

封面图链接: https://www.pexels.com/photo/delivery-robots-parked-beside-glass-window-8566566/
论文解读:李欣 马玺渊
作者:Gah-Yi Ban, Cynthia Rudin
引用:Ban, Gah-Yi and Cynthia Rudin. The big data newsvendor: Practical insights from machine learning. Operations Research 67.1 (2019): 90-108.
文章链接:https://doi.org/10.1287/opre.2018.1757
问题与方法简述
文章研究了大规模数据驱动的报童问题(包括个关于需求的特征和个观测值),并围绕以下四个问题展开讨论:
问题一:决策者应如何使用特征需求数据集来解决报童问题?
问题二:在报童模型决策中纳入特性的价值是什么?
问题三:使用这些数据的决策者有什么理论保证最优性?以及这些保证如何与各种问题的不同参数进行变化?
问题四:在实践中,基于特征需求数据集的报童决策与其他基准方法相比如何?
此处的“特征”指的是指外生变量(也称为协变量、属性和解释变量),它们是需求的预测因子,在需求发生之前可供决策者使用。

问题一:决策者应如何使用特征需求数据集来解决报童问题?
文章提出了两类一步式方法,基于给定的需求与相关特征数据的观测值,确定基于最优订货数量。
其一基于经验风险最小化方法 (Empirical Risk Minimization, ERM) (详见 Vapnik, 1998), 适用于实施或不实施正则化两种情况。文章表示,ERM相当于高维分位回归(一种用于估计因变量和自变量关系的方法,特别适用于高维度的数据集):当不涉及正则化时,ERM方法可以看作是一种线性规划算法。当涉及正则化时,根据所使用的正则化类型(正则化),ERM方法可以被转化为混合整数规划、线性规划,或二阶锥规划 (Second Order Cone Programming, SOCP). 其二为核权重优化 (Kernel-weights Optimization, KO),可参见 Nadaraya-Watson 核回归方法 (Nadaraya-Watson kernel regression method: Nadaraya, 1964; Watson, 1964) . 该方法下的最优数据驱动订货量可由简单的排序算法求得。
问题二:在报童模型决策中纳入特性的价值是什么?
文章通过回答问题二来证明使用特征的合理性,其中通过与没有任何特征的决策进行比较(样本平均近似,Sample Average Approximation, SAA)来分析量化特征的价值。文章考虑两种需求模型(双人口模型和线性需求模型)的比较,并表明:无特征 SAA 决策不会收敛到真正的最优决策,而基于特征的 ERM 决策则会收敛;换句话说,无论决策者有多少个观测值,SAA 决策都有恒定偏差(即 误差),而当趋于无穷大时,基于特征的决策的任何有限样本偏差都会缩小到零 。因此,SAA 决策可能比 ERM 决策具有更高的报童成本。
问题三:使用这些数据的决策者有什么最优性保证?以及这些保证如何与各种问题的不同参数进行变化?
在实践中,由于数据有限,决策者可能永远无法做出真正最优的决策。为了解没有完整需求分布信息的情况下的权衡,文章推导了所提出算法的理论性能界限,其包括样本内决策成本(与样本内决策的期望成本相对)与问题的各种参数,特别是和的真实预期成本之间的偏差。这些界限显示了样本内决策的样本外成本(“泛化误差”)如何通过一个复杂度项来偏离其样本内成本。从实际角度来看,这些界限明确表现了泛化误差(衡量样本内过拟合程度)和有限样本偏差之间的权衡,以及它们如何依赖于数据集的大小、报童成本参数和算法中的任何自由参数(控制变量)。

问题四:在实践中,基于特征需求数据集的报童决策与其他基准方法相比如何?
文章通过建立于医院急诊室的护士排班问题进行了实证研究且评估了所提出的两类算法。
对于ERM算法,最优结果通过进行 正则化获得,其相对于最佳实践基准(按周中的某天聚类的样本平均近似值),成本降低了 23%. 相对于相同的基准,使用 KO 方法的最佳结果是成本降低了 24%。两项结果均在 5% 水平上具有统计显著性。 计算效率方面,通过排序过程求解的最佳 KO 方法效率极高,其只需 0.05 秒即可计算出下一个时期的最佳人员配置水平,这比最佳 ERM 方法快三个数量级,比最佳实践基准和其他基准快两个数量级。
基于特征的报童模型 (问题一)
传统的报童问题是一家公司销售易腐商品,在观察到不确定的需求之前需要下订单,目标是确定订购数量,使总预期成本最小化,即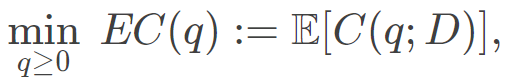
其中是订购量,是不确定(随机)的未来需求,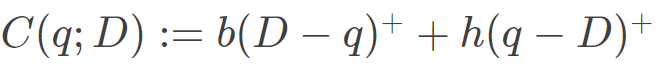
为订单 和需求 的随机成本,和 分别是单位缺货成本和单位持有成本。若需求分布 是已知的,则可以示出由分位数给出最优决策,即: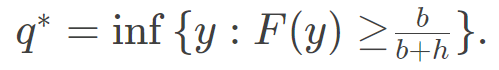
数据驱动报童模型考虑到实际中去决策者并不清楚真实需求分布的情况。若仅可以访问历史需求观测,则可用样本平均期望值代替真实期望值,即
其中 表示根据数据估计的订购量,其最优SAA决策为
其中是来自个观测需求的经验累积分布函数。
基于特征的报童模型 在实践中,需求取决于许多可观察到的特征,例如季节性、天气、位置和经济指标,其皆可在下订单前已知并用于订单决策中。于是,实际报童问题为最优条件期望成本函数(此处定义为问题1):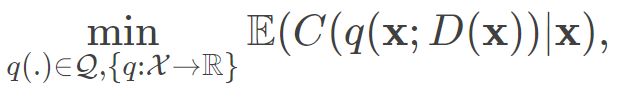
其中是高维特征,需求是特征向量的函数。此时的决策则为一个将特征空间映射到实数空间的函数,而要最小化的期望成本则以特征向量为条件。
基于特征的报童模型的求解算法(问题一)
ERM 算法
假设决策者已经收集了适当的历史数据,每个特征均是 维的。解决基于特征的报童模型的ERM算法可描述为 (NV-ERM)
其中为函数相对于数据集的经验风险。假设可由某些参数表示,文章考虑以下线性决策形式:
以经验风险作为优化目标,当相对小时,目标函数可表示为 (NV-ERM1)
相反,当相对大时(),加入正则项为 (NV-ERM2):
其中为正则系数,表示向量的范数。若以为正则范数,则问题转化为二阶锥规划。若可预测需求很小,则可以使用半范数或 范数 来增大系数向量的稀疏性,进而问题转化为MILP 或 LP。NV-ERM1 和 NV-ERM2 的完整模型可参考原文或下图。


KO 算法
给定历史数据,Nadaraya and Watson 提出局部加权平均来估计:
其中是具有带宽的核函数。现对于订购量, 在观察特征之后的特征相关报童期望成本可表示为; 因此,如果将报童成本视为因变量,可以通过 Nadaraya-Watson 方法进行估计,即
文章将以上针对特征数据驱动的报童模型的方法称为核优化 (NV-KO), 即
为一维分段线性优化问题,其最优报童模型决策为
其中
截止文章发表为止,在库存决策中纳入外源信息的算法还包括:Liyanage and Shanthikumar (2005) 的操作统计 (Operational Statistics, OS)、See and Sim(2010)通过考虑线性决策规则以及分段线性决策规则来解决鲁棒问题、Hannal et al. (2010) 的周期随机优化问题。在原文的实例研究中,文章考虑了使用操作统计学启发式特征,结合NV-ERM1 和2, 在有无特征的情况下进行求解并进行比较。
特征信息的价值(问题二)
文章通过将 NV-ERM1 决策与仅根据过去的需求数据做出的 SAA 决策进行比较,量化在报童决策中纳入特征的价值。考虑两种需求模型,两群体需求模型和线性需求模型:在这两种情况下,文章通过理论证明(原文引理1和引理2, 定理1,2,3),SAA决策产生不一致的决策,而基于特征的判定是一致的;进一步量化对预期成本的影响,对于远离真正最优的决策来说,预期成本必然更大。简述如下:
两群体需求模型
NV-ERM1 最优订货量为
即 用于解决 对应的数据子样本SAA问题,而用于解决解决 对应的数据子样本SAA问题。
NV-ERM1的有限样本偏差和渐近最优性:基于特征的决策的有限样本决策的偏差最多为:
基于特征的决策是渐近最优的,随着观测值数量趋于无穷大,其可以正确识别 或的具体情况。
SAA 最优订货量为
SAA 的有限样本偏差和渐近(sub)最优性:平均而言,如果在下一个决策周期内,则SAA决策命令过多,如果,则SAA决策命令过少。并且 SAA 决策不是渐近最优的(不一致),也就是说,即使有无限量的需求数据,无特征的 SAA 决策也会收敛到与真实最优值不同的数量。
线性需求模型 与特征向量 独立。
SAA与DM2的订购量 , 分别为
其中是的经验分布,且 是NV-ERM1解的系数。
没有特征会导致不一致的决策
SAA决策收敛于离散度加上总体时间平均需求的临界分位数,而DM2的决策收敛到正确的决策。由SAA的不一致性产生一个问题:就预期成本而言,远离真正最优的决策必然更差吗?换句话说,当特征信息的效果增加时,预期成本的损失是否会增加?
预期成本差值。 原文通过定理4证明,设表示基于特征和非最优解的报童模型最优解,则两个决策所产生的成本差值为
观察到预期成本差值随的期望在两个决策之间与的区间上变化。预期成本差异随着偏离而增加。差异的大小与该区间长度以及需求在该区间上的分布情况相关,分布越集中,差异就越大。
尽管上述结论证明了特征集合的合理性,但一个缺点是,决策者需要知道需求分布以量化次优样本内决策所带来的预期成本增益,但事实不尽如此。文章随后使用现有信息以高概率范围,来描述决策者的样本内决策的预期成本。
使用样本内信息的样本外成本界限(问题三)
文章对 NV-ERM1、NV-ERM2 和 NV-KO 选择的排序决策的样本外成本提供理论保证,目标是提供可利用现有数据计算的性能界限。我们看到性能界限分为两个部分:一个与有限数据量产生的偏差有关,通常称为有限样本偏差,另一个与样本内决策的方差有关,称为泛化误差。
术语“泛化”是指样本内决策对样本外数据的泛化能力,并且是过度拟合程度的度量,因为泛化误差较大的决策与较大的过度拟合相关。过度拟合的决策可能会产生误导;例如,如果样本内决策的选择有很大的自由度,那么样本内成本可能为零,导致决策者认为完美排序是可能的。然而,精明的决策者如果意识到过度拟合的危险,就会谨慎地仅根据样本内数据得出结论,而泛化误差为决策者的决策提供了过度拟合如何产生的描述。
定义“真实风险”为样本外风险,其中期望关于某未知分布, :
定义经验风险为训练样本的平均成本:
经验风险可以计算,而真实风险则不能;然而仅凭经验风险并不能完整地反映真实风险。基于三点假设(详见原文4.1)文章提供了关于真实风险的概率上界,其与经验风险和算法稳定性方法相关。定理5-7的假设见原文第4节。
NV-ERM1的样本外性能(原文定理5):样本内决策成本与真正最优决策的预期成本的差值绝对值
其中 , ,
右侧上界的第一项是泛化误差的界,泛化误差是样本内决策的训练误差和测试误差之间的差。对于固定成本参数 b 和 h,我们发现泛化误差为。因此,如果总体模型中的相关特征的数量很小,并且相对于观测值的数量不增长,则样本内决策可以很好地推广到样本外数据。换句话说,过拟合不应该是问题。关于进一步的细节,请参考附录C和Bousquet和Elisseeff(2002)中的证明。右侧上界的第二项是由于 的有限样本偏差。关于细节,请参考附录C中定理5的证明。
NV-ERM2的样本外性能(原文定理6):在上式基础上引入正则项
其中 , ,
第一项是泛化误差的界,其为。因此,过拟合的量可以通过施加在问题上的正则化的量来直接控制,λ越大,泛化误差越小。其中不等式右侧第二项其未出现在定理5中,是由于正则化引起的样本内决策的偏差。对于较大的 λ,该项较大,因此在泛化误差和正则化偏差之间存在折衷。第三项也是最后一项是有限样本偏差。虽然正则化偏差可以通过 λ 来控制,但有限样本偏差只能通过收集更多的数据来控制。
NV-KO 的样本外性能(原文定理7):
其中, 为核函数的带宽, , ,
关于 NV-KO 的性能界限具有三个分量:泛化误差的界限,当真实决策是函数时由于用数量决策优化而导致的偏差,以及有限样本偏差项。泛化误差为,因此可以通过增加核带宽 来降低 进行控制。然而,与NV-ERM 2一样,增加的 增加了第二项误差,因此在实践中 需要在合理的值范围内优化。有限样本偏差项与定理5-6中的相应项起着相同的作用。
实例研究:急诊室护士排班问题(问题四)
文章通过医院急诊室的护士配置问题,即医院在某一天应该安排多少个护士,应用这三种算法 (NV-ERM1, NV-ERM2, NV-KO),以找到最佳的医院急诊室护士的人员配置水平。由于发达国家的大多数医院都规定或建议最低护士与患者的比例,近似护士配备问题作为一个报童问题,护士人员配备问题是测试文章介绍的数据驱动模型的自然环境。
文章的数据来自2008年7月至2009年6月英国一家大型教学医院的急诊室。数据集包括以2小时间隔在急诊室中的患者总数。在图1中提供了按天和按时间段的患者数量的箱形图。数据显示病人的数量与时间有一定的相关性。详情请见原文第五节。
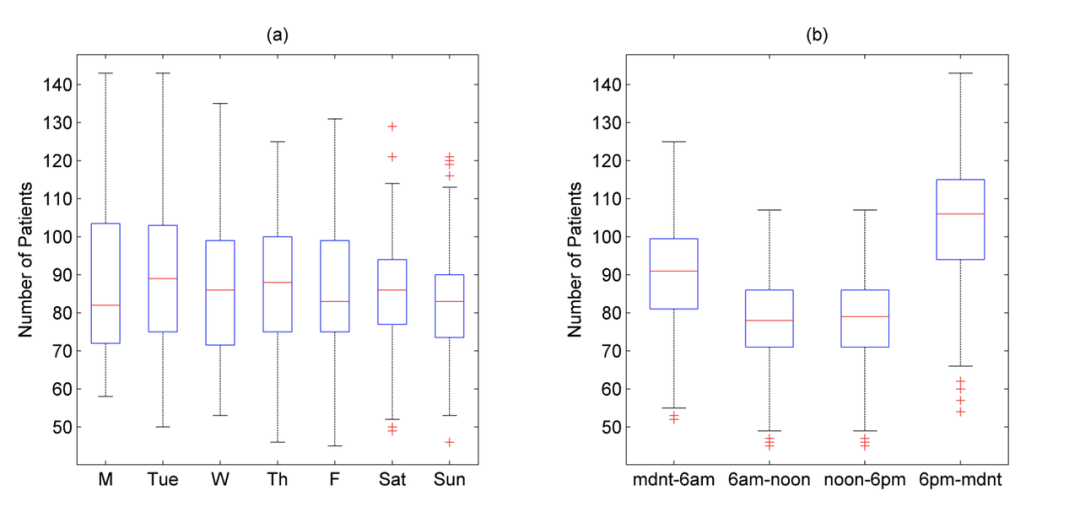
假设护士与病人的比例为,机构护士的小时工资是正规护士的2.5倍,, ,目标分位数为。考虑两组特征:
第一组是每周某天,每天某时,以及记录过去需求的天数;
第二组是第一组的样本加上过去需求的样本平均值和过去需求的顺序统计量的差(操作统计(OS)特征,详见 Liyanage and Shanthikumar, 2005).
文章使用个历史需求观察(16周)作为训练数据,并计算3个周期前的关键人员配备水平。然后,在 验证数据上记录预计人员配置水平的样本外报童成本。文章所考虑的16种不同方法及缩写如下表所示。
表1:方法汇总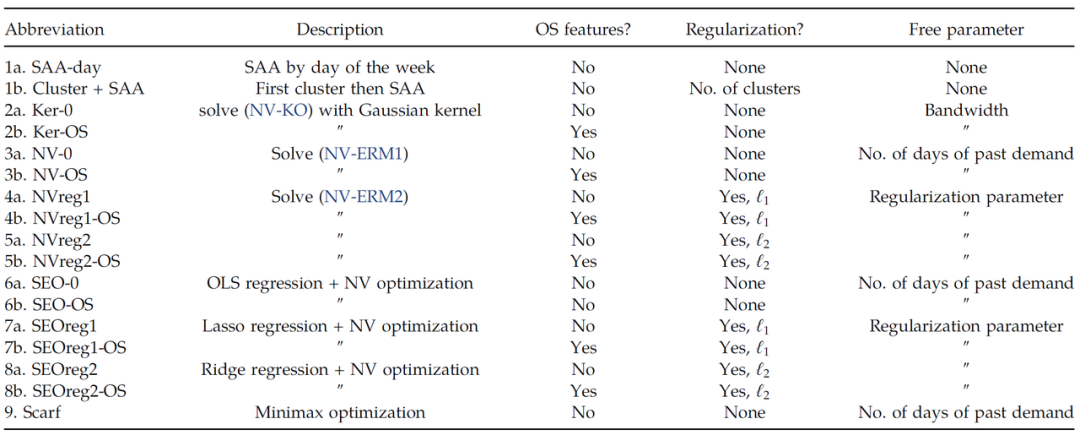
表2 汇总了文章所考虑的 16 种方法的样本外表现,其中包括校准参数 (calibrated parameter)、平均计算时间(秒)、均值、95% 置信区间(详见原文附录表 EC.1–EC.7),以及该方法的年度节省成本。
表2:结果汇总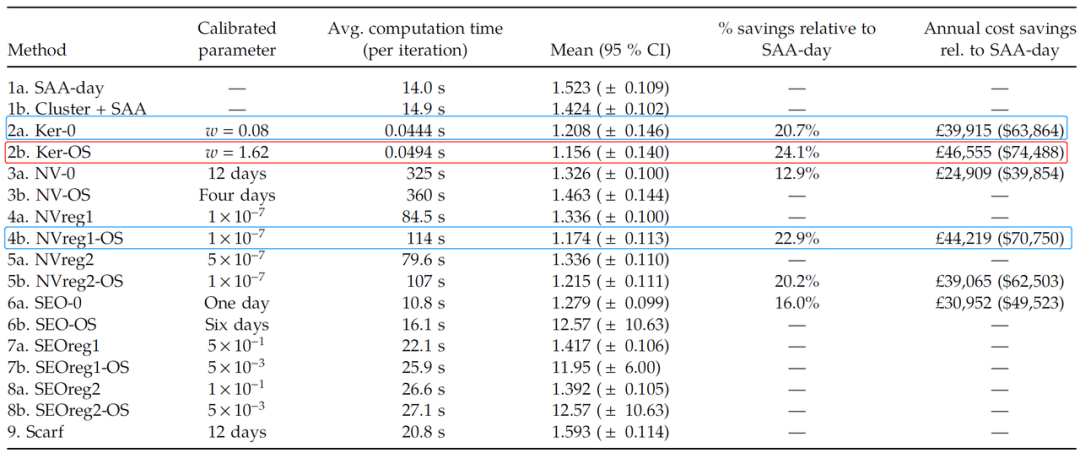
以上结果中,最佳结果通过采用带宽 的 KO 方法获得,其相对于最佳实践基准(“SAA 天”),成本改善了 24%(每年节省 46,555 英镑),具有5%的统计显著性在水平。次好结果是采用 正则化的 ERM 方法和不考虑 OS 特征的 KO 方法,其平均年成本分别降低了 23%(每年 44,219 英镑)和 21%(每年 39,915 英镑)。
然而,基于特征的方法的计算成本非常不同。KO 方法比基于 ERM 的方法快三个数量级。例如,使用具有 OS 特征的 KO 方法仅需 0.0494 秒即可找到下一个最佳人员配置水平,而采用正则化的 ERM 方法则需要 114 秒。
实践见解
没有单一的方法可以解决大数据报童问题。 文章提出了三种使用特征需求数据集的方法,并与使用或不使用特征来解决问题的许多其他潜在方法进行了比较。 这并不是说这些方法是详尽无遗的。 我们对开发新方法持乐观态度。 大数据驱动的决策者总是需要警惕过度拟合,因为决策在样本内表现良好,但在样本外则不然,因此,不仅会导致决策表现不佳,还会导致决策失败。 文章已经证明,过拟合可以通过先验特征选择或正则化来控制,这为决策者提供了额外的控制权,使决策有利于改进样本外泛化。 影响样本内决策真实性能的因素包括泛化误差(又名过度拟合误差)、正则化带来的偏差以及仅因数据量有限而产生的有限样本偏差。 决策者可以通过正则化参数控制正则化产生的泛化误差和偏差,在实践中,需要在单独的验证数据集上对一系列参数值进行优化。 除非收集更多数据,否则无法控制有限样本偏差。 尽管在文章的案例研究中,KO 方法在样本外性能方面优于所有其他方法,但对于不同的数据集,情况不一定如此。 我们认为,案例研究最重要的一点是展示如何进行仔细的数据驱动调查,而不是针对具体案例得出 KO 方法表现最佳的结论。 然而,我们注意到 KO 方法的相对速度是可以推广的。
参考文献
Bousquet, Olivier, André Elisseeff. 2002. Stability and generalization. The Journal of Machine Learning.
Liyanage LH, Shanthikumar JG (2005) A practical inventory control policy using operational statistics. Oper. Res. Lett. 33(4):341–348.
Nadaraya EA (1964) On estimating regression. Theory Probab. Appl. 9(1):141–142.
See C-T, Sim M (2010) Robust approximation to multiperiod inventory management. Oper. Res. 58(3):583–594.
Vapnik VN (1998) Statistical Learning Theory (Wiley, New York).
Watson GS (1964) Smooth regression analysis. Sankhya: Indian J. Statist. Ser. A. 26(4):359–372.
微信公众号后台回复
加群:加入全球华人OR|AI|DS社区硕博微信学术群
资料:免费获得大量运筹学相关学习资料
人才库:加入运筹精英人才库,获得独家职位推荐
电子书:免费获取平台小编独家创作的优化理论、运筹实践和数据科学电子书,持续更新中ing...
加入我们:加入「运筹OR帷幄」,参与内容创作平台运营
知识星球:加入「运筹OR帷幄」数据算法社区,免费参与每周「领读计划」、「行业inTalk」、「OR会客厅」等直播活动,与数百位签约大V进行在线交流

文章须知
论文解读:李欣 马玺渊
责任编辑:马玺渊
微信编辑:疑疑
文章由『运筹OR帷幄』原创发布
如需转载请在公众号后台获取转载须知


关注我们
FOLLOW US


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢