

以下文章来源于知乎:CVHub
作者:派星星
链接:https://mp.weixin.qq.com/s/ZH0DJ9AZ_nsjTS_yVfybkw
本文仅用于学术分享,如有侵权,请联系后台作删文处理

导读
论文链接:https://arxiv.org/pdf/2307.15880.pdf
源码链接:https://github.com/IDEA-Research/DWPose
人体的分层结构、手和脸的小分辨率、多人图像中复杂的身体部位匹配,尤其是遮挡和复杂的手部姿势等。2. 此外,为了部署模型,将其压缩成轻量级网络也是必要的,以更好的满足实时性要求。
第一阶段蒸馏设计了一种权重衰减策略,同时利用教师模型的中间特征和最终的逻辑信息,包括可见和不可见的关键点,来监督从头开始训练的学生模型。 第二阶段蒸馏则进一步提升学生模型的性能。与以前的自知识蒸馏不同,这一阶段仅在20%的训练时间内对学生模型的head部分进行微调,采用即插即用的训练策略。
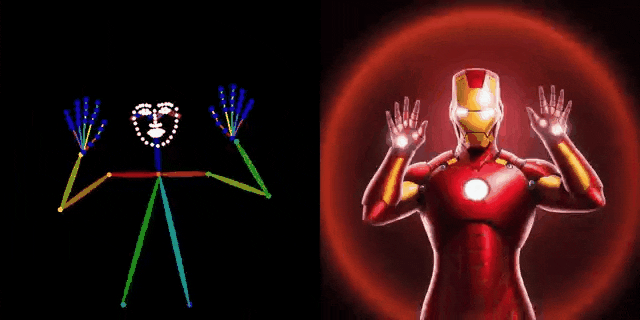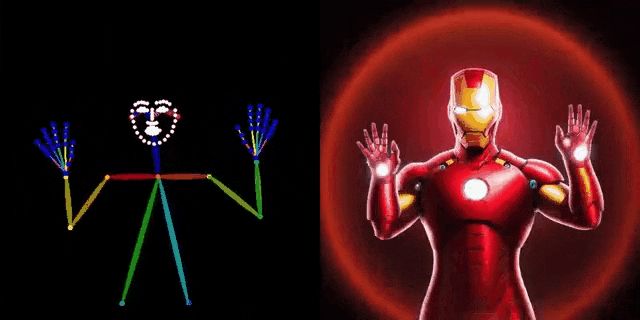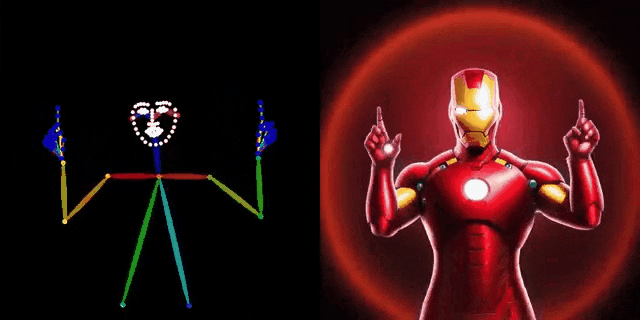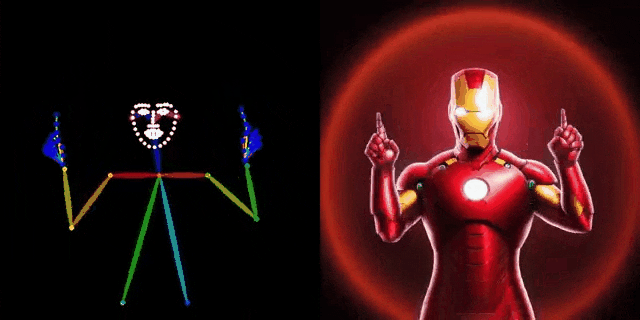
背景介绍
2D Whole-body Pose Estimation
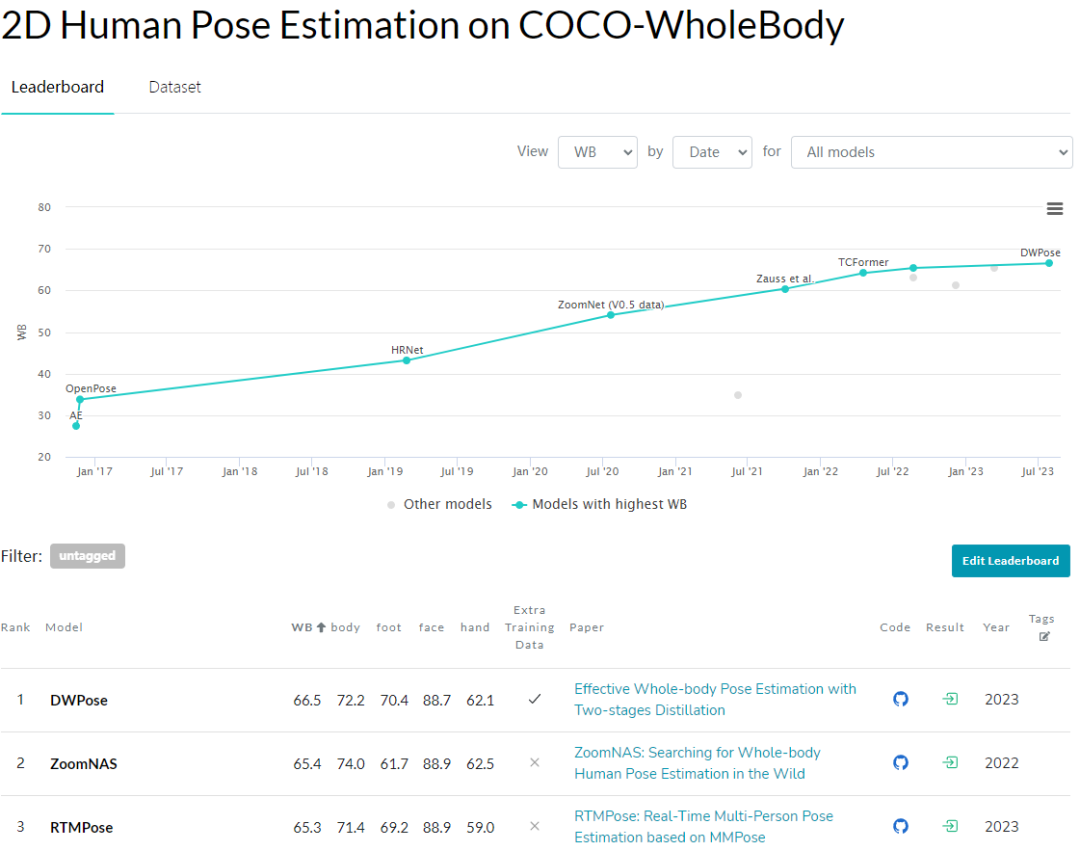
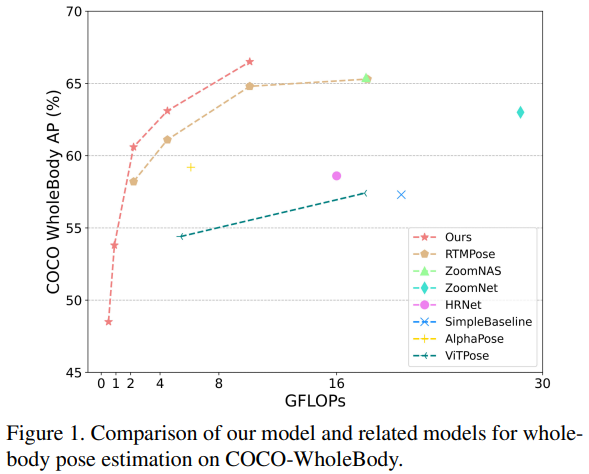
OpenPose:结合不同数据集对不同身体部位进行训练,以实现分离的关键点检测。 MediaPipe:构建了一个感知 pipeline,特别适用于整体人体关键点检测。 ZoomNet:首次提出了一种自顶向下的方法,使用层次结构的单一网络来解决不同身体部位的尺度变化问题。 ZoomNAS:进一步探索了神经架构搜索框架,以同时搜索模型结构和不同子模块之间的连接,以提高准确性和效率。 TCFormer:引入了逐步聚类和合并视觉特征,以在多个阶段中捕捉不同位置、大小和形状的关键点信息。 RTMPose:讨论了姿态估计的关键因素,构建了实时模型,在COCO-WholeBody数据集上取得了最新的成果。但仍然存在模型设计冗余和数据限制,特别是对于多样的手部和脸部姿势。
Knowledge Distillation
方法
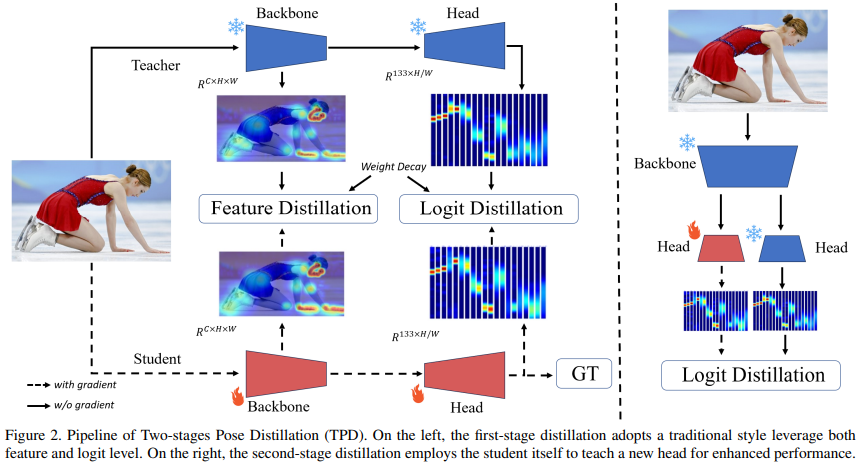
first-stage
基于特征的蒸馏
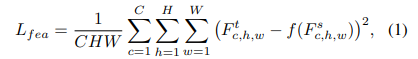
基于逻辑的蒸馏
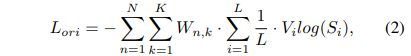
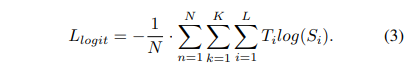
蒸馏的权重衰减策略
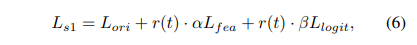
简单小结下,这里我们向大家描述了第一阶段蒸馏的特征和逻辑损失,以及引入的权重衰减策略。通过这些方法,DWPose 可以通过教师模型引导学生模型,实现了对模型的有效蒸馏。
secode-stage
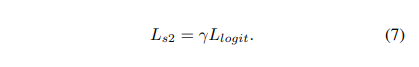
实验
由于超参数等细节对本文方法的复现比较关键,今天我们详细过一遍。
数据集
对于 COCO 数据集,文中采用了 train2017 和 val2017 的标准分割,使用了 118K 张训练图像和 5K 张验证图像。在 COCO 验证数据集上,使用了 SimpleBaseline 提供的通用人体检测器,其平均精度(AP)为 56.4%。 UBody 数据集包含来自 15 个真实场景的超过 100 万帧图像,提供了对应的 133 个 2D 关键点和 SMPL-X 参数。需要注意的是,原始数据集仅关注 3D 全身姿态估计,并未验证 2D 标注的有效性。论文从视频中每隔10帧选择一帧进行训练和测试。
实现细节
对于第一阶段蒸馏,采用公式6中使用了两个超参数 和 来平衡损失。在所有实验中包括在 COCO 和 UBody 数据集上都采用了{α = 0.00005,β = 0.1}。 第二阶段蒸馏有一个超参数 来平衡公式7中的损失,此处 。
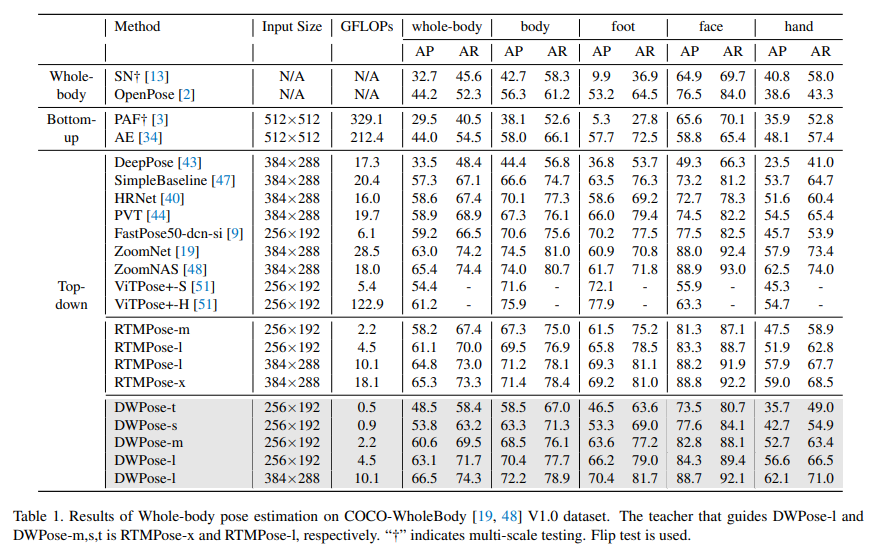
定量分析
定性分析


此外,图4中比较了作者提出的方法与常用的OpenPose和MediaPipe中提供的基线方法。可以看出,DWPose 也显著超越了另外两种方法,特别是在截断、遮挡以及细粒度定位的鲁棒性方面。
泛化性
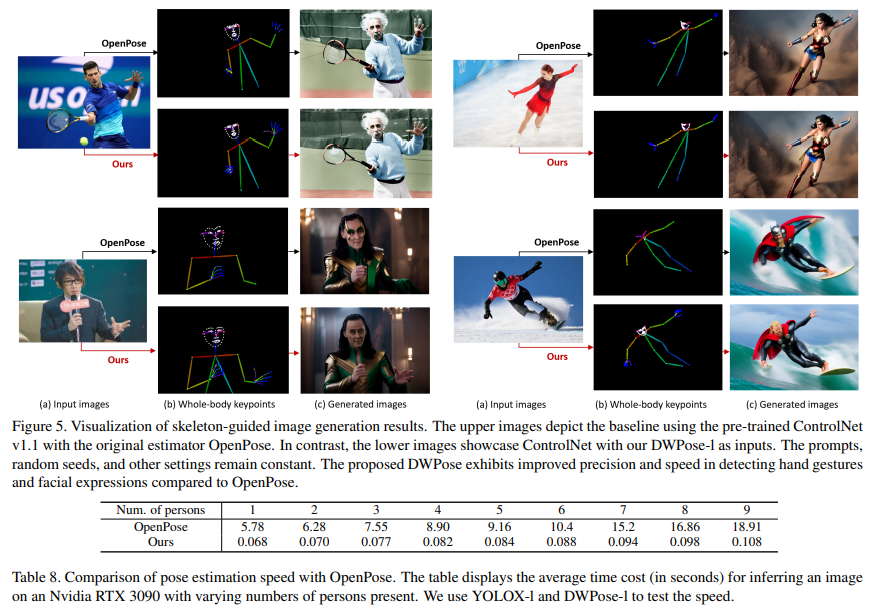
总结
推荐阅读

AIHIA | AI人才创新发展联盟2023年盟友招募
AIHIA | AI人才创新发展联盟2023年盟友招募

AI融资 | 智能物联网公司阿加犀获得高通5000W融资
AI融资 | 智能物联网公司阿加犀获得高通5000W融资

Yolov5应用 | 家庭安防告警系统全流程及代码讲解

江大白 | 这些年从0转行AI行业的一些感悟
Yolov5应用 | 家庭安防告警系统全流程及代码讲解
江大白 | 这些年从0转行AI行业的一些感悟

《AI未来星球》陪伴你在AI行业成长的社群,各项福利重磅开放:
(1)198元《31节课入门人工智能》视频课程;
(2)大白花费近万元购买的各类数据集;
(3)每月自习活动,每月17日星球会员日,各类奖品送不停;
(4)加入《AI未来星球》内部微信群;
还有各类直播时分享的文件、研究报告,一起扫码加入吧!


大家一起加油! 
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢