
点关注,不迷路,用心整理每一篇算法干货~
今天介绍的这篇文章来自百度自动驾驶技术团队,研究了如何进行Vision Transformer的稀疏化来提升运行效率,实现了50%吞吐量的提升,而效果只下降了0.2%。下面给大家详细介绍这篇工作。

论文标题:Adaptive Sparse ViT: Towards Learnable Adaptive Token Pruning by Fully Exploiting Self-Attention
下载地址:https://arxiv.org/pdf/2209.13802.pdf
Vision Transformer在CV领域逐渐占据核心地位,但是其运行效率一直是一个问题。Vision Transformer利用Transformer建模图像各个patch组成的序列,运算效率随着patch数量指数增长,相比CNN计算复杂度显著提升。如何进行ViT效率和效果的平衡是一个问题。
为了解决这个问题,业内的一个研究方向是ViT的token pruning,即将一些对于预测任务没有帮助的patch直接mask掉。例如对于分类任务来说,背景信息一般不是特别重要,因此可以将背景对应的token或patch直接mask掉。通过这种方式,需要计算attention的patch数量大幅减少,且被裁剪掉的patch对于最终预测帮助不大,因此可以实现ViT的模型压缩。
实现token pruning,其中的核心问题包括两个方面,一方面是如何计算每个patch对于最终任务的重要度,另一方面是以什么样的规则过滤掉某些patch。
为了衡量每个patch对于任务的重要性,文中主要利用了attention打分的信息。在ViT中采用了多头注意力机制,不同的head产出的attention打分分布含义不同,例如下图中,部分head更关注前景,部分head更关注背景,直接使用简单的加和方式无法衡量每个patch在不同head中注意力打分的分布差异。

文中借鉴了Soft filter pruning for accelerating deep convolutional neural networks(2018)中的CNN的裁剪方法,利用一个特征图的l2-norm度量其重要性,l2-norm越低,它经过激活函数后的值越小,对最终预测的影响越小,也就越不重要。通过这种方式,可以筛选出各个head产出的attention计算结果对最终的影响,以此为基础对各个head的attention map加权融合,得到每个patch最终的重要度。
利用这种方式,上述例子中某些head的attention map背景部分虽然突出,但是其对应的feature map对最终影响较小,因此会得到一个更低的权重,利用这种方式可以得到更准确的patch重要度信息。
在得到每个patch的重要度后,下一步是对不重要的patch进行裁剪,这就需要一个阈值衡量小于什么样阈值的重要度才是不重要的。之前的工作大多是人工定义一个阈值,而本文将阈值放到了模型的学习中,使用一个可学习的阈值替代固定阈值。整体的模型结构如下图所示。
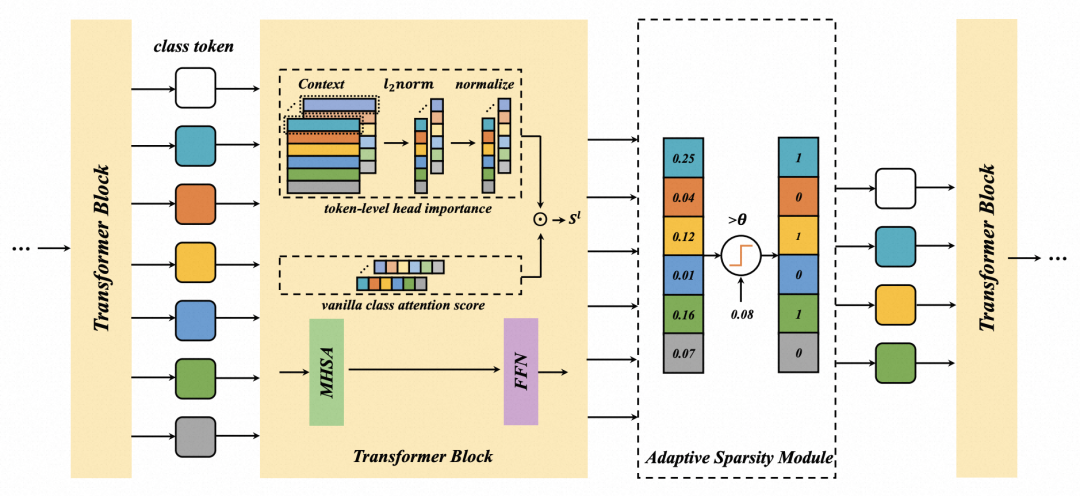
为了让阈值得到训练,整体模型可导,文中将hard mask替换成了soft mask。在hard mask中,直接判断高于阈值的保留,低于阈值的mask为0。而soft mask中,使用一个sigmoid函数生成0-1之间的patch是否mask的系数,如下公式,其中T是温度稀疏,theta是可学习的阈值,S是每个patch的重要度:
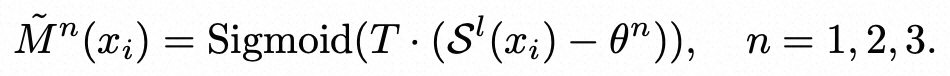
模型优化目标包括3个部分。第一部分是正常的分类任务的交叉熵损失函数。
第二部分是预算约束下的计算量。为了自动化的衡量ViT的稀疏程度,而不是完全依赖人工定义,文中将稀疏化后整个模型的FLOPs也引入了优化目标:
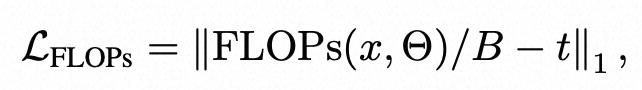
第三部分是蒸馏损失,将一个完整不稀疏化的模型的打分结果作为teacher,指导稀疏ViT模型的学习。最终的loss由这3部分loss加权得到。
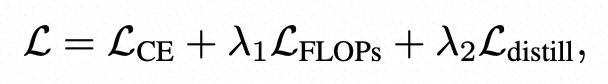
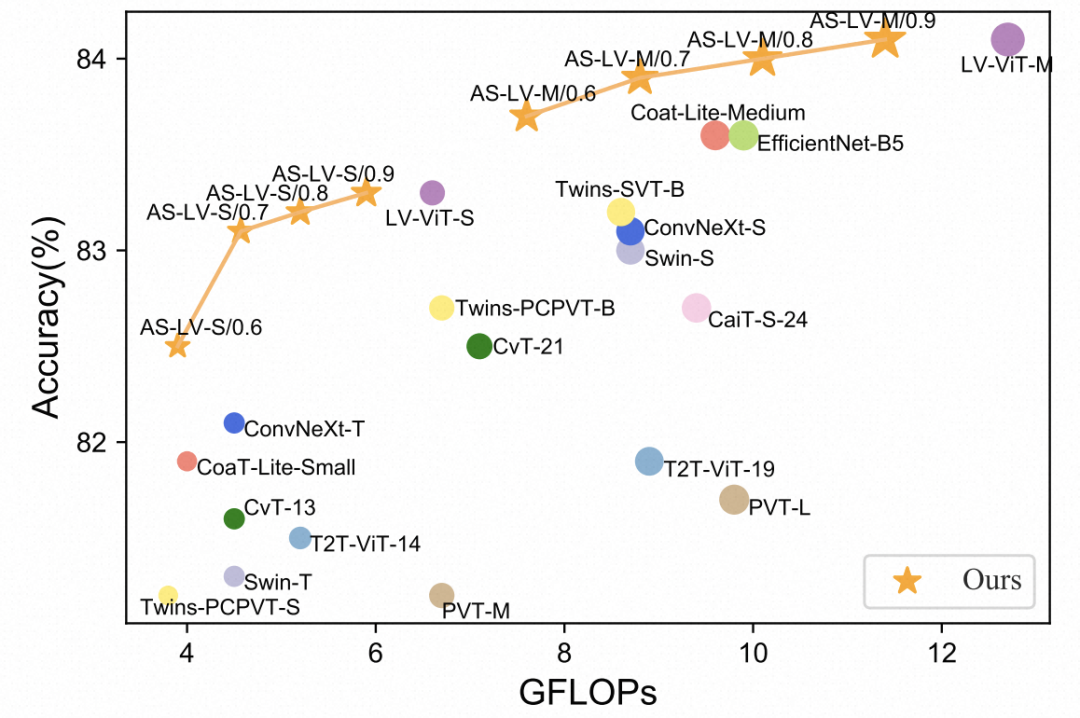
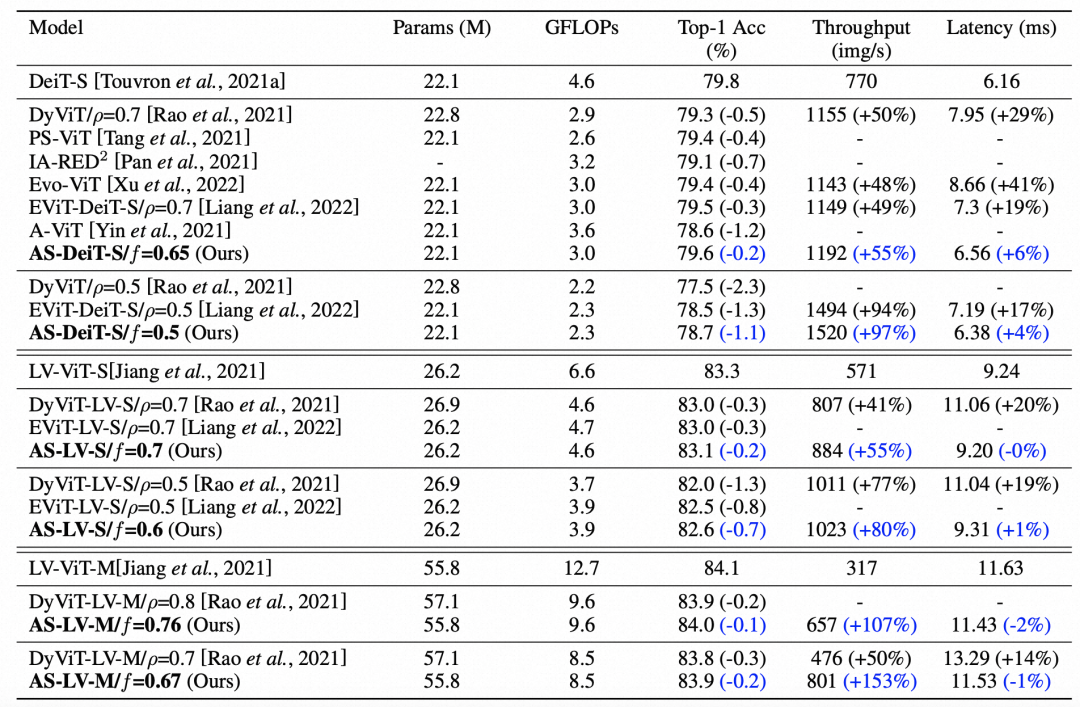
下图展现了这种根据算力约束动态设定稀疏化程度的效果,与之前固定稀疏程度的对比:

文中主要对DeiT-S进行了压缩,对比了之前token pruning方法,本文提出的方法取得了显著的效果提升。



也欢迎添加我的私人微信进行交流&投稿,加入圆圆算法交流群~

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢