

01
研究动机
本文关注信息抽取领域的一个新兴问题——多模态实体链接。实体链接(EL)是自然语言处理中的一个研究任务,它的目标是将非结构化文本中提到的命名实体(提及,mention)与结构化的知识库或知识图谱中对应的实体(entity)链接起来。例如,如图1所示,左侧句子中的“Super G”就是提及,而右侧则给出了知识库中的多个候选实体描述,任务目标即从中选出与提及匹配的实体。
实体链接最大的挑战在于提及的歧义性,即一个词或短语在不同的情境下可能表达不同的含义。传统的实体链接往往借助文本上下文来理解提及的含义,而多模态实体链接(MEL)则可以利用图像、视频或音频等模态辅助链接过程。通常,在传统实体链接给出的提及和其文本上下文的基础之上,多模态实体链接任务会额外给出一个与提及相关的图像。同时,知识库也额外包含了实体的图片。例如,如图1所示,提及“Super G”可以被解释为多种实体,如滑雪、WLAN 协议或食品市场,显然仅仅使用文本模态很难找到正确的实体。但是,如果将图像考虑在内,可以很容易理解“Super G”与滑雪有关。这样,消除歧义就更为简单。
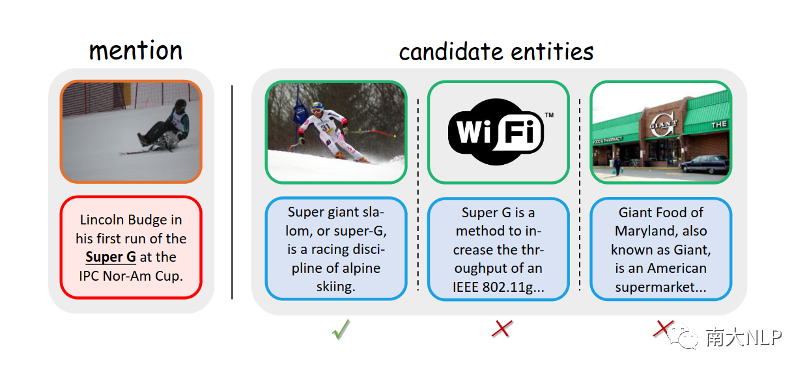 图1 多模态实体链接(MEL)任务
图1 多模态实体链接(MEL)任务
到目前为止,大多数现有的方法将 MEL 分为两个阶段:候选检索和实体消歧。在第一阶段,它们粗略地检索出与提及最相似的 Top-K 个候选实体;在第二阶段,它们使用多模态信息从之前构建的候选集中预测正确的实体。由于第二阶段更具有挑战性,现有研究大多关注第二阶段,本项研究也是如此。
目前,第二阶段的方法都采用了一个通用的框架:他们首先对提及的文本信息和图像信息进行交互和融合,得到提及的表示,然后用类似的方式计算实体表示。最后,他们计算提及表示和实体表示之间的相似度来做出预测。
现有的研究在编码提及和实体表示并计算相似度时,都隐式地建模了输入样本中 < 文本, 图片 > 和候选实体集中 < 实体, 图片 > 之间的对齐关系[1-4]。实际上,这些对齐关系一共包括四种:提及文本和实体文本的对齐关系,提及文本和实体图片的对齐关系,提及图片和实体文本的对齐关系,提及图片和实体图片的对齐关系。这带来了两个潜在的缺点:
首先,模型难以对提及和实体之间的细粒度关系进行建模。由于文本和图像的特征在匹配之前就被融合了,一些细粒度的特征被混合和削弱了,因此它们不能够在提及和实体之间进行对齐。例如,如图2(a)所示,之前的隐式对齐方法将提及图像中的“船”与提及文本特征融合,融合后的特征无法与实体图像中的船进行对齐。然而,如果两个图像被显式地关联起来,就很容易发现“图像中的主要视觉对象都是船”的事实。这一线索对于MEL任务是至关重要的,因为它表明提及和实体指代同一对象。因此,一个有效的模型需要显式地对提及和实体之间的对齐关系进行建模。
 图2 数据集中的两个样例
图2 数据集中的两个样例
其次,现有方法的对齐是静态的,这导致在处理复杂和多样化的数据时性能较低,因为不同的样本通常依赖于不同类型的对齐。例如,有些样本依赖于文本-文本对齐,而有些样本主要依赖于图片-图片对齐。如图2(a)所示,文本中包含的有用信息很少,这个样本主要依赖于图像之间的对齐关系,即发现视觉对象都是船。相反,在图2(b)中,图像中没有足够的信息来表明New Zealand是一个国家(而不是一个运动队);只有通过关注文本中的prime minster,才能将其与国家联系起来。因此,一个有效的模型应该能够根据不同的输入样本自适应地选择相应的对齐方式。
为了解决上述问题,本文提出了动态关系交互网络(DRIN)。针对第一个问题,本文显式地对四种不同类型的对齐关系进行建模,使DRIN能够学习提及和实体之间的细粒度对齐关系。针对第二个问题,本文构建了一个动态的GCN,提高了模型处理多样化数据的能力。具体来说,将提及中的文本和图像以及所有候选实体中的文本和图像视为顶点,将四种不同类型的对齐关系视为边,通过迭代地更新顶点特征和边权重,模型可以动态地为不同的输入样本选择相应的对齐关系。在两个数据集上的实验表明,DRIN大幅度超越了现有的最先进方法,证明了该方法的有效性。
02
本文贡献
针对多模态实体链接任务,本文首次采用动态显式对齐方法,这一方法提高了处理多样化和复杂数据的性能;
本文提出了一种新颖的动态关系交互框架,该框架在GCN上动态更新特征和对齐关系,从而得到更准确和稳健的表示;
在两个公开数据集上的实验证明了本文提出的DRIN模型优于目前最先进的方法,进一步的分析验证了该模型的有效性。
03
解决方案
整体模型架构如图3所示,主要由图构建、关系交互、匹配三个模块组成。
 图3 DRIN框架示意图
图3 DRIN框架示意图
(一) 图构建
我们首先提取文本和视觉特征来初始化顶点,包括提及文本、提及图像、实体文本和实体图像。我们使用BERT编码器来获取文本上下文特征,使用ResNet编码器提取图片特征。这些特征向量将作为图顶点的初始化。
同时,为了利用提及和实体之间的细粒度对齐,本文显式地建模了四种类型的对齐关系:提及文本和实体文本、提及文本和实体图像、提及图像和实体文本、提及图像和实体图像,使用这些关系来构建 GCN 中相应的边。具体地,我们计算这些边对应顶点的相似度,将其作为边的初始化权重。
(二) 关系交互
关系交互旨在利用邻近顶点的信息来增强顶点的多模态表示。本文基于动态 GCN 构建了关系交互模块,在迭代更新顶点特征时,同时也更新边的权重,使模型能够自适应地选择合适的细粒度对齐关系。
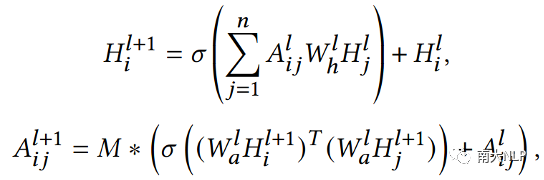
(三) 匹配
最后,从图中提取提及和其实体的文本顶点特征向量(它们现在已经融合了多模态上下文),并计算它们的余弦相似度。相似度最大的实体将被预测为链接实体。
我们使用排序损失作为损失函数。训练的目标是最大化提及和其正确实体之间的相似度,同时最小化和其他实体的相似度。形式上,
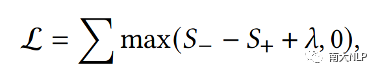
其中lambda是边际值,S+是提及和其正确实体之间的相似度,S-是提及与一个mini-batch中除了正确实体之外的其它所有实体的平均相似度。
04
实验
我们在两个MEL数据集上WikiMEL和WikiDiverse进行了实验。这两个数据集包含数万个MEL样本,内容主要包含了新闻事件和社交媒体。我们将DRIN和前人提出的模型进行了比较,实验结果如下:
表1 主实验结果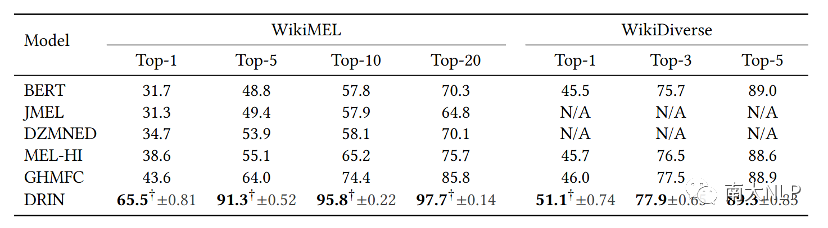
可以看到,本文提出的DRIN模型在两个数据集上都显著优于之前的方法。具体来说,关于Top-1分数,DRIN在WikiMEL和WikiDiverse数据集上分别比之前最先进的GHMFC模型提高了22.4%和5.1%。模型在其他指标上也取得了很好的结果。这些结果揭示了该模型的有效性。
为了研究模型中不同模块的贡献,本文对DRIN的两个主要组成部分进行了消融实验。我们分别去除了DRIN中不同的边,以及将动态更新的机制删除,然后保持其他条件不变重复实验。其结果如下:
表2 消融实验结果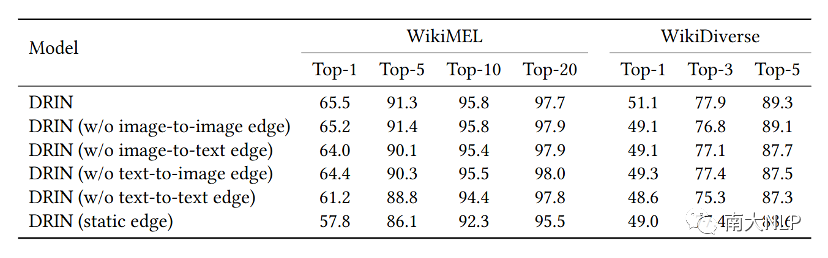
可以发现,大体上,移除一种边会使整体性能变差,这验证了利用提及和实体的<文本,图像>对之间的四种对齐关系的合理性。此外,将动态边替换为静态边也会导致性能下降,这意味着动态关系交互比静态对齐具有优势,这和本文使用动态GCN来建模多样化对齐方式的动机相符合。
此外,我们观察到,移除边后WikiMEL的Top-20指标略微上升。这可能是因为Top-20指标中,排名实体存在更大的噪声。与前1、前5和前10相比,前20中排名较低的实体相关性较低,更有可能是噪声。在这种情况下,移除边有利于阻止噪声传播。
05
总结
在本文中,我们提出了一种新颖的动态关系交互网络(DRIN),用于多模态实体链接(MEL)任务。我们方法的主要思想是显式、动态地建模提及和实体之间四种细粒度对齐关系,以增强它们的表示能力。在两个MEL数据集上的实验结果验证了我们方法的有效性。
参考文献
[1] Jngru Gan, Jinchang Luo, Haiwei Wang, Shuhui Wang, Wei He, and Qingming Huang. 2021. Multimodal Entity Linking: A New Dataset and A Baseline. In MM ’21: ACM Multimedia Conference, Virtual Event, China, October 20 - 24, 2021, Heng Tao Shen, Yueting Zhuang, John R. Smith, Yang Yang, Pablo César, Florian Metze, and Balakrishnan Prabhakaran (Eds.). ACM, 993–1001. https://doi.org/10.1145/3474085.3475400
[2] Peng Wang, Jiangheng Wu, and Xiaohang Chen. 2022. Multimodal Entity Linking with Gated Hierarchical Fusion and Contrastive Training. In SIGIR ’22: The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, July 11 - 15, 2022, Enrique Amigó, Pablo Castells, Julio
Gonzalo, Ben Carterette, J. Shane Culpepper, and Gabriella Kazai (Eds.). ACM, 938–948. https://doi.org/10.1145/3477495.3531867
[3] Xuwu Wang, Junfeng Tian, Min Gui, Zhixu Li, Rui Wang, Ming Yan, Lihan Chen, and Yanghua Xiao. 2022. WikiDiverse: A Multimodal Entity Linking Dataset with Diversified Contextual Topics and Entity Types. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long
Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, Smaranda Muresan, Preslav Nakov, and Aline illavicencio (Eds.). Association for Computational Linguistics, 4785–4797. https://doi.org/10.18653/v1/2022.acl-long.328
[4] Li Zhang, Zhixu Li, and Qiang Yang. 2021. Attention-Based Multimodal Entity Linking with High-Quality Images. In Database Systems for Advanced Applications - 26th International Conference, DASFAA 2021, Taipei, Taiwan, April 11-14, 2021, Proceedings, Part II (Lecture Notes in Computer Science, Vol. 12682), Christian S. Jensen, Ee-Peng Lim, De-Nian Yang, Wang-Chien Lee, Vincent S. Tseng, Vana Kalogeraki, Jen-Wei Huang, and Chih-Ya Shen (Eds.). Springer, 533–548. https://doi.org/10.1007/978-3-030-73197-7_35
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢