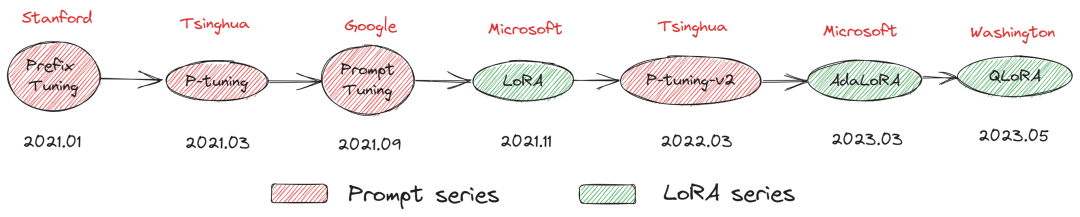
本系列围绕 PEFT 内置七种主流高效调参方法进行原理解析,本文先介绍相关基本概念,再对本期提到的四种 Prompt 技术(Prefix Tuning、P-Tuning、Prompt Tuning、P-Tuning v2)从技术背景、原理和特点三个方面进行展开说明,最后用一张图对本期高效调参技术进行总结和点评。本系列涉及到的七种技术简称和论文标题列表如下
- LoRA: LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
- Prefix Tuning: Prefix-Tuning: Optimizing Continuous Prompts for Generation,
- P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
- P-Tuning: GPT Understands, Too
- Prompt Tuning: The Power of Scale for Parameter-Efficient Prompt Tuning
- AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
- QLoRA: QLoRA: Efficient Finetuning of Quantized LLMs
基本概念
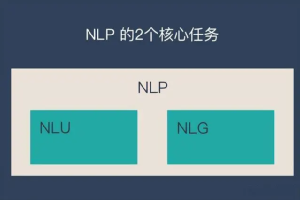
(1)NLU & NLG & NLP
自然语言理解(NLU,Natural Language Understanding): 使计算机理解自然语言(人类语言文字)等,重在理解。具体来说,就是理解语言、文本等,提取出有用的信息,用于下游的任务。它可以是使自然语言结构化,比如分词、词性标注、句法分析等;也可以是表征学习,字、词、句子的向量表示(Embedding),构建文本表示的文本分类;还可以是信息提取,如信息检索(包括个性化搜索和语义搜索,文本匹配等),又如信息抽取(命名实体提取、关系抽取、事件抽取等)。自然语言生成(NLG,Natural Language Generation): 提供结构化的数据、文本、图表、音频、视频等,生成人类可以理解的自然语言形式的文本。NLG又可以分为三大类,文本到文本(text-to-text),如翻译、摘要等、文本到其他(text-to-other),如文本生成图片、其他到文本(other-to-text),如视频生成文本。自然语言处理(NLP,Natural Language Processing):是指计算机系统对自然语言文本进行处理和分析的过程,包括自然语言理解和自然语言生成两个方面。NLP技术是一种涉及计算机科学、人工智能和语言学的交叉学科,旨在使计算机能够理解、处理和生成人类语言。NLP技术的应用包括机器翻译、信息检索、智能对话、情感分析等方面。(2)PLM & Fine-tuning & Prompt-Tuning
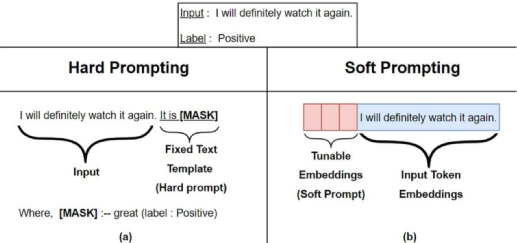
自从GPT、EMLO、BERT的相继提出,以Pre-training + Fine-tuning 的模式在诸多自然语言处理(NLP)任务中被广泛使用,其先在 Pre-training 阶段通过一个模型在大规模无监督语料上预先训练一个预训练语言模型 (Pre-trained Language Model,PLM),然后在 Fine-tuning 阶段基于训练好的语言模型在具体的下游任务上再次进行微调(Fine-tuning),以获得适应下游任务的模型。这种模式在诸多任务的表现上超越了传统的监督学习方法,不论在工业生产、科研创新还是竞赛中均作为新的主流方式。然而,这套模式也存在着一些问题。例如,在大多数的下游任务微调时,下游任务的目标与预训练的目标差距过大导致提升效果不明显,微调过程中依赖大量的监督语料等。至此,以GPT-3、PET(Pattern-Exploiting Training)为首提出一种基于预训练语言模型的新的微调范式一Prompt-Tuning,其旨在通过添加模板的方法来避免引入额外的参数,从而让语言模型可以在小样本 (Few-shot) 或零样本(Zero-shot) 场景下达到理想的效果。Prompt-Tuning又可以称为Prompt、Prompting、Prompt-based Fine-tuning等(3)Prompt & Discrete Prompt & Continuous Prompt Prompt 的功能是组织上下文 x ,目标序列 y ,以及prompt 自己,到一个模板T。例如,在一个预测一个国家的首都的例子中,一个模板T的例子为:“The capital of Britain is [MASK]",这里面,”The capital of ... is ...“是prompt,”Britain“是context,以及[MASK]是目标。离散的模板构建法 (记Hard Template、Hard Prompt、DiscreteTemplate、Discrete Prompt),其旨在直接与原始文本拼接显式离散的字符,且在训练中始终保持不变。这里的保持不变是指这些离散字符的词向量 (Word Embedding)在训练过程中保持固定。通常情况下,离散法不需要引入任何参数。连续的模板构建法 (记Soft Template、 Soft Prompt、 ContinuousTemplate、Continuous Prompt),其旨在让模型在训练过程中根据具体的上下文语义和任务目标对模板参数进行连续可调。这套方案的动机则是认为离散不变的模板无法参与模型的训练环节,容易陷入局部最优,而如果将模板变为可训练的参数,那么不同的样本都可以在连续的向量空间中寻找合适的伪标记,同时也增加模型的泛化能力。因此,连续法需要引入少量的参数并让模型在训练时进行参数更新。Prefix Tuning (2021.01)
论文题目:Prefix-Tuning: Optimizing Continuous Prompts for Generation
论文地址:https://arxiv.org/pdf/2101.00190.pdf论文源码:https://github.com/XiangLi1999/PrefixTuning技术背景
首先,在Prefix Tuning之前的工作主要是人工设计离散的模版或者自动化搜索离散的模版。对于人工设计的模版,模版的变化对模型最终的性能特别敏感,加一个词、少一个词或者变动位置都会造成比较大的变化。而对于自动化搜索模版,成本也比较高;同时,以前这种离散化的token搜索出来的结果可能并不是最优的。其次,传统的微调范式利用预训练模型去对不同的下游任务进行微调,对每个任务都要保存一份微调后的模型权重,一方面微调整个模型耗时长;另一方面也会占很多存储空间。基于上述两点,Prefix Tuning提出固定预训练LM,为LM添加可训练、任务特定的前缀,这样就可以为不同任务保存不同的前缀,微调成本也小;同时,这种Prefix实际就是连续可微的Virtual Token(Soft Prompt/Continuous Prompt),相比离散的Token,更好优化,效果更好。在实际使用时,挑选任务相关的Prefix和Transformer进行组装,实现可插拔式的应用。技术原理
Prefix Tuning在输入token之前构造一段任务相关的virtual tokens作为Prefix,然后训练的时候只更新Prefix部分的参数,而PLM中的其他部分参数固定,Prefix Tuning 针对不同的模型结构构造不同的Prefix。针对自回归架构模型:在句子前面添加前缀,得到 z = [PREFIX; x; y],合适的上文能够在固定 LM 的情况下去引导生成下文。针对编码器-解码器架构模型:Encoder和Decoder都增加了前缀,得到 z = [PREFIX; x; PREFIX0; y]。Encoder端增加前缀是为了引导输入部分的编码,Decoder 端增加前缀是为了引导后续token的生成。技术特点
- 放弃之前人工或半自动离散空间的hard prompt设计,采用连续可微空间soft prompt设计,通过端到端优化学习不同任务对应的prompt参数。
- 同等GPT-2模型尺度下,考虑同等量级的优化参数, 多种数据集测试表明,Prefix优于Adapter等微调方式,且与全量微调fine-tuning效果可比肩

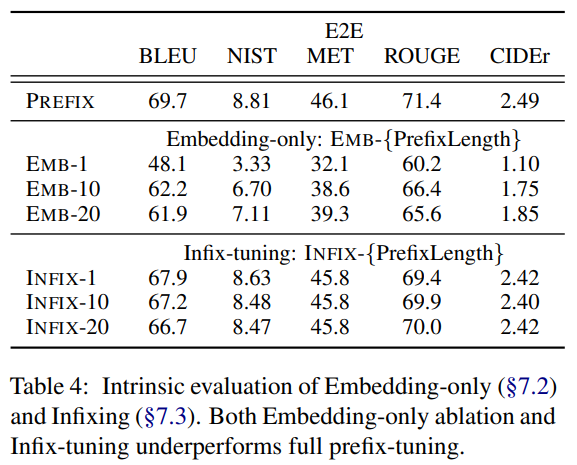
- prefix-tuning性能优于embedding-only ablation,prefix-tuning是优化所有层的prefix, 而Embedding-only仅优化“virtual tokens”在输入embedding层的参数 ,实验表明,prefix-tuning性能显著好于Embedding-onlyprefix-tuning性能略优于infix-tuning,实验还对比了位置对于生成效果的影响,Prefix-tuning也是要略优于Infix-tuning的。其中,Prefix-tuning形式为 [PREFIX; x; y],Infix-tuning形式为 [x; INFIX; y],作者认为这是因为Prefix调优可以影响x和y的激活,而Infix调优只能影响y的激活。
P-tuning (2021.03)
论文题目:GPT Understands, Too论文源码:https://github.com/THUDM/P-tuning论文地址:https://arxiv.org/pdf/2103.10385.pdf技术背景
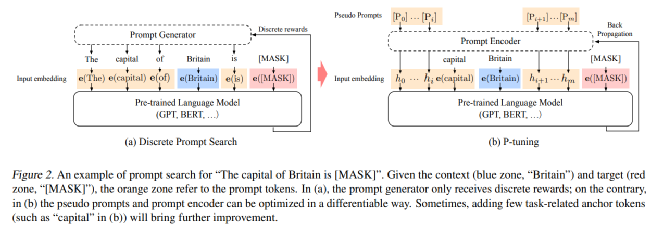
大模型的Prompt构造方式严重影响下游任务的效果,比如:GPT-3采用人工构造的模版来做上下文学习(in context learning),但其对人工设计的模版的变化特别敏感,加一个词或者少一个词,或者变动位置都会造成比较大的变化。人工构建prompt模板不仅成本高,鲁棒性差,而且使用的token也是离散的。如何自动化地寻找连续空间中的知识模板且不用fine-tune语言模型?技术原理
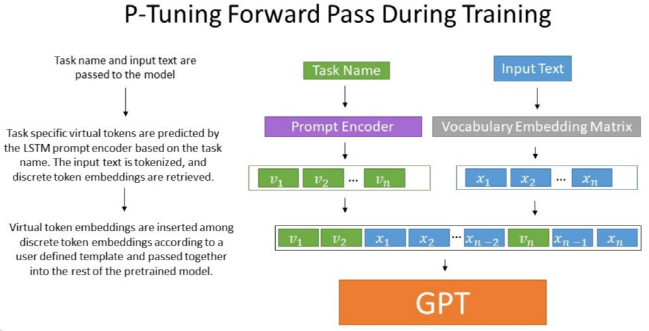
P-Tuning通过在连续空间搜索Prompt搭建了GPT和NLU间的桥梁,设计了一种连续可微的virtual token(同Prefix-Tuning类似),该方法将Prompt转换为可以学习的Embedding层,并用MLP+LSTM的方式来对Prompt Embedding进行一层处理(LSTM起到进行Reparamerization加速训练作用),并引入少量自然语言提示的锚字符(Anchor,例如Britain)进一步提升效果。相比Prefix Tuning,P-Tuning加入的可微的virtual token,但仅限于输入层,没有在每一层都加;另外,virtual token的位置也不一定是前缀,插入的位置是可选的。这里的出发点实际是把传统人工设计模版中的真实token替换成可微的virtual token,在知识探测任务(Knowledge Probing)上,相比人工prompt(离散)方法,P-Tuning v1显著提升效果。技术特点
- 与Prefix Tuning一样,P-tuning放弃了“模版由自然语言构成”这一要求,采用Virtual Token构造soft prompt,通过端到端方式在连续空间优化propmt参数,P-tuning应用于NLU
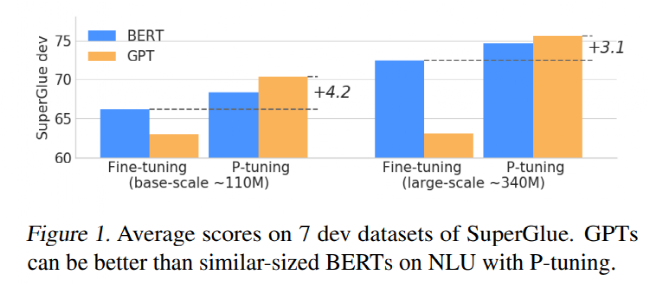
- 通过P-tuning,GPT与Bert在NLU任务上性能相当(甚至超过),证明了之前GPT在NLU方面的能力被低估
- 考虑到这些伪标记的相互依赖关系: 认为 [v1]与[v2]是有先后关系的,而transformer无法显式地刻画这层关系,因此引入Prompt Encoder,实际过程中采用一层RNN
- 指定上下文词: 如果模板全部是伪标记,在训练时无法很好地控制这些模板朝着与对应句子相似的语义上优化,因此选定部分具有与当前句子语义代表性的一些词作为一些伪标记的初始化 (例如上图中“capital”、“Britain”等)
- 混合提示 (Hydride Prompt) : 将连续提示与离散token进行混合,例如 [x][it][v1][mask]
- P-tuning中prompt embedding与 input embedding在人工规则设计下“穿插组合”输入大模型,具体如何“穿插”需要人工考虑的,再者P-tuning使用了自然语言提示的锚字符,这仍然需要人工设计,并不是完全自动化的。
Prompt Tuning (2021.09)
论文地址:https://arxiv.org/pdf/2104.08691.pdf论文题目:The Power of Scale for Parameter-Efficient Prompt Tuning论文源码:https://github.com/google-research/prompt-tuning技术背景
最近有人提出了几种自动化提示设计的方法,例如Shin等人(2020)提出了一种基于下游应用训练数据指导的单词离散空间搜索算法。虽然这种技术优于手动提示设计,但与模型在连续空间自动调优搜索相比仍有差距。技术原理
Prompt Tuning 固定整个预训练模型参数,只允许将每个下游任务的额外 k个可更新的 tokens 前置到输入文本中,也没有使用额外的编码层或任务特定的输出层,对于超过10亿个参数的模型,只需要不到0.01%的特定于任务的参数,Prompt Tuning可以看作是Prefix Tuning的简化版本,它给每个任务定义了自己的Prompt,然后拼接到数据上作为输入,并且不需要加入 MLP 进行调整来解决难训练的问题。技术特点
- Prompt Tuning将之前manual or automate prompt design等在离散空间搜索prompt的方法改进为在连续可微参数空间,通过端到端方式自动搜索。
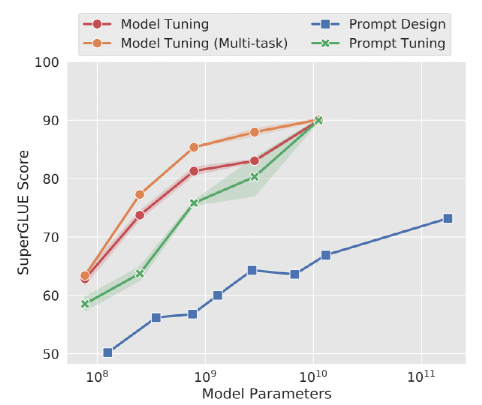
- 随着模型参数的增加(达到10B级),auto prompt Tuning才能与Fine-tuning效果相比肩,但Prompt Tuning在小模型上性能不佳。
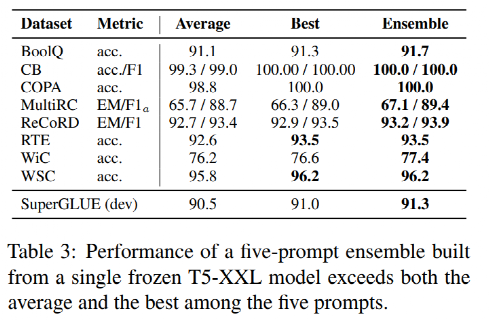
- 提出了 “prompt ensembling”概念,并展示它的有效性,在冻结T5-XXL model基础上,对SuperGLUE每个任务训练5个prompt,推理过程采用投票法如下图,得到集成性能如下表
- Prompt Tuning舍弃了P-tuning中人工设计环节,直接添加prompt作为输入来消除前述复杂性。
P-tuning-v2 (2022.03)
论文题目:P-Tuning v2: Prompt Tuning Can Be Comparable to Finetuning Universally Across Scales and Tasks论文源码:https://github.com/THUDM/P-tuning-v2论文地址:https://arxiv.org/pdf/2110.07602.pdf技术背景
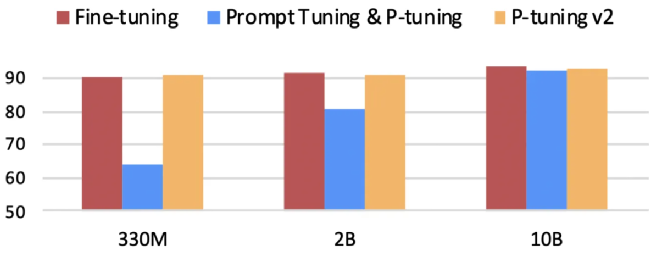
为解决Prompt tuning和P-tuning在小模型、硬序列标记(如NER)及跨任务上效果不佳(如下图)的问题,作者提出了P-tuning V2,严格讲,P-tuning V2并不算一个新方法,它其实是Deep Prompt Tuning 技术的一个优化和适应实现,是对pseudo token采用更深的表征。技术原理
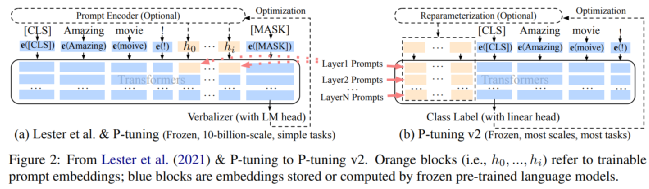
相较于P-tuning v1(或Prompt Tuning),P-tuning v2重要的改进之一是将连续提示应用于预训练模型的每个层,而不仅仅是输入层。P-tuning v2与Prefix-Tuning方法类似,不同之处在于Prefix-Tuning是面向文本生成领域(NLG),P-tuning V2面向自然语言理解(NLU),但两者技术本质完全相同。下图是Prefix-tuning (P-tuning V2)与Prompt-Tuning对比 (黄色部分表示可训练的参数,蓝色表示被冻结的参数)通过增加prompt可调参数量,并针对各种设置(特别是针对小模型和难任务),P-tuning v2提高了与Fine-tuning相媲美的性能。此外,作者还介绍了一系列关键的优化和实现细节(移除了Reparamerization加速训练方式、使用一种自适应的剪枝策略去除大模型中冗余参数等),以确保实现Fine-tuning的性能表现。技术特点
- P-tuning v2 有更多任务相关的可调参数,from 0.01% to 0.1%~3%。
- prompts与更深层相连,对模型输出产生更多的直接影响。
- prompt length 在 P-Tuning v2 中 扮演很重要角色,不同NLU任务最佳性能对应不同prompts长度,一般而言,简单的分类任务倾向较短prompts,硬序列标注任务(hard sequence labeling)倾向较长prompts。
- 采用多任务学习优化,基于多任务数据集的Prompt进行预训练,然后再适配的下游任务。
- 舍弃了词汇Mapping的Verbalizer的使用,重新利用[CLS]和字符标签,跟传统finetune一样利用cls或者token的输出做NLU,以增强通用性,可以适配到序列标注任务。
- 在不同规模大小的LM模型上,仅需微调0.1%-3%的参数,P-tuning v2能与精调(Fine-tuning)方法的表现比肩,有时甚至更好,解决了Prompt Tuning无法在小模型上有效提升的问题。
- 将Prompt Tuning拓展至NER等复杂的NLU任务上。
- P-tuning v2就是将Prefix-tuning应用到NLU任务上的一种方法。
行文最后,我们提炼以上四种高效参数微调的方法,并尽可能的用一张图表示如下,以Prefix Tuning为例,文章采用的性能评估数据集包含WebNLG、DART、E2E,该技术属于soft prompt,作用于NLG领域,优化所有层prefix参数,文章提到的效果与全量微调FT可比肩,其它依次类推;除Prefix Tuning用于NLG任务外,其它三种均用于NLU;P-Tuning和Prompt Tuning技术本质等同,Prefix Tuning和P-Tuning V2技术本质等同,只是前者用于NLG,后者用于NLU。整体而言,以上Prompt series技术演进路线不统一,存在些许矛盾,例如与Prefix Tuning对比,Prompt Tuning 将其相对可调参数少、实现简单作为优点,而当P-Tuning V2与Prompt Tuning 对比时,将其可训练参数多作为优点,且认为优化多层prefix对最终预测输出能产生更直接的影响(如下文章片段所述)诸如此类解释给人一种矛盾、牵强的感觉,野马认为大部分AI系列论文学习的侧重点不在于文章中给出的“数学性”、“原理性”的解释,而在于文章模型相关性设计思想及源代码,你觉得呢? ---- END----
END----参考博客
https://zhuanlan.zhihu.com/p/623529964https://zhuanlan.zhihu.com/p/635686756https://zhuanlan.zhihu.com/p/391992466https://blog.csdn.net/qq_36426650/article/details/120607050
本文转载自社区供稿内容,不代表官方立场。了解更多,请关注微信公众号:
如果你有好的文章希望通过我们的平台分享给更多人,请通过这个链接与我们联系:
https://hf.link/tougao
内容中包含的图片若涉及版权问题,请及时与我们联系删除











评论
沙发等你来抢