKS不仅有助于编码更丰富的多尺度特征,还确保了高效的推理。
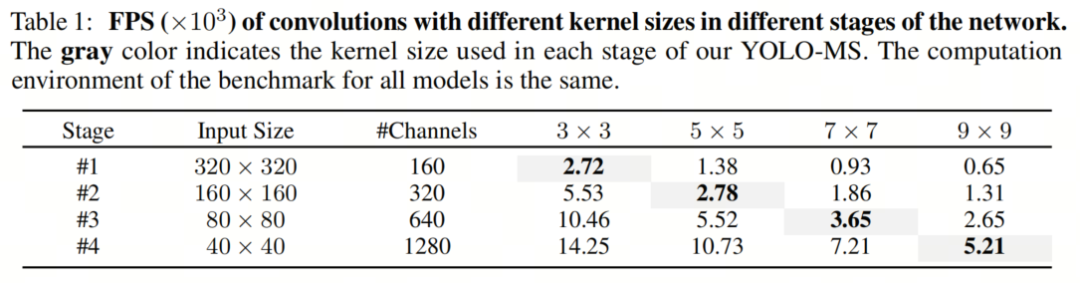
如表1所示,将大Kernel卷积应用于高分辨率特征会产生较高的计算开销。然而,作者的HKS协议在低分辨率特征上采用大Kernel卷积,从而与仅使用大Kernel卷积相比,大大降低了计算成本。
在实践中,作者经验性地发现,采用HKS协议的YOLO-MS的推理速度几乎与仅使用深度可分离的3 × 3卷积相同。
2.3 架构
如图3所示,作者模型的Backbone由4个阶段组成,每个阶段后面跟随1个步长为2的3 × 3卷积进行下采样。在第3个阶段后,作者添加了1个SPP块,与RTMDet中一样。在作者的编码器上,作者使用PAFPN作为Neck来构建特征金字塔[31, 35]。它融合了从Backbone不同阶段提取的多尺度特征。Neck中使用的基本构建块也是作者的MS-Block,在其中使用3 × 3深度可分离卷积进行快速推理。
此外,为了在速度和准确性之间取得更好的平衡,作者将Backbone中多级特征的通道深度减半。作者提供了3个不同尺度的YOLO-MS变体,即YOLO-MS-XS、YOLO-MS-S和YOLO-MS。不同尺度的YOLO-MS的详细配置列在表2中。对于YOLO-MS的其他部分,作者将其保持与RTMDet相同。

3、实验
3.1、Analysis of MS-Block
在本小节中,作者对作者的MS-Block进行了一系列消融分析。默认情况下,作者对所有实验都使用YOLO-MS-XS模型。
Inverted Bottleneck Block
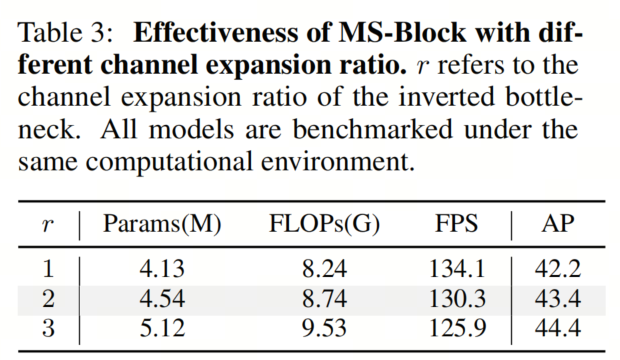
结果表明,在 = 2时,检测器在性能与计算开销之间取得了最佳平衡。此外,通道扩展比例显著影响了检测器的性能,与= 2相比,= 1时性能下降了1.2个AP,而= 3时性能提高了1个AP。这意味着 Inverted Bottleneck Block内的通道扩展增强了深度可分离卷积的表征能力,丰富了特征的语义信息。
然而,尽管= 3获得了最高性能,但计算成本也更高。因此,作者在所有后续实验中将= 2作为默认设置,以保持高计算效率。
特征融合策略
通常情况下,MS-Block通过加法逐步融合相邻分支之间的特征。作者进行了消融研究,以评估特征融合策略的有效性。
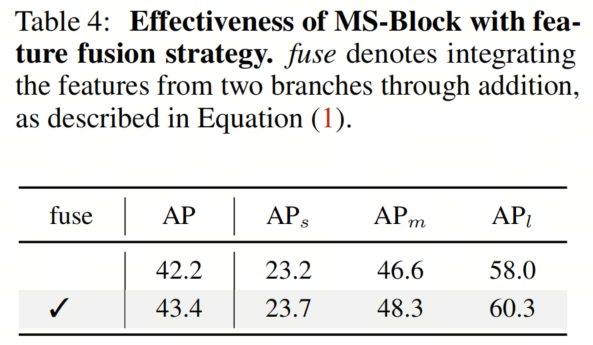
结果如表4所示,表明分支之间的特征融合对于提高模型性能至关重要。特别地,它使YOLO-MS的AP得分显著提高了+1.2%。
MS-Layers的数量
作者还分析了不同数量的MS-Layers(用Nl表示)的计算成本和推理速度。结果如表5所示。
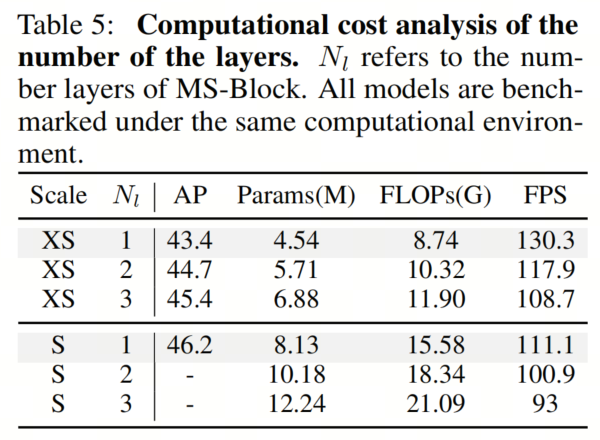
可以看出,MS-Block中的MS-Layers数量显著影响了YOLO-MS的速度。例如,在YOLO-MS-XS的情况下,随着从1增加到2,然后增加到3,参数数量分别增加了25.8%和51.5%。
此外,FLOPs分别增加了18.1%和36.2%。当= 2和 = 3时,推理过程的FPS也分别下降了9.2%和16.6%。因此,作者在所有后续实验中将= 1作为默认设置。
注意机制
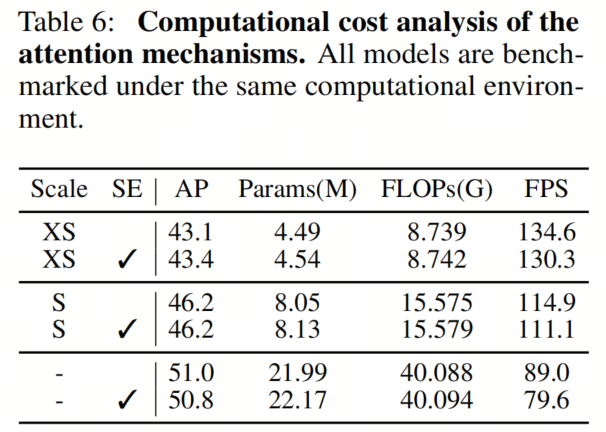
与RTMDet一致,作者在最后的1 × 1卷积之后使用SE注意力来捕捉通道间的相关性。作者进行实验研究以研究通道注意力的影响。计算分析见表6,性能见表12。有趣的是,注意力机制只能略微提高性能,但会降低推理时间。因此,用户可以根据自己的条件选择性地使用通道注意力。
分支数量
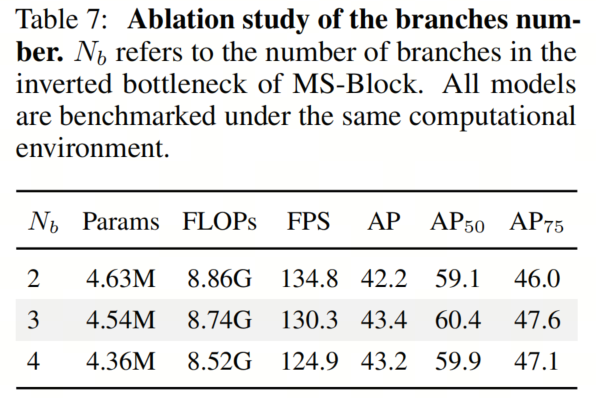
作者的MS-Block将特征输入分割并传递到多个分支中。然而,增加分支数也会导致增加MS-Layers的数量,并降低每个分支中的通道数量。为了调查分支数量(用表示)的影响,作者进行了消融研究。结果见表7。有趣的是,直接增加分支数量并不总是会导致性能提升。
特别地,当= 3时,YOLO-MS达到了最佳性能,AP为43.4%,比= 2高出1.2%,比= 4高出0.2%。因此,作者在所有后续实验中将= 3作为默认设置。
PAFPN模块消融分析
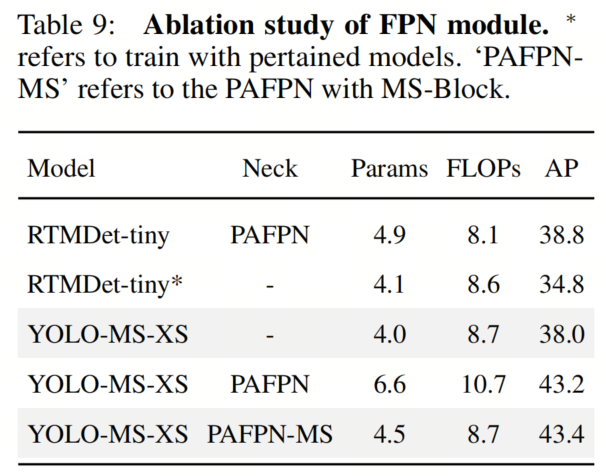
作者对PAFPN模块进行了消融研究,结果见表9。PAFPN是一种广泛应用于其他YOLO模型的流行结构。作者从YOLO-MS中去除PAFPN模块,以进一步验证作者的方法的有效性。
实验结果表明,作者提出的方法在几乎不增加计算成本的情况下,可以产生与不使用预训练权重的PAFPN相近的性能。
此外,作者提出的方法还优于没有PAFPN的Baseline模型。此外,作者的方法与FPN模块是正交的。作者将原始PAFPN与PAFPN-MS(带有MS-Block的PAFPN)进行了比较。如实验结果所示,带有PAFPN-MS的检测器在仅有约60%的参数和约80%的FLOPs的情况下,获得了更好的性能(+0.2% AP)。
图像分辨率分析
在这里,作者进行了一个实验,以研究图像分辨率与多尺度构建块设计之间的关系。作者在推理过程中应用了测试时间增强(Test Time Augmentation),对图像进行多尺度变换(320 × 320、640 × 640和1280 × 1280)。
另外,作者还分别使用这些分辨率进行了测试。需要注意的是,作者在训练中使用的图像分辨率为640 × 640。
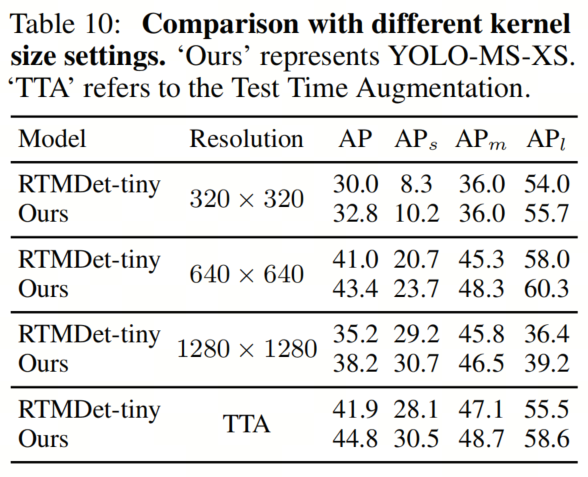
结果见表10。实验结果表明了一个一致的趋势:随着图像分辨率的增加,AP也会增加。然而,低分辨率图像可以实现更高的APl。这也验证了作者的HKS协议的有效性。
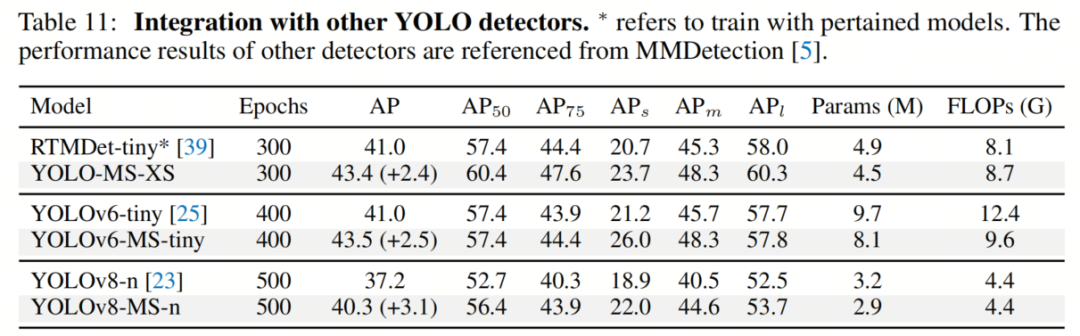
应用于其他YOLO模型
作者的方法可以作为其他YOLO模型的即插即用模块使用。为了展示作者方法的泛化能力,作者将该方法应用于其他YOLO模型,并在MS COCO数据集上进行了全面比较。
3.2、HKS协议分析
在这一小节中,作者进行实验以评估HKS协议的有效性,通过探索不同的卷积Kernel-Size设置。为了简化表示法,作者使用格式[,,,],其中表示第阶段的卷积Kernel-Size。作者研究了具有3、5、7、9和11的均匀卷积Kernel-Size设置,以及HKS的倒置版本,即[9, 7, 5, 3]。
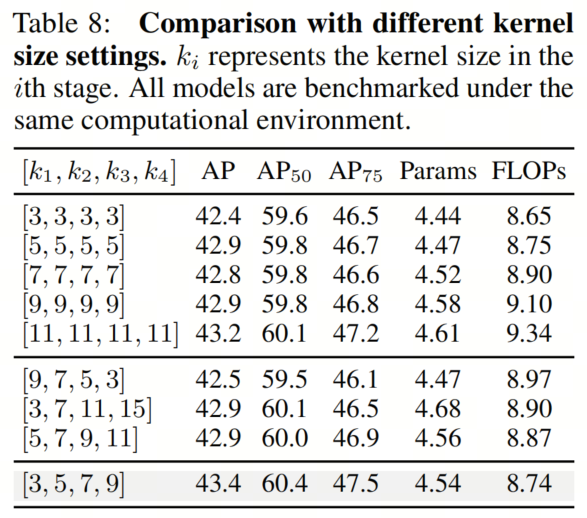
如表8中所示,作者实验的结果揭示了有趣的见解。作者观察到,简单地增加卷积Kernel-Size并不总是会显著提高性能。然而,当作者使用HKS时,作者在性能上取得了显著的提升(43.4%的AP),这优于所有其他均匀卷积Kernel-Size设置。
此外,卷积核在阶段内的排列顺序起着关键作用。具体而言,在浅阶段使用大Kernel,在深阶段使用小Kernel时,性能与HKS相比下降了0.9%的AP。这表明,与浅阶段相比,深阶段需要更大的感受野来有效捕捉粗粒度信息。
考虑到计算成本,作者的HKS因其计算开销最小而脱颖而出。这表明,通过在合适的位置上策略性地放置具有不同卷积Kernel-Size的卷积,作者可以最大程度地高效利用这些卷积。
作者还使用了两种新的设置,[5, 7, 9, 11]和[3, 7, 11, 15]。结果如下表所示。根据结果,直观地可以看出[3, 5, 7, 9]的设置在较低的计算成本下获得了更好的性能。
有效感受野分析
先前的研究引入了有效感受野(ERF)的概念,作为理解深度卷积神经网络(CNN)行为的度量。ERF测量了受特征表示影响的输入空间中的有效区域。在这里,作者进一步利用ERF的概念来研究HKS的有效性。
具体而言,作者测量了编码器的第2、3和4阶段中高贡献像素包含的ERF的边长。
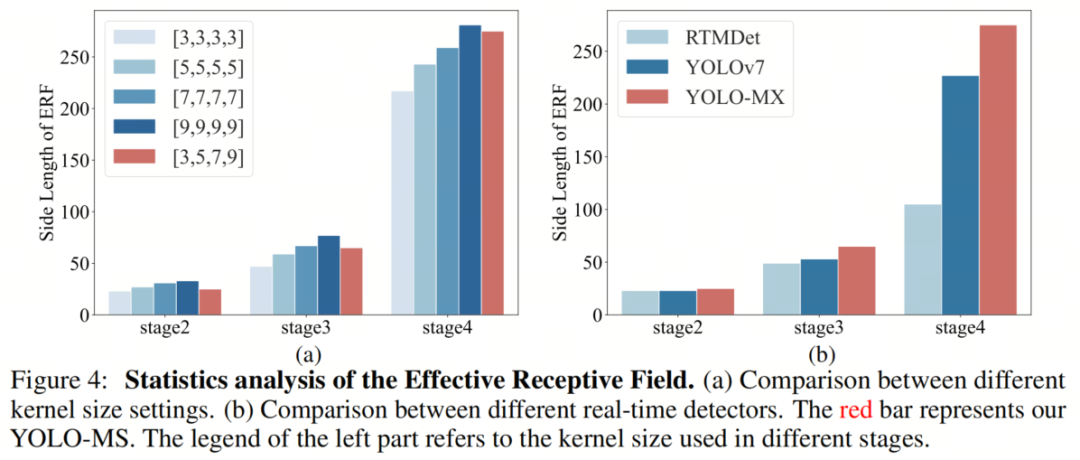
视觉比较如图4所示。如图4(a)所示,随着卷积Kernel-Size的增加,所有阶段的ERF区域也变大,这支持卷积Kernel-Size与感受野之间的正相关性。
此外,在浅阶段,ERF区域小于大多数其他设置,而在深阶段则相反。这一观察表明,该协议在扩大深阶段的感受野的同时,不会损害浅阶段。在图4(b)中,作者可以观察到作者的HKS在深阶段实现了最大的ERF,从而更好地检测大目标。
3.3、Comparison with State-of-the-Arts
1、与CAM的可视化比较
为了评估检测器注意力集中在图像的哪个部分,作者使用Grad-CAM生成类响应图。作者从YOLOv6-tiny、RTMDet-tiny RTMDet、YOLOV7-tiny和YOLO-MS-XS的neck部分生成了类响应图,并从MS COCO数据集中选择了不同大小的典型图像,包括小、中和大的目标。
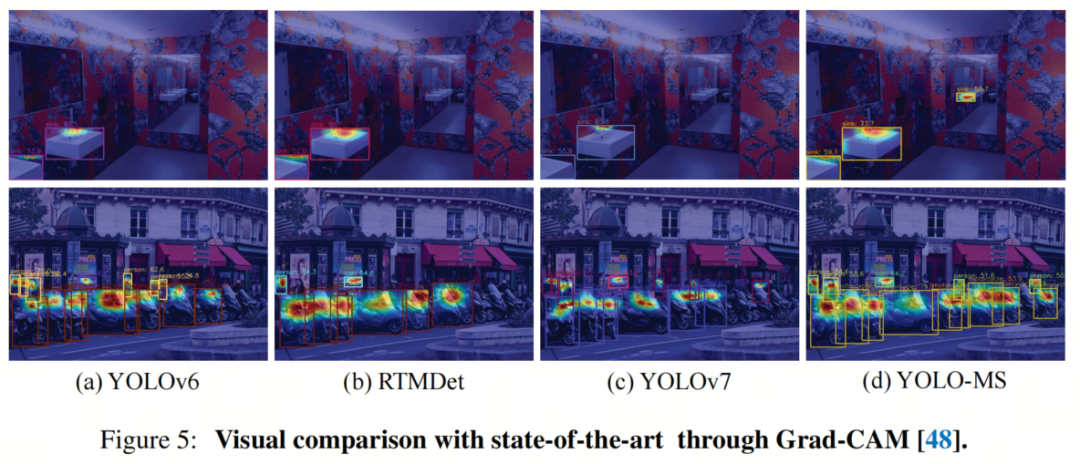
可视化结果如图5所示。YOLOv6-tiny、RTMDet-tiny和YOLOV7-tiny都无法检测到密集的小目标,如人群,而且会忽略目标的某些部分。相反,YOLO-MS-XS在类响应图中对所有目标都展现出强烈的响应,表明其出色的多尺度特征表示能力。此外,它突显了作者的检测器在不同尺寸的目标和包含不同密度目标的图像中都能够实现出色的检测性能。
2、定量比较
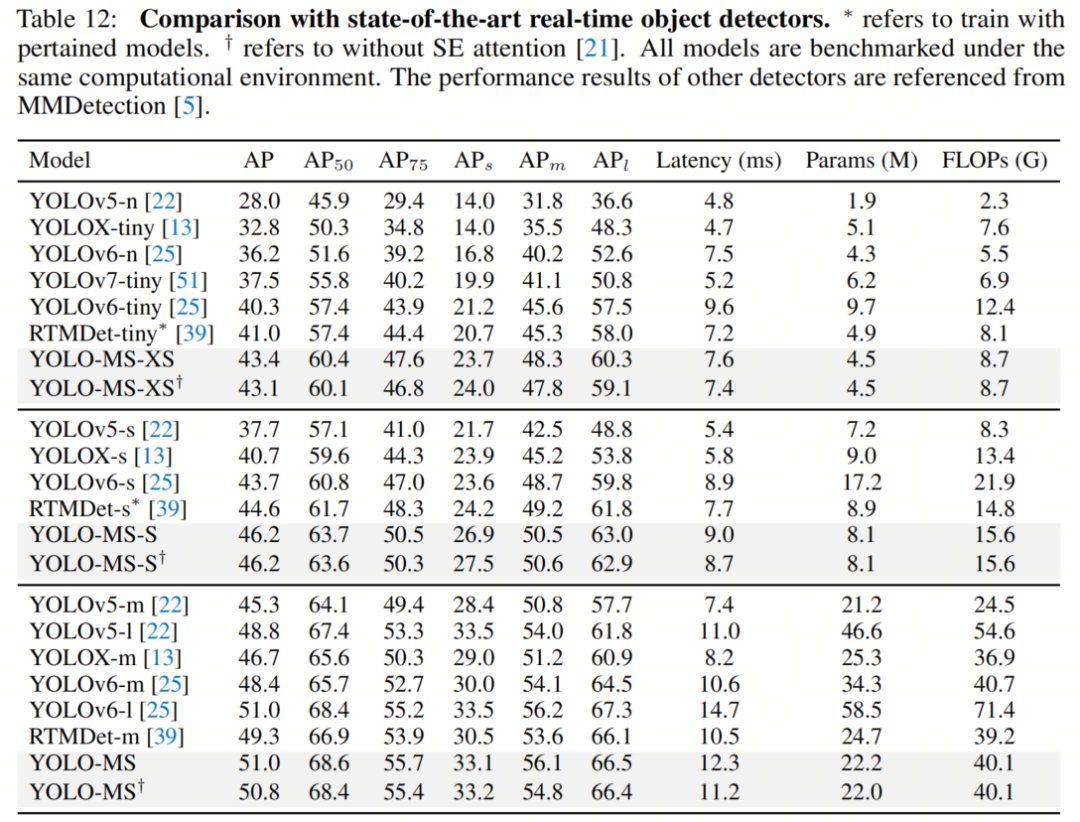
作者将YOLO-MS与当前最先进的目标检测器进行了比较。从表12中,作者可以看到YOLO-MS取得了显著的速度-准确性平衡。与第二好的微型检测器,即RTMDet RTMDet相比,YOLO-MS-XS达到了43.4%的AP,比使用ImageNet预训练模型的AP高了2.3%。YOLO-MS-S达到了46.2%的AP,相比YOLOv6减少了一半的参数大小,带来了5.7%的AP改进。
此外,YOLO-MS表现出51.0%的AP,优于具有相似参数和计算复杂性的最先进的目标检测器,甚至是大型模型,如YOLOv6-M和YOLOv6-L。
总之,YOLO-MS能够作为实时目标检测的有希望的Baseline,提供强大的多尺度特征表示能力。
4、参考
[1].YOLO-MS: Rethinking Multi-Scale Representation Learning for Real-time Object Detection.
5、推荐阅读

AIHIA | AI人才创新发展联盟2023年盟友招募
AIHIA | AI人才创新发展联盟2023年盟友招募

AI融资 | 智能物联网公司阿加犀获得高通5000W融资
AI融资 | 智能物联网公司阿加犀获得高通5000W融资

Yolov5应用 | 家庭安防告警系统全流程及代码讲解

江大白 | 这些年从0转行AI行业的一些感悟
Yolov5应用 | 家庭安防告警系统全流程及代码讲解
江大白 | 这些年从0转行AI行业的一些感悟

《AI未来星球》陪伴你在AI行业成长的社群,各项福利重磅开放:
(1)198元《31节课入门人工智能》视频课程;
(2)大白花费近万元购买的各类数据集;
(3)每月自习活动,每月17日星球会员日,各类奖品送不停;
(4)加入《AI未来星球》内部微信群;
还有各类直播时分享的文件、研究报告,一起扫码加入吧!


大家一起加油! 
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢