

人类距离AGI还有多远?也许大语言模型不是最终答案,一个理解世界的模型才是未来的方向。
在人类的认知之中,似乎早已习惯将通用人工智能(AGI)设定为人工智能的终极形态和发展的最终目标。

虽然OpenAI早已把公司的目标设定为实现AGI。但对于什么是AGI,OpenAI CEO Sam Altman自己都没法给出具体的定义。
对于AGI何时能够到来,也只存在于大佬们抛出的一个个近未来的叙事场景之中,似乎唾手可得,但又遥遥无期。
今天,在国外的知名的播客网站Substack上,一位名为Valentino Zocca的人工智能行业资深人士,站在人类历史的叙事立场上,写了一篇雄文,全面而深刻地讲述了人类和通用人工智能之间的距离。
文章中将AGI大致定义为一个「能够理解世界的模型」,而不仅仅是「描述世界的模型」。
他认为,人类要想真正达到AGI的世界,就需要建立一个「能够质疑自身现实、能够自我探究的系统」。
而这个伟大的探索过程中,也许谁都没有资格和能力来给出一个具体的路线图。
正如OpenAI科学家肯尼斯·斯坦利和乔尔·雷曼最近的新书《为什么伟大不能被计划》中阐述的那样,对于伟大的追求是个方向,但是具体的结果可能是意外所得。

大约 20 万年前,智人开始在地球上直立行走,与此同时,他们也开始了在思想和知识的领域中的遨游。
人类历史上的一系列发现和发明塑造了人类的历史。其中一些不仅影响了我们的语言和思维,还对我们的生理构造产生了潜在的影响。
例如,火的发现使原始人能够烹饪食物。熟食为大脑能提供了更多的能量,从而促进了人类智能的发展。
从车轮的发明到蒸汽机的创造,人类迎来了工业革命。电力进一步为我们今天的技术发展铺平了道路,印刷术加快了新思想和新文化的广泛传播,促进了人类创新的发展。
然而,进步不仅来自于新的物理层面的发现,同样也源于新的思想。
西方世界的历史是从罗马帝国衰落到中世纪,在文艺复兴和启蒙运动期间经历了一次重生。
但随着人类知识的增长,人类这个物种开始慢慢认识到自身的渺小。
在苏格拉底之后的两千多年里,人类开始「知道自己一无所知」,我们的地球不再被视为宇宙的中心。宇宙本身在扩张,而我们只是其中的一粒微尘。

但人类对世界的认知的最大改变,发生在20世纪。
1931 年,Kurt Gödel发表了不完备性定理。
仅仅四年后,为了延续「完备性」这一主题,爱因斯坦、Podolsky和 Rosen发表了题为「Can Quantum-Mechanical Description of Physical Reality Be Considered Complete?」(量子力学对于物理实在的描述是完备的吗?)
随后,玻尔(Niels Bohr)对这篇论文进行了反驳,证明了量子物理学的有效性。
Gödel定理表明,即使是数学也无法最终证明一切——人类始终会有无法证明的事实——而量子理论则说明,我们的世界缺乏确定性,使我们无法预测某些事件,例如电子的速度和位置。
尽管爱因斯坦曾表达过「上帝不会与宇宙玩骰子」这一著名的观点,但从本质上讲,仅仅在预测或理解物理中的事物时,人类的局限性就已经体现得淋漓尽致。
无论人类如何努力地尝试设计出一个由人类制定的规则来运行的数学宇宙,但这样抽象的宇宙始终是不完整的,其中隐藏着无法证明又无法否认的客观公理。
除了数学的抽象表述之外,人类的世界还由描述现实的哲学所表述。
但是人类发现自己无法描述、充分表达、理解甚至仅仅是定义这些表述。
20世纪初「真理」的概念依然是不确定的,「艺术」、「美」和「生命」等概念在定义层面也都缺乏基本的共识。
其他很多重要的概念也一样,「智慧」和「意识」同样没有办法被人类自己清晰地定义。
为了填补对于智能定义的空缺,2007年,Legg和Hart在「General Intelligence」一书中提出了机器智能的定义:「智能衡量的是智能体(Agent)在多变环境中实现目标的能力」。
同样,在「Problem Solving and Intelligence」一书中,Hambrick、Burgoyne和Altman认为,解决问题的能力不仅是智能的一个方面或特征,而是智能的本质。
这两种说法在语言描述上有相似的地方,都认为「实现目标」可以与「解决问题」联系起来。

Gottfredson在 「Mainstream Science on Intelligence: An Editorial with 52 Signatories」一书中,从更广阔的视角总结了几位研究者对于智能的定义:
「智能是一种非常普遍的心智能力,包括推理能力、计划能力、解决问题的能力、抽象思维能力、理解复杂思想的能力、快速学习的能力以及从经验中学习的能力。它不仅仅是书本知识、狭隘的学术技能或应试技巧。相反,它反映了一种更广泛、更深层次的理解周围环境的能力——『捕捉』、『理解』事物或『想出』该做什么的能力」。
这一定义使智能的构建超越了单纯的 「解决问题的技能」,引入了两个关键维度:从经验中学习的能力和理解周围环境的能力。
换句话说,智能不应该被看作是一种抽象的找到解决一般问题的方法的能力,而应该被看作是一种具体的将我们从以往经验中学到的东西应用到我们所处环境中可能出现的不同情况的能力。
这就强调了智能与学习之间的内在联系。
在「How We Learn」一书中,Stanislas Dehaene将学习定义为 「学习是形成世界模型的过程」,意味着智能也是一种需要理解周围环境并创建内在模型来描述环境的能力。
因此,智能也需要创建世界模型的能力,尽管不仅仅包括这种能力。
在讨论人工通用智能(AGI)与狭义人工智能(Narrow AI)时,我们经常会强调它们之间的区别。
狭义人工智能(或称弱人工智能)非常普遍,也很成功,在特定任务中的表现往往都能超越人类。
比如这个众所周知的例子,2016年,狭义人工智能AlphaGo在围棋比赛中以 4 比 1 的大比分击败世界冠军李世石,就是一个很好的例子。
不过,2023年业余棋手Kellin Perline利用人工智能没有没有办法应对的战术又在围棋场上替人类扳回了一局,说明了狭义人工智能在某些情况下确实还有局限性。
它缺乏人类那种识能别不常见战术,并做出相应调整的能力。
而且,在最基础的层面上,即使是刚入行的数据科学家,都明白人工智能所依赖的每个机器学习模型,都需要在偏差(bias)和方差(variance)之间取得平衡。
这意味着要从数据中学习,理解和归纳解决方案,而不仅仅是死记硬背。
狭义人工智能利用计算机的算力和内存容量,可以相对轻松地根据大量观察到的数据生成复杂的模型。
但是,一旦条件稍有变化,这些模型往往就无法通用。

这就好比我们根据观测结果提出了一个描述地球的引力理论,然后却发现物体在月球上要轻得多。
如果我们在引力理论知识的基础上使用变量而不是数字,我们就会明白如何使用正确的数值快速预测每个行星或卫星上的引力大小。
但是,如果我们只使用没有变量的数字方程,那么在不重写这些方程的情况下,我们将无法正确地将这些方程推广到其他星球。
换句话说,人工智能可能无法真正 「学习」,而只能提炼信息或经验。人工智能不是通过形成一个全面的世界模型去理解,而只是创建一个概要去表述。
现在人们普遍理解的AGI是指:能够在人类水平或者更高水平的多个认知领域进行理解和推理的人工智能系统,即强人工智能。
而我们当前用于特定任务的人工智能仅是一种弱人工智能,如下围棋的AlphaGO。
AGI代表一种涵盖抽象思维领域各个领域的、具有人类智能水平的人工智能系统。
这意味着,我们所需的AGI是一个与经验一致且能做到准确预测的世界模型。
如「Safety Literature Review」(AGI安全文献综述)中Everitt、Lea和Hutter指出的事实那样:AGI还没有到来。
对于「我们离真正的AGI还有多远」这个问题,不同的预测之间差异很大。
但与大多数人工智能研究人员和权威机构的观点是一致的,即人类距离真正的通用人工智能最少也有几年的时间。
在GPT-4发布后,面对这个目前性能最强大的人工智能,很多人将GPT-4视作AGI的火花。
4月13日,OpenAI的合作伙伴微软发布了一篇论文「Sparks of Artificial General Intelligence:Early experiments with GPT-4」(通用人工智能的火花:GPT-4的早期实验)。
 论文地址:https://arxiv.org/pdf/2303.12712
论文地址:https://arxiv.org/pdf/2303.12712
其中提到:
「GPT-4不仅掌握了语言,还能解决涵盖数学、编码、视觉、医学、法律、心理学等领域的前沿任务,且不需要人为增加任何的特殊提示。
并且在所有上述任务中,GPT-4的性能水平都几乎与人类水平相当。基于GPT-4功能的广度和深度,我们相信它可以合理地被视为通用人工智能的近乎但不完全的版本。」
但就像卡内基梅隆大学教授Maarten Sap所评价的那样,「AGI的火花」只是一些大公司将研究论文也纳为公关宣传的一个例子。
另一方面,研究员兼机器企业家Rodney Brooks指出了人们认识上的一个误区:「在评估ChatGPT等系统的功能时,我们经常把性能等同于能力。」
错误地将性能等同于能力,意味着GPT-4生成的是对世界的摘要性描述认为是对真实世界的理解。
这与人工智能模型训练的数据有关。
现在的大多数模型仅接受文本训练,不具备在现实世界中说话、听声、嗅闻以及生活行动的能力。
这种情况与柏拉图的洞穴寓言相似,生活在洞穴中的人只能看到墙上的影子,而不能认识到事物的真实存在。
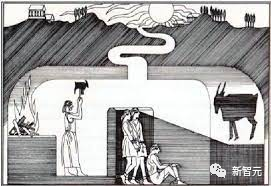
仅在文本上训练的世界模型,仅仅只能保证它们在语法上的正确。但在本质上,它不理解语言所指的对象,也缺乏与环境直接接触的常识。
大语言模型(LLM)最受争议的挑战是它们产生幻觉的倾向。
幻觉指的是模型会捏造参考资料和事实,或在逻辑推断、因果推理等方面颠三倒四、生成毫无意义的内容的情况。
大语言模型的幻觉源于它们缺乏对事件之间因果关系的了解。
在「Is ChatGPT a Good Causal Reasoner? A Comprehensive Evaluation」这篇论文中,研究人员证实了这样一个事实:
ChatGPT这类大语言模型,不管现实中是否存在关系,它们都倾向于假设事件之间存在因果关系。
 论文地址:https://arxiv.org/pdf/2305.07375
论文地址:https://arxiv.org/pdf/2305.07375
研究人员最后得出结论:
「ChatGPT是一个优秀的因果关系解释器,但却不是一个好的因果关系推理器。」
同理,这个结论也可以推广到其他LLM中。
这意味着,LLM本质上只具有通过观察进行因果归纳的能力,而不具备因果演绎的能力。
这也导致了LLM的局限性,如果智能(intelligence)意味着从经验中学习,并将学习得到的内容转化为对理解周围环境的世界模型,那么因果推断作为构成学习的基本要素,是智能不可或缺的一部分。
现有的LLMs正缺乏这一方面,这也是Yann LeCun认为现在的大语言模型不可能成为AGI的原因。
正如20世纪初诞生的量子力学所揭示的,现实往往与我们日常观察所形成的直觉不同。
我们所构建的语言、知识、文本资料、甚至是视频、音频等资料都仅仅只是我们所能体验到的现实的很有限的一部分。
就像我们探索、学习并掌握一个违背我们直觉和经验的现实那样,当我们能够构建一个有能力质疑自身现实、能够自我探究的系统时,AGI才能真正实现。
而至少在现阶段,我们应该构建一个能够进行因果推断、能够理解世界的模型。
这一前景是人类历史上又一进步,意味着我们对世界本质的更深的理解。
尽管AGI的出现将减弱我们对自身独一无二的价值笃定,以及存在的重要性,但通过不断地进步和对认知边界的拓展,我们将更加清楚地认识到人类在宇宙中的地位,以及人类与宇宙的关系。
参考资料:
https://aisupremacy.substack.com/p/how-far-are-we-from-agi
—— End ——
来源:新智元
仅用于学术分享,若侵权请留言,即时删侵!
更多阅读
专家观点:最近Neuralink FDA IDE的真正含义是什么?

加入社群
欢迎加入脑机接口社区交流群,
探讨脑机接口领域话题,实时跟踪脑机接口前沿。
加微信群:
添加微信:RoseBrain【备注:姓名+行业/专业】。
加QQ群:913607986
欢迎来稿
1.欢迎来稿。投稿咨询,请联系微信:RoseBrain
2.加入社区成为兼职创作者,请联系微信:RoseBrain

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢