
一、再谈大模型外挂知识库问答的一些有趣观点和社区讨论
今天社区抛出了一个些趣的话题,主题是llm+本地知识库是个长期任务,超长文本存储和检索精度低,并且单独利用向量化并不能很好地解决这个问题。
针对这个话题,我们先看看这周看到的一个有趣的方案,文章《https://blog.abacus.ai/blog/2023/08/10/create-your-custom-chatgpt-pick-the-best-llm-that-works-for-you/》中介绍了一个组合选择的行业问答方案,示意图如下:
 其核心思想在于为用户提供AutoML功能,以迭代各种组合,包括微调LLM,并找到最适合用例的组合。
其核心思想在于为用户提供AutoML功能,以迭代各种组合,包括微调LLM,并找到最适合用例的组合。其实现的一个重要部分就是进行组合性能评估,除了文档外,其使用此评估集将其与上述每个组合生成的响应进行比较,以确定最佳组合。
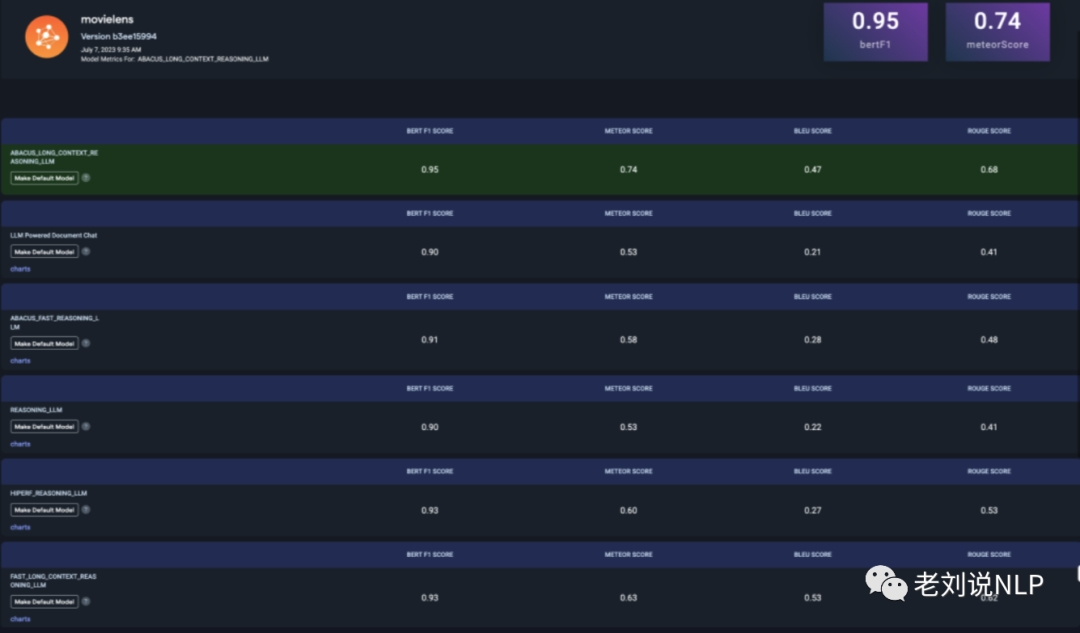
在指标方面,使用包括ROUGE等方法,上述每个分数都属于0比1的范围内,较高的分数表示模型性能优异。
接着,我们再来看看,其中关于向量化的一个有趣观点,很值得参考。文档地址:https://whjlnspmd6.feishu.cn/wiki/DBnWwik1piTB6Iki02CcXoVQn3S,引用到此,供大家一起参考:

里面的核心观点为:
首先,向量化就不是唯一解,也不是全场景最优解。
第一,向量化匹配是有能力上限的。搜索引擎实现语义搜索已经是好几年的事情了,为什么一直无法上线,自然有他的匹配精确度瓶颈问题。
第二,本质是匹配问题(即找到语义相似知识),NLP领域原本也有更优美,更高效的方案,只是这波热潮里,很多以前没接触过AI的朋友对之不熟悉罢了。
第三,甚至不用AI技术,用精确MVSOL、用策略规则也是一种解法,其至是重要解法。旧AI时代的产品同学会非常熟悉这种“用规则/策略/产品设计”来弥补AI能力赢弱的问题一一现在是因为行业早期,大家被LLM的能力错误迷惑,并且以往产品经理的声音还没发出来而已。
其次,在引入外部知识这个事情上,如果是特别专业的领域,纯粹依赖向量、NLP、策略/规则在某些场景仍然不奏效。因为模型首先需要掌握那个领域的专业知识,才能在这样一个基础能力的加持下,用向量化等手段来便捷地解决外部知识引入问题。
当在模型在基础知识中缺乏、或有错误地学习到某些背景知识,即使他有外部知识库加持也是无效的最后,不要管是不是90%会被解决,对于某个具体业务而言,没有90%,只有100%和0%;
上述方法其实是一种集成的思想,我们最后开看看社区的一些观点:
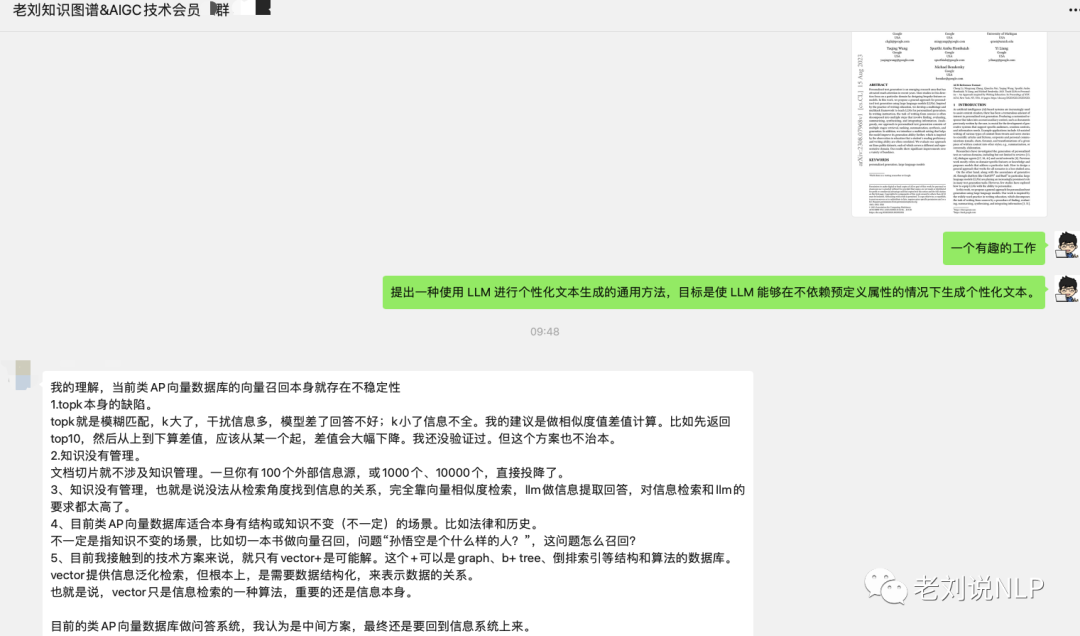
更改topk固然重要,但不够鲁棒。坦白说,当前的做法很多都是打补丁的方法。
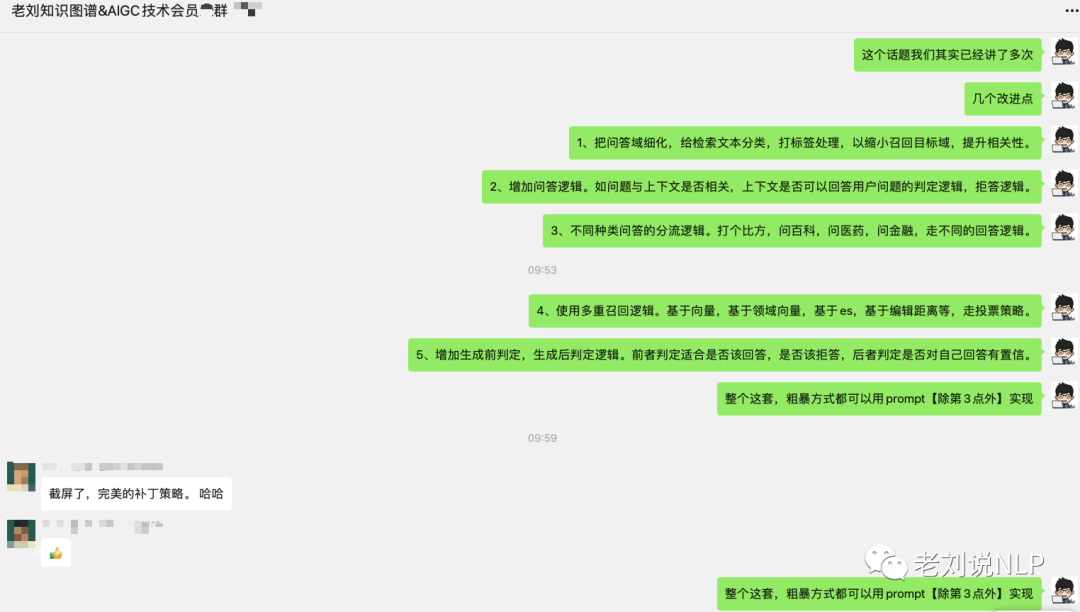
我更倾向于总结为如下的补丁策略,这个认知很有必要。
1、把问答域细化,给检索文本分类,打标签处理,以缩小召回目标域,提升相关性。
2、增加问答逻辑。如问题与上下文是否相关,上下文是否可以回答用户问题的判定逻辑,拒答逻辑。
3、不同种类问答的分流逻辑。打个比方,问百科,问医药,问金融,走不同的回答逻辑。
4、使用多重召回逻辑。基于向量,基于领域向量,基于es,基于编辑距离等,走投票策略。
5、增加生成前判定,生成后判定逻辑。前者判定适合是否该回答,是否该拒答,后者判定是否对自己回答有置信。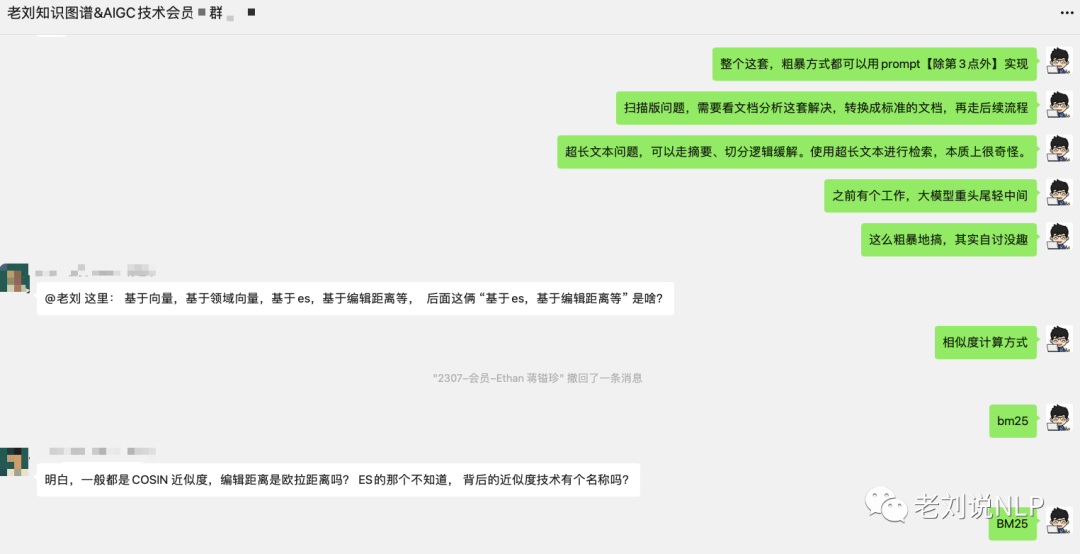
整个这套,粗暴方式都可以用prompt【除第3点外】实现。扫描版问题,需要看文档分析这套解决,转换成标准的文档,再走后续流程。超长文本问题,可以走摘要、切分逻辑缓解。使用超长文本进行检索,本质上很奇怪。
也就说,向量库只是个数据库,并不能优化什么决定性的东西【除了检索速度】。重心要放在,1)对相关性内容的召回上,把不对的踢掉【分类,拒答】,把对的提高(加权,投票)2)不受控生成的缓解【听懂指令,不跳出给定上下文,这靠SFT】。
 LLM这里其实你就利用了他擅长的内容撰写能力,让回答变漂亮而已?漂亮是一个结果,但方式多样,比如结构化更好,生成更好,摘要更好,看任务。做研发,一定要分清楚上下游关系,以及实现逻辑。
LLM这里其实你就利用了他擅长的内容撰写能力,让回答变漂亮而已?漂亮是一个结果,但方式多样,比如结构化更好,生成更好,摘要更好,看任务。做研发,一定要分清楚上下游关系,以及实现逻辑。
实际上,这一波Agent热潮的爆发,其实是LLM热情的余波,大家太希望挖掘LLM的潜力,为此希望LLM担任各方面的判断。但实际上,有一些简单模块,是不需要LLM的,不经济也不高效。所以,3月–6月,大家想着去合,7月份后,大家想着去拆,一合一拆,颇有玩味。
二、再看llama2进行中文汉化的必要性、路线及其实现案例
事实上,关于这个话题已经讨论对比,尤其是llama是否需要进行分词是否必要,不同的文章有不同的观点,但由于并没有做相关的实验,所以也无法真正地给出明确的意见。
所以,我们还是援引一些文章的观点来谈谈看。
文章《https://wqw547243068.github.io/chatgpt_mimic#llama-2》对该话题进行了论述,其认为:
首先,LLaMA原生仅支持Latin或Cyrillic语系,对于中文支持不是特别理想。原版LLaMA模型的词表大小是32K,而多语言模型(如:XLM-R、Bloom)的词表大小约为250K。 以中文为例,LLaMA词表中的中文token比较少(只有几百个)。这将导致了两个问题:LLaMA原生tokenizer词表中仅包含少量中文字符,在对中文字进行tokenzation时,一个中文汉字往往被切分成多个token(2-3个Token才能组合成一个汉字),显著降低编解码的效率。预训练中没有出现过或者出现得很少的语言学习得不充分。
其次,LLaMA需不需要扩充词表?如果不扩充词表,中文效果会不会比较差?Vicuna官方的报告,经过InstructionTuring的Vicuna-13B已经有非常好的中文能力。根据Chinese-LLaMA-Alpaca和BELLE报告,扩充中文词表可以提升中文编解码效率以及模型性能。但是扩词表相当于从头初始化训练这些参数。如果想达到比较好的性能,需要比较大的算力和数据量。同时,Chinese-LLaMA-Alpaca也指出在进行第一阶段预训练(冻结transformer参数,仅训练embedding,在尽量不干扰原模型的情况下适配新增的中文词向量)时,模型收敛速度较慢。
那么,目前都有哪些基于llama2的汉化模型,其实现路线如何?
首先我们来看实现路线:
第一种是基于已有的中文指令数据集,对预训练模型进行指令微调,使得基座模型能够对齐中文问答能力。这种路线的优势在于成本较低,指令微调数据量小,需要的算力资源少,能够快速实现一个中文Llama的雏形。 但缺点也显而易见,微调只能激发基座模型已有的中文能力,但由于Llama2的中文训练数据本身较少,所以能够激发的能力也有限,治标不治本,从根本上增强Llama2模型的中文能力还是需要从预训练做起。
第二种是基于大规模中文语料进行预训练。这种路线的缺点在于成本高,不仅需要大规模高质量的中文数据,也需要大规模的算力资源。但是优点也显而易见,就是能从模型底层优化中文能力,真正达到治本的效果,从内核为大模型注入强大的中文能力。
下面来看几个代表性的模型
1、openbuddy-llama2-13b
该模型基于Tii的Falcon模型和Facebook的LLaMA模型构建,OpenBuddy经过微调,包括扩展词汇表、增加常见字符和增强token嵌入。
通过利用这些改进和多轮对话数据集,OpenBuddy可回答各种语言的问题并执行翻译任务。
该模型多语言会话AI,支持中文、英语、日语、韩语、法语、德语等多种语言,扩展的词汇表和对常见的CJK字符的支持,通过多轮对话数据集进行微调以提高性能,提供多种模型版本:7B、13B、30B,通过llama.cpp提供对CPU部署的5位量化。
地址:https://huggingface.co/OpenBuddy/openbuddy-llama2-13b-v8.1-fp16
github地址:https://github.com/OpenBuddy/OpenBuddy/blob/main/README.zh.md
2、Llama2-Chinese-13b/7b-Chat
该模型基于中文指令数据集对Llama2-Chat模型进行了微调,使得Llama2模型有着更强的中文对话能力,包含7B和13B两个版本。
地址:https://huggingface.co/FlagAlpha/Llama2-Chinese-13b-Chat
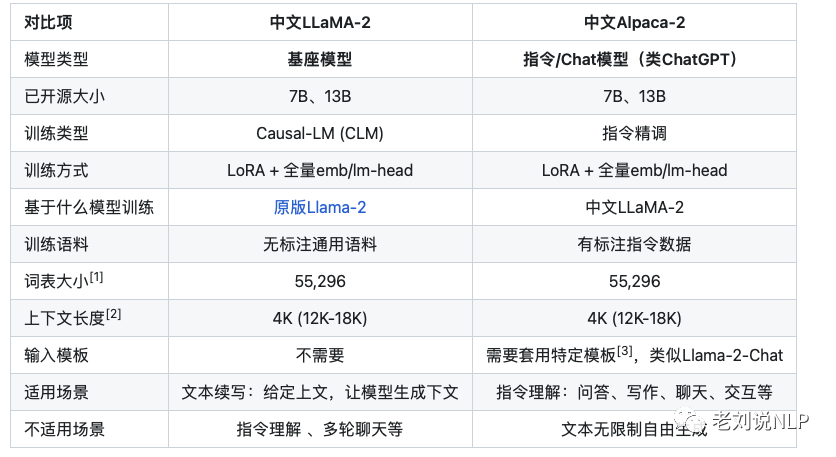
3、chinese-alpaca-2-7b
该模型在原版Llama-2的基础上扩充并优化了中文词表,使用了大规模中文数据进行增量预训练,进一步提升了中文基础语义和指令理解能力。相关模型支持FlashAttention-2训练,支持4K上下文并可通过NTK方法最高扩展至18K+。
在词表方面,重新设计了新词表(大小:55296),进一步提升了中文字词的覆盖程度,同时统一了LLaMA/Alpaca的词表,避免了因混用词表带来的问题,以期进一步提升模型对中文文本的编解码效率。
https://huggingface.co/ziqingyang/chinese-alpaca-2-7b
4、yayi-13b-llama2
雅意大模型在百万级人工构造的高质量领域数据上进行指令微调得到,训练数据覆盖媒体宣传、舆情分析、公共安全、金融风控、城市治理等五大领域,上百种自然语言指令任务。
在具体实现上,分别使用BigScience bloomz-7b1-mt以及Meta Llama 2 系列的模型权重作为初始化权重,并进行词表扩展;
地址:https://huggingface.co/wenge-research/yayi-13b-llama2
总结
参考文献
1、https://blog.abacus.ai/blog/2023/08/10/create-your-custom-chatgpt-pick-the-best-llm-that-works-for-you
2、https://wqw547243068.github.io/chatgpt_mimic#llama-2
3、https://huggingface.co/wenge-research/yayi-13b-llama2
4、https://whjlnspmd6.feishu.cn/wiki/DBnWwik1piTB6Iki02CcXoVQn3S
关于我们
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
老刘说NLP,将定期发布语言资源、工程实践、技术总结等内容,欢迎关注。
对于想加入更优质的知识图谱、事件图谱、大模型AIGC实践、相关分享的,可关注公众号,在后台菜单栏中点击会员社区->会员入群加入。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢