
论文作者 | 戚张扬 王佳琦 吴虓杨 赵恒爽
编辑 | 计算机视觉CV

本文研究的自动驾驶领域中的多视图3D目标检测,用的是目前较为先进的基于鸟瞰图视角(Bird's-Eye-View (BEV))的范式。在鸟瞰图(BEV)的视角下,可以避免2D图片中的遮挡问题,并且可以和地图相结合,展开多种下游任务(如:车道线检测)。目前建立BEV的方法有自底向上的做法即由多视角图片及其深度信息构建视锥最终得到BEV。而更好的方法是自顶向下的,预先定义BEV空间初始化特征,在通过Transformer与每个图像特征进行交互,最终得到BEV特征。类似于BEVFormer。
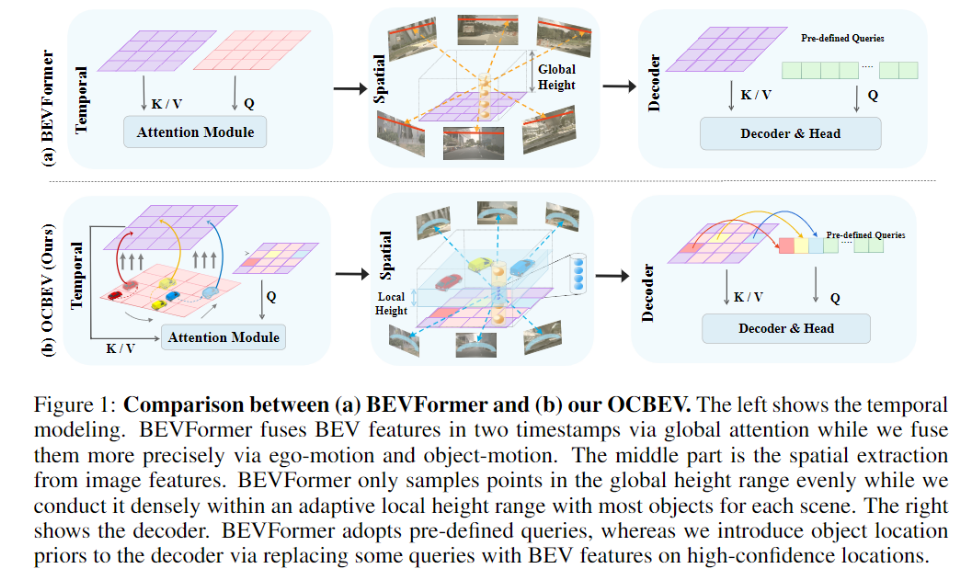
在构建BEV的过程中,有两个关键的点:一个是如何从历史的BEV特征中获取信息,一个是如何使得BEV特征进行与多视角的图片进行交互。即从时间和空间的角度来得到丰富BEV特征的信息。之前的方法都是将BEV特征视作一个整体去进行对齐操作。这里存在一个问题,就是没有考虑到室外场景是稀疏的,并且其中的汽车等交通工具是在高速移动中的。经过Encoder得到的BEV特征,还需要经过Decoder得到最终的结果。这里的Decoder大多采用DETR的范式。这里的queries也是预先定义的,需要从BEV稀疏的特征中学习最终的目标检测结果。同样是忽略了移动中的前景物体的提示。总结下,现有的自顶向下基于Transformer鸟瞰图视角的多视角图片3D目标检测有如下问题:
在与历史BEV信息融合的过程中,只考虑了整体层面将BEV进行对齐,忽略了场景中稀疏的高速移动的前景物体。 在从BEV空间通过Transformer与2D图片进行交互的过程中,在高度方向,采用全局高度均匀采样,使得较多3D参考点投影到了2D的图像上的背景部分。 对于DETR范式Decoder,使用预先定义的queries和整个BEV特征进行Hungarian匹配的难度较大。
这篇论文聚焦与从移动物体前景的角度来解决上述的三个问题。如图所示,与BEVFormer相比,我们进行了三点改进:
我们在时间空间使用物体时间维度对齐融合(Object Aligned Temporal Fusion), 整体上会根据载具的Ego-motion和历史的BEV特征融合。同时也会使用对齐其中高速移动的物体(Object-motion)。 对于空间上与2D图像的互动,我们针对3D参考点的高度,提出了自适应的一个高度范围,这个范围内包含了大部分的前景物体。 我们在Encoder后面添加一个heatmap作为监督,将置信度较高的Queries作为位置编码输入到Decoder中,即给予物体位置信息的提示。
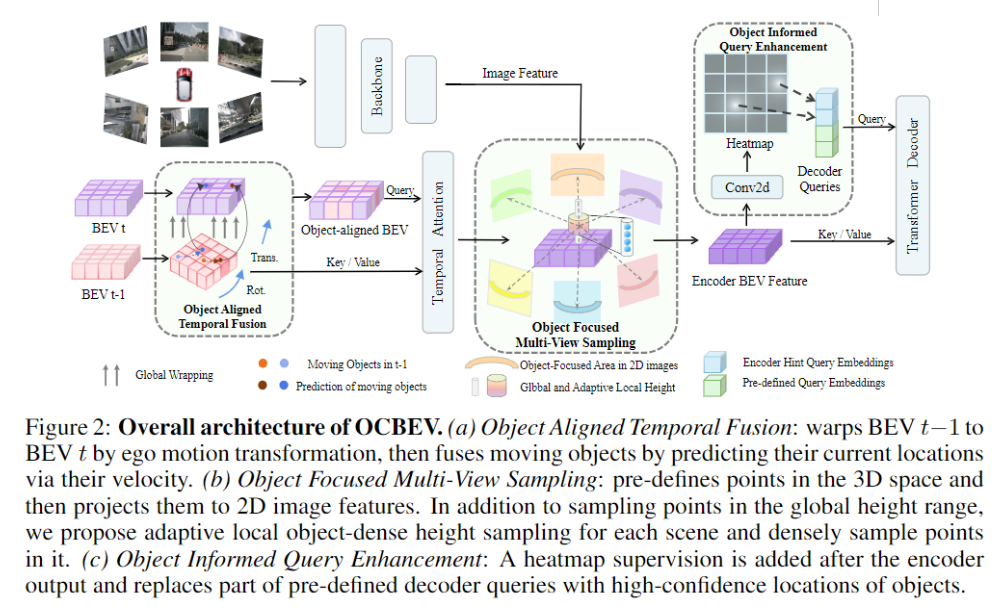
我们的整体结构如图2所示。
我们首先对预定义的BEV Queries通过Encoder,我们引入了目标对齐的时间融合,考虑了背景和移动物体,通过Ego-Motion和Object-Motion进行时间融合,并使用Transformer在融合后的BEV特征之间进行交互。 在这之后对于空间信息,我们使用基于BEVFormer的空间Cross-Attention的面向物体的多视图采样方法,预测前景物体区域内的自适应局部高度,并在2D图像特征上进行投影,形成一个移动物体密集分布的条形区域。 在Encoder后,我们构建了目标信息增强,包括预测物体中心性的Heatmap,并将高置信度位置替换掉Decoder中部分预定义的Queries来提供位置提示。经过Decoder后,我们使用一个目标检测头来预测最终结果。
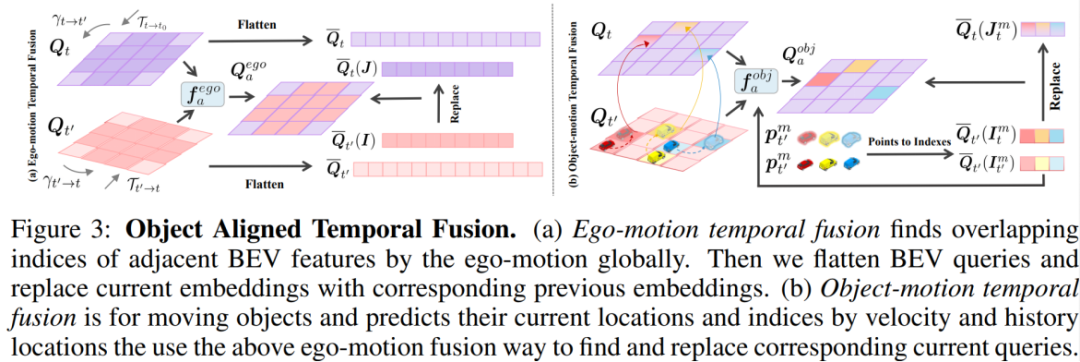
我们引入了一种名为“Object Aligned Temporal Fusion(目标对齐的时间融合)”的方法,旨在增强基于BEV(鸟瞰图)的目标检测器中的时间信息建模,以更好地处理复杂和动态的自动驾驶场景。如图3所示,方法涵盖了两个关键的时间融合步骤,分别是Ego-Motion(自我运动)时间融合和Object-Motion(物体运动)时间融合,从而能够更全面、更有效地捕捉时间信息。

对于Object-Motion(物体运动)时间融合,如图3右图所示。我们

总结一下:
Ego-motion Temporal Fusion(自我运动时间融合):通过对BEV特征进行双向变换,我们能够将当前时间戳的查询特征与先前时间戳的特征对齐。这种方法捕捉了车辆主体的自我运动信息,有助于更好地模拟驾驶场景。 Object-motion Temporal Fusion(物体运动时间融合):在处理移动物体方面,我们预测了物体的运动速度,并在当前时间戳上计算其预测位置。通过将预测位置与先前时间戳上的对应位置对齐,我们能够更好地跟踪移动物体的位置变化,捕捉动态场景中的物体运动特征。
在对时间的对齐之后,是在空间层面上完成BEV特征和2D图像特征的交互。这种交互同样基于Deformable DETR进行的。首先BEV特征作为queries,在3D空间中定义参考点,将它们投影到2D图像特征得到key和value。3D参考点的xy坐标是BEV query的覆盖区域中心,而z坐标是在一个全局高度范围内进行平均采样。(例如对于nuscenes数据集,这个高度范围为-3m到5m)
Object Focused Multi-View Sampling来预测自适应的局部高度范围,以包含大多数前景物体。 我们定义一个局部高度范围(例如对于nuscenes数据集,这个高度范围为-2m到2m),这个局部范围内包含了大多数的物体。 在这个局部高度范围的基础上,我们提出了一个自适应高度范围,以适应其余在局部高度范围之外的物体。让采样点的范围可以动态调整。
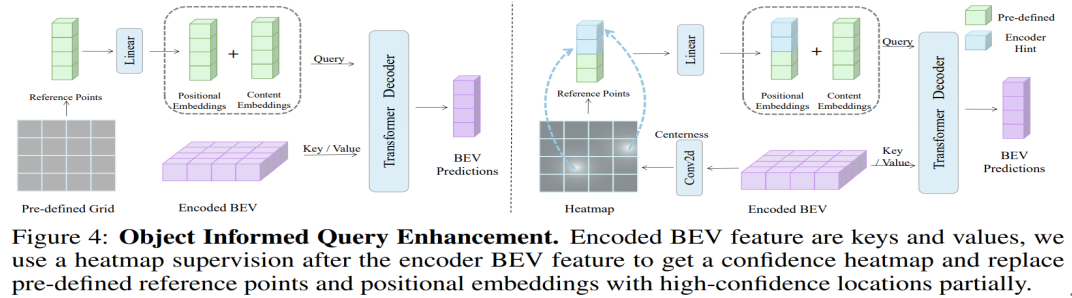
在经过Encoder之后的Encoded BEV特征。我们将使用Decoder解码。图4左侧为我们显示了传统的Decoder,按照deformable DETR的方式,将Queries分为内容和位置embeddings。这里内容和位置embeddings均是预先定义的。为了能让Encoder输出向Decoder传递位置提示,以增强位置信息,OCBEV的结构如图4右所示:
我们在Encoder输出后添加了一个heatmap监督。引入了物体中心度的概念,用于表示对象的位置信息,通过2D高斯分布表示,并且通过二进制交叉熵损失对物体中心度进行训练。 我们使用heatmap中高置信度位置的BEV特征来部分替换预定义的查询。 我们只替换部分的位置embeddings,所有内容部分的embeddings我们都不进行替换。
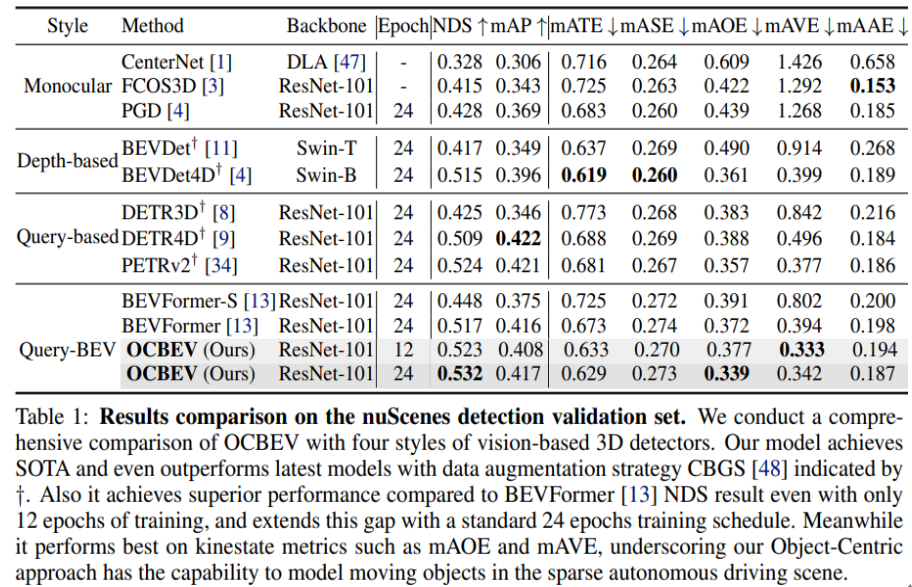
在 nuScenes 验证集上,将我们的实验结果与其他基于视觉的3D检测方法进行比较,尤其是基于查询的视觉方法。与当前的最先进查询方法 BEVFormer 相比,OCBEV 在验证集上的性能超过1.5个点。此外,OCBEV 在与相同主干网络和训练进度的情况下,比 DETR4D 高出2.3个点,比 PETRv2 高出0.8个点。 此外,OCBEV 的收敛速度比现有方法更快。在仅有一半的训练进度(12个epoch)下,OCBEV 的 NDS 比 BEVFormer 的24个epoch结果高出0.6个点。 所提出的面向对象的模块的优势还在运动学指标中得到体现。基于运动状态的度量,如方向(mAOE:33.9%)和速度(mAVE:33.3% 和 34.2%),在所有现有方法中优于 BEVFormer,在平移(mATE:62.9%)方面表现最佳。这证明我们的方法更加关注移动对象,可以自然地提高整体性能。
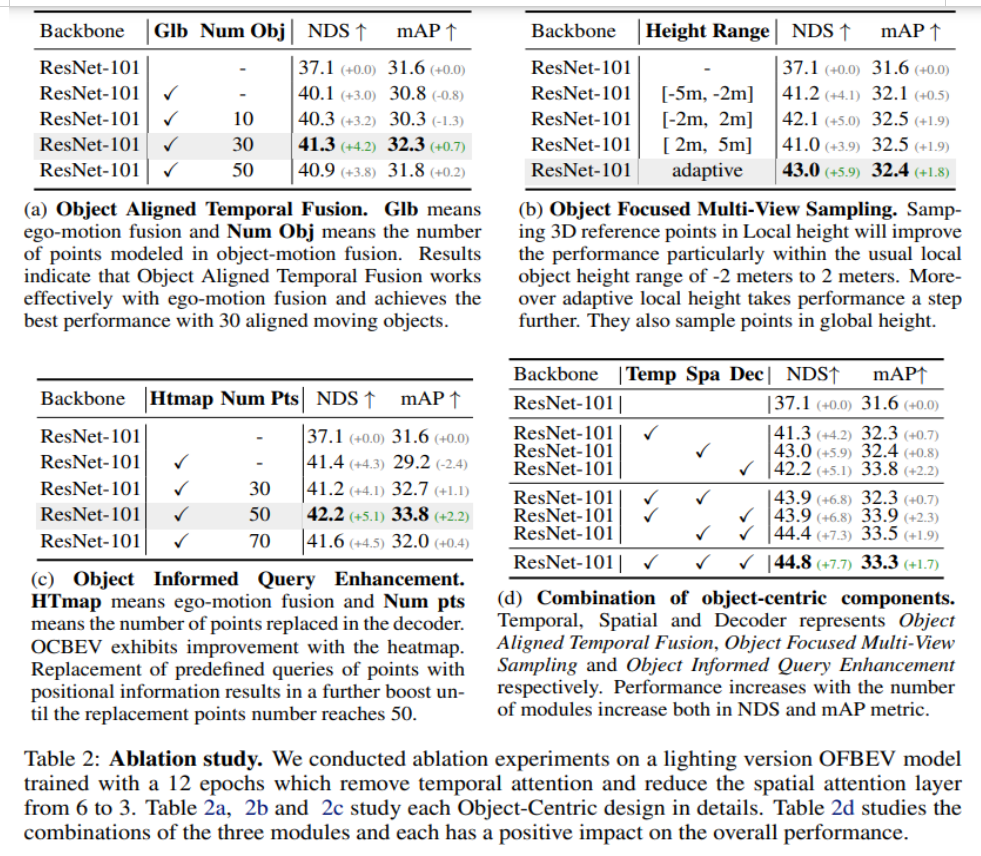
这里的实验baseline配置与主要结果中的配置不一样。我们的消融实验结果如下:
Object Aligned Temporal Fusion的加入提升了NDS,全局对齐和物体自我运动对齐融合都产生了积极影响,最佳效果出现在30个物体上。 Object Focused Multi-View Sampling表明,关注物体密集的局部高度范围可以获得显著的性能提升,自适应高度范围也有益于结果的改善。 Object Informed Query Enhancement证明了热图监督和替换位置嵌入对于提升NDS具有积极作用,达到了41.4%和42.2%的NDS。 三个物体模块的组合分别在时间、空间和Decoder方面产生贡献,完整版本相较于基准线性能提升了7.7个百分点,达到了44.8%的NDS。
基于Query的BEV模式兼具BEV感知能力和端到端训练的优势。大多数3D BEV检测器忽视场景中的移动对象,只是全局地利用时间和空间信息。在本研究中,我们提出了一种新颖的面向前景物体的自顶向下基于查询的BEV检测器,即OCBEV。其中包括三个模块:Object Aligned Temporal Fusion(目标对齐的时间融合)、Object Focused Multi-View Sampling(物体集中的多视角采样)和Object Informed Query Enhancement(物体信息增强的查询),分别专注于实例级别的时间建模、空间利用和Decoder增强。我们的结果在nuScenes基准测试上展现了其强大能力,并且收敛速度更快,因为仅需要一半的训练迭代次数就可以达到可比较的性能。


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢