
Teach LLMs to Personalize -- An Approach inspired by Writing Education
C Li, M Zhang, Q Mei, Y Wang, S A Hombaiah, Y Liang, M Bendersky
[Google]
教大型语言模型(LLM)个性化 - 受写作教育启发的方法
-
提出一个通用的方法,通过多阶段多任务框架教会大语言模型进行个性化文本生成。
-
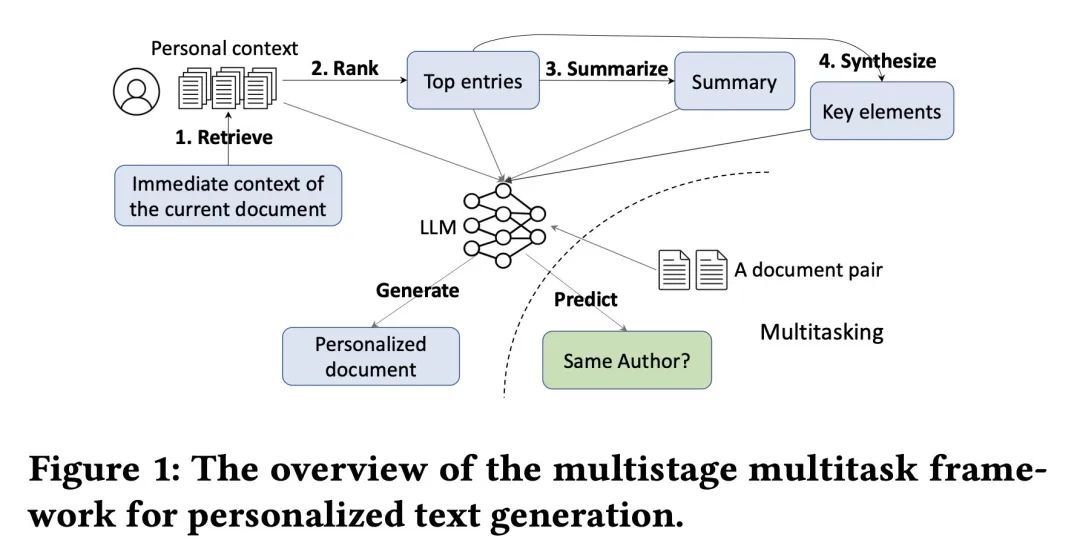
多阶段包括检索、排序、摘要、综合和生成,模仿写作教育中的从源头写作流程,多任务加入作者区分任务,提高“阅读”能力。
-
在三个数据集上的实验表明,该方法显著优于各种基线,特别是上下文相关的摘要和综合进一步提升了性能。
-
多任务学习也普遍提高了模型的生成能力,这与语言教育中写作和阅读技能高度相关的观察一致。
-
单独使用最近的文档产生的效果接近基于相似度的检索,原因可能是用户最近的文档风格和内容相近。
-
删除排名结果后性能大幅下降,说明排名结果对生成仍很重要,即使已经有摘要和综合信息。
-
输入不同信息源顺序变化对性能影响不大。
动机:个性化文本生成是一个新兴的研究领域,在近年来引起了广泛关注。大多数相关研究都专注于设计定制特征或模型来处理特定领域的个性化生成问题。本文提出一个通用的方法,利用大型语言模型(LLM)进行个性化文本生成。受到写作教育的启发,开发了一个多阶段和多任务的框架,用于教授LLM进行个性化生成。
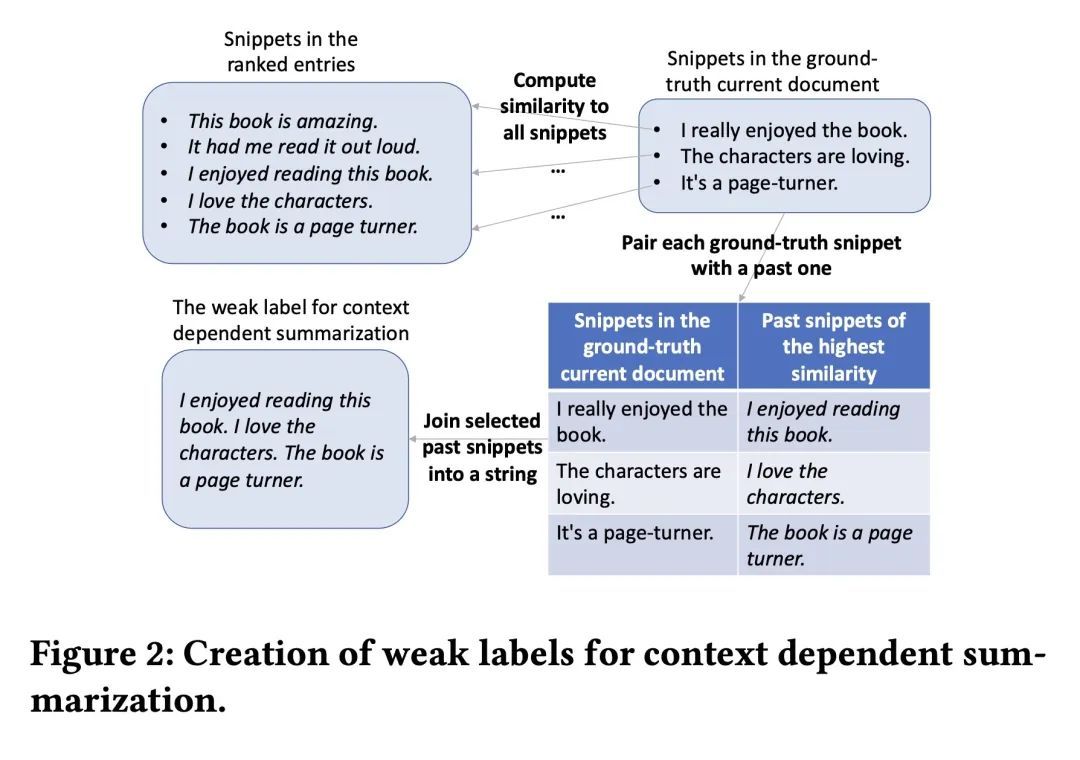
方法:在写作教育中,从源头撰写的任务通常被分解为多个步骤,包括查找、评估、总结、综合和整合信息。类似地,本文的个性化文本生成方法包括多个阶段:检索、排序、摘要、综合和生成。此外,引入了一个多任务设置,进一步帮助模型提高其生成能力,这受到了教育中观察到的阅读能力与写作能力之间的相关性的启发。
优势:在三个公开数据集上评估了提出的方法,每个数据集涵盖不同且具有代表性的领域。结果显示,与各种基线方法相比,所提出的方法取得了显著的改进。
提出一个通用方法,利用大型语言模型进行个性化文本生成,通过多阶段和多任务框架来教授模型生成个性化的文本,取得了显著的改进。
https://arxiv.org/abs/2308.07968
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢