

以下文章来源于知乎:自动驾驶之心
作者:写代码的艾舍尔
链接:https://mp.weixin.qq.com/s/EYg3sAy2Ey9voHBtW2bUdw
本文仅用于学术分享,如有侵权,请联系后台作删文处理

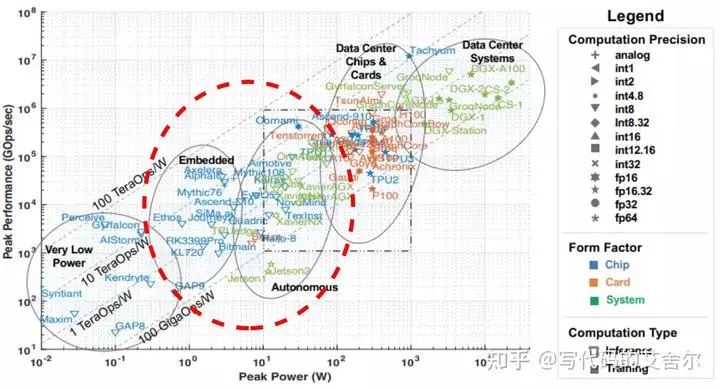
端侧典型transformer模型盘点
视觉主干篇
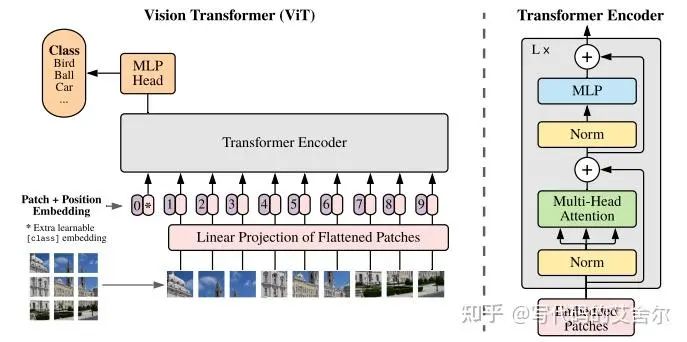
整体流程上:通过patch embedding将图像直接打包编码,转换成transformer类型的序列特征,接上patch position encoding后,后续由经典的transformer block全权接管。 算法角度上:Vit结构只通过少量特征前处理就把视觉信息转换为了序列特征,还是挺优雅简洁的。但由于尺度信息在patch embedding阶段就被patch_size唯一确定,致使对视觉任务至关重要的多尺度信息缺位。因此,在除分类之外的其他视觉任务中,Vit的表现并不理想。
优势:
Vit结构除了patch embedding与输出形式之外,与经典transformer结构并无二致,所以可直接享用抛开kv-cache的绝大多数transformer推理优化策略。 劣势:
计算量随分辨率二次增长(seqlen=(H/patch_size)x(W/patch_size))。当应用到大分辨率场景时(比如检测分割),无论是FFN还是MHA中的矩阵乘都无法直接载入资源受限的端侧近核缓存。虽然有各类并行切分策略支撑,但缓存与主存间的超额换入换出产生的带宽开销还是严重制约了它的计算效率。 patch_size级别(16/32)的特殊conv2d,也并不一并有很好的利用效率。当然重点还是1),2)的问题和CNN第一个inchannel=3的卷积很像,不是瓶颈,而且2)也可以转换为permute+gemm的形式规避。
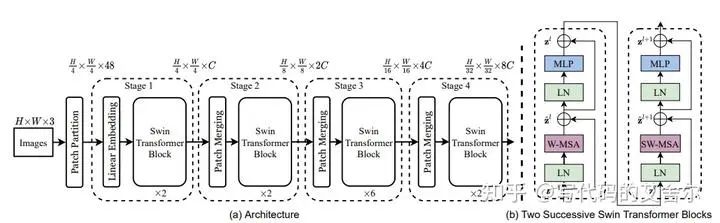
整体流程上:参考上图,PatchMerging逐Stage降尺度(第一个PatchPartition+LinearEmbedding可以看做特化的PatchMerging);单个SwinTransformer先通过WindowPartition将视觉特征转换为以局部窗口为粒度的序列特征,送入经典Transformer结构处理完毕后,再通过WindowUnpartition转回视觉特征;每俩SwinTransformer做一次窗口滑动,以实现全局的信息流通。 算法角度上:SwinTransformer这套魔改的WindowAttention还是肯定了视觉任务中的局部性特点。另外,在整个pipeline中视觉特征与序列特征的来回切换,使得基于注意力的多尺度信息提取成为可能。这对Transformer在检测、分割等视觉任务上的落地有重要意义。
优势
WindowAttention机制使得计算量随分辨率线性增长,解决了ViT的主要问题。此外,序列规模seqlen仅与窗口尺寸ws相关(seqlen=ws x ws),只要embed_dim设计的当,无论何种分辨率,都能将矩阵运算常驻于AI芯片的近核缓存。 该机制还变相地提升了Batch的大小(Batch=batch_origin x (H/ws) x (W/ws), ws指窗口大小)。并行无需同步,完全免费!!这对有多核的架构设计来说,绝对是意外之喜。 劣势
除了继承了ViT的PatchEmbedding的特殊卷积之外,WindowPartition/Unpartition和窗口滑动引入了permute/torch.roll,和windowsize与分辨率未匹配引入了Pad,这些高频的数据重排无疑对性能有较大的影响。
注意力机制上:窗口注意力(SwinTransformer)与全局注意力(ViT)的结合。比如ViTDet:Exploring Plain Vision Transformer Backbones for Object Detection, ECCV, 2022。就是部分Transformer使用WindowAttention,部分使用Attention。 位置编码上:将NLP领域的位置编码创新往视觉任务上套,比如RoPE: ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING, 2021。如下所示,核心计算上就是奇偶旋转偶去反,(x, y) --> (-y, x)。在onnx层级会被拆分为:低维split+neg+低维concat的子图。将一个明显的1pass转换为了multipass,对性能还是略有影响的。
def rotate_half(x):
x = rearrange(x, '... (d r) -> ... d r', r = 2)
x1, x2 = x.unbind(dim = -1)
x = torch.stack((-x2, x1), dim = -1)
return rearrange(x, '... d r -> ... (d r)')
视觉检测篇
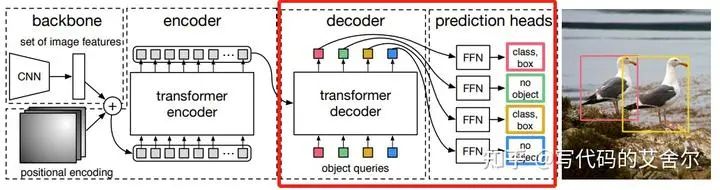
整体流程上:如上图。主干提特征,做一道ChannelMapping和位置编码后,送入经典的Transformer编解码模块,并最终交由FFN出框。值得说明的是,解码部分的query embedding是一个预设的固定值(学习参数)。 算法角度上:基于transformer的端到端框架,无NMS,无任何人工特征与先验知识,但训练困难。部署视角下,简直是惊为天人的设计。
优势
端到端没有nms,后处理无需offload到cpu。 和ViT一样,基本上能无缝使用绝大多数transformer推理优化策略。 劣势
从检测的典型负载而言,这个计算量还是偏大。达到同样的算法效果,相比CNN时代检测头组合,开销太大,还是有点得不偿失。
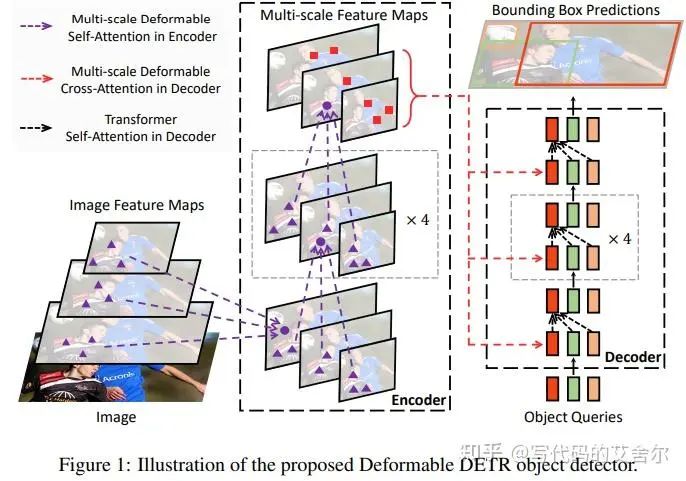
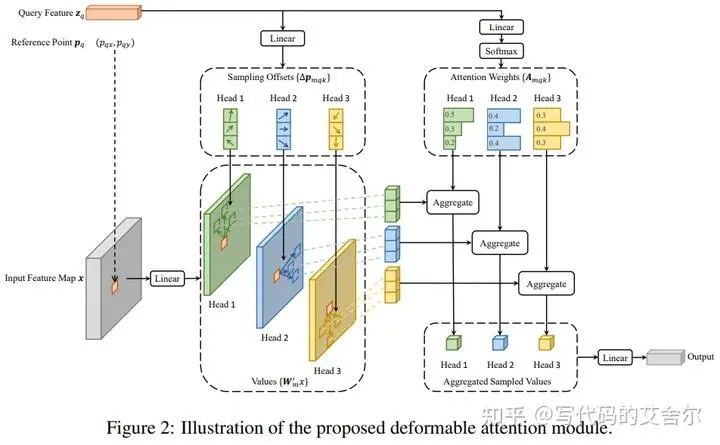
整体流程上:Deformable DETR的流程有点复杂,我是扫了代码转了模型,才品出门道。感觉单凭上面两张结构图,似乎不容易搞懂。我尝试以模型结构的视角简练地解读一把:Deformable DETR接收主干提取的多尺度视觉特征,送入其定制的DeformableTransformer结构中。在该结构内,query特征存在视觉多尺度和序列两种表示形式。基于序列特征预测感兴趣特征点的坐标(Fig2中的referencepoints)与偏移(Fig2中的offset),再按该坐标分别从多尺度视觉特征中抽取特征点并结合序列特征计算得到的权重,得到下一轮DeformableTransformer的query输入。 算法角度上:降低了训练的难度。
优势
好像很难给Deformable DETR找一个部署层面的优点,硬要说的话,其魔改的DeformableAttention矩阵计算确实要少一点。 劣势
如果WindowPartition和WindowUnpartition在模型中不断插入的数据reorder(permute)对端侧性能有冲击的话,我想DeformableAttention的高频grid_sample抽取特征点的操作,对不灵活低带宽的端侧只能用灾难来形容。 更不要说多尺度视觉特征与序列特征切换时引入的特化split(非等分切分)和高维permute了。
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection, 2022,在DeformableDETR基础上进一步引入了query selection,在解码阶段增加了目标优选(topk+gather)。
点云篇
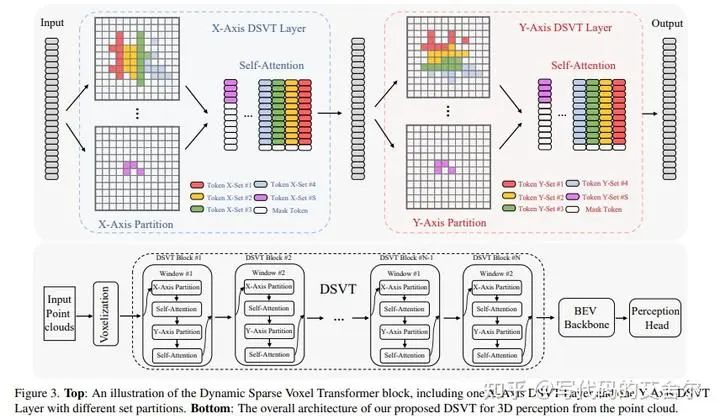
整体流程上:整个DSVT的pipeline(上图中的DSVT部分)可以理解为点云版本的swintransformer。1). 可并行的局部自注意力:DSVT将稀疏voxel分为多窗口并最终分为等数量的set,针对每个set做attention。2). 全局信息流通(shift窗口滑动):DSVT分别对x/y做partition。 数据的切换方式:预先记录在x/y方向排序对应至voxel特征上的索引,并通过gather/scatter实现数据在voxel点云特征空间和transformer序列特征空间之间的切换。 流程中的Voxelization和BEV都是领域专业术语,本文不做讨论,voxel部分可参考VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection CVPR 2018。 DSVT和SwinTransformer除了流程之外,典型负载也比较相似(DSVT中set)
优势
继承了WindowAttention的所有收益。降低了计算量、单一矩阵的计算规模,提升了计算的并行度。 劣势
数据在transformer序列特征空间和voxel点云特征空间下的切换成本远高于其与视觉特征的。一是scatter/gather这类数据随机访问(shuffle)远比数据重排操作(reorder)耗时,二是这些操作操作在端侧的支持性是个问号。全部offload给cpu吗,这不是开玩笑。 一句话,端侧不友好跟DSVT本身没关系,是基因不好吃了点云数据结构的亏。
多模态篇
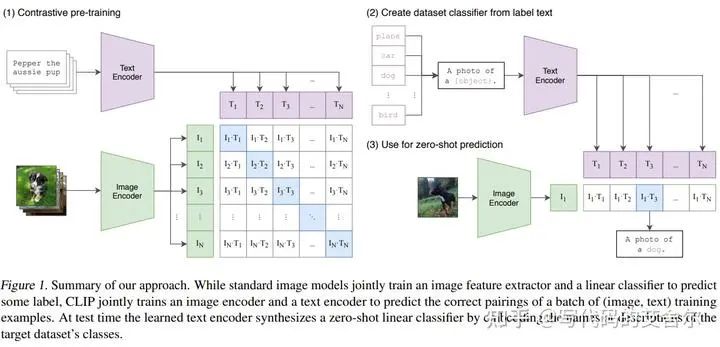
简介
整体流程上:图片编码和文本编码部分各经过transformer encoder(也可以是其他编码结构),再对各自的编码特征做多模态融合(norm),再计算彼此的余弦相似度(matmul, cos)。
端侧视角下的优劣
优点
和ViT一样,简单质朴的结构,大道至简的践行者,这对端侧落地是一个利好。 缺点
包含prompt engineering的text encoder,其输入文本序列会随应用上下文实时改变,对端侧软件栈的动态shape支持性提出了更高的要求。
轻量级Transformer
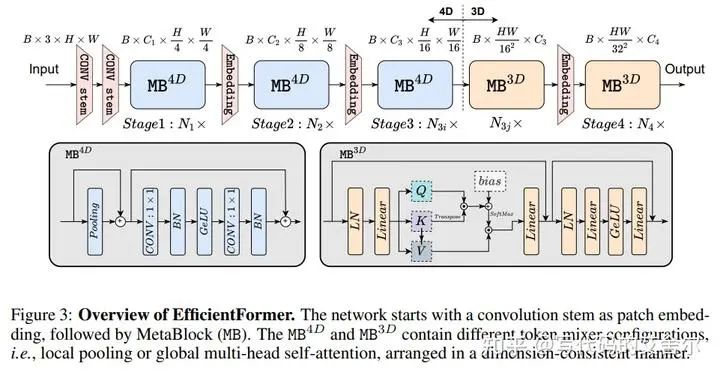
EfficientFormer: Vision Transformers at MobileNet Speed NIPS 2022
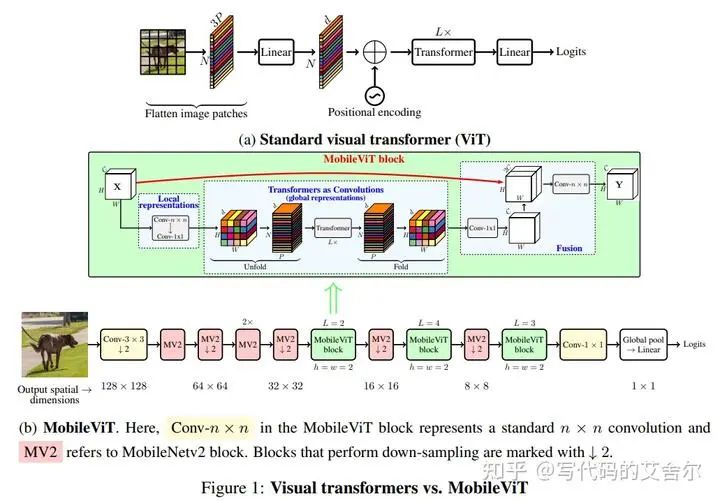
MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformerarxiv 2021
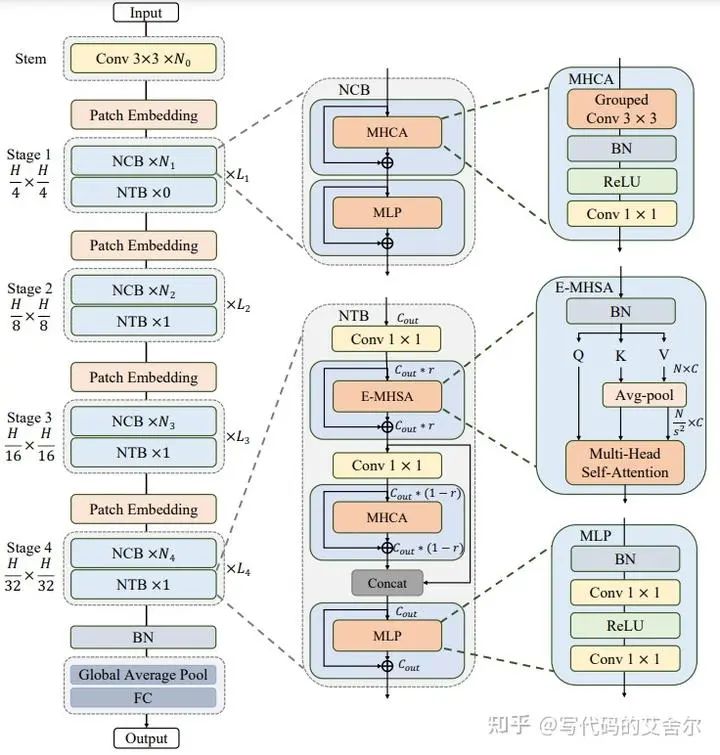
Next-ViT: Next Generation Vision Transformer for Efficient Deployment in Realistic Industrial Scenarios, 2022
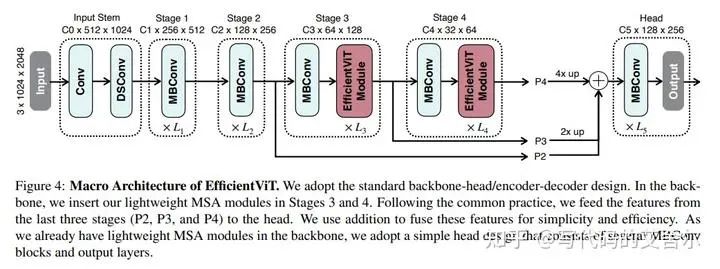
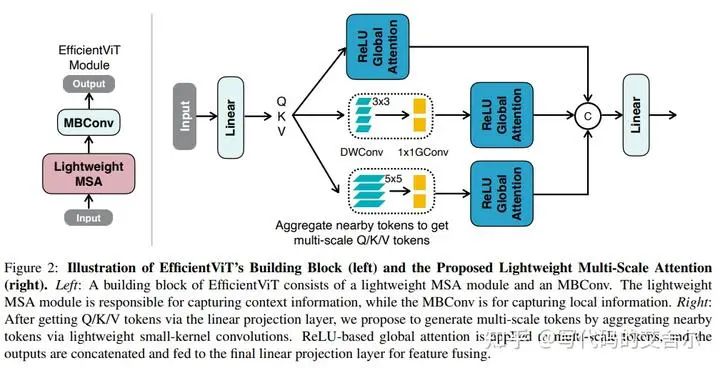
EfficientViT: Lightweight Multi-Scale Attention for On-Device Semantic Segmentation, ECCV, 2022
总结
更好的编程性
更合理的资源配置
更贴合的缓存尺寸。无论是受限于WindowAttention的视觉主干和点云DSVT,还是受限于Detection Objects的检测任务QueryEmbedding,亦或是多模态精简的prompt,这些算法在设计上都暗示了序列长度并不会随模型计算量增大而无限膨胀。简单算一下各模态transformer较大的参数配置场景(mlp_ratio=4, queryobj=seqlen=1024, embed_dim=1024),8M高速缓存就能把完全兜住单batch8bit推理时任何单一计算的权重数据。所以没必要无限堆料,尺寸到位就行。
有潜在优势的多核设计。从SwinTransformer/ViTDet等workload来看,在强调局部性的任务中算法建模有更高的意愿将Transformer的注意力输入改造代表局部特征的相互独立的子序列。在这种情况下,多核设计的收益将更加的明显。
更精准的算力定位。 目前来看,transformer时代算法存在两种创新模式,一种是轻量化Transformer,与CNN深度结合,在原有结构不变的前提下,引入少量Transformer模块,走底层路线;另一种是基于模态特点,引入新算子适配特征数据,做Transformer定制化,走的是上层路线。路线之争我不敢妄议,但有一点可以肯定,这两者的算力区间是截然不同的。一款AI芯片的设计定位,不能摇摆模糊,只能二选一。两头都要,底层路线没有价格优势,上层路线算力资源又跟不上,结果可能会比较难看。因此,需要团队里的软硬件协同研究员们在设计阶段的更多投入,把握好transformer效果优势的边界点。
更精细的Buffer建模
这些workload充分体现了:
非语言模型跨特征空间的求解述求。数据会在序列特征和其他模态特征上来回切换,以寻求更好的特征抽取。比如SwinT中图像特征下的shift与降采样,以及序列特征下的Attention与FFN,再比如DSVT在点云特征下的特征分组,和同样序列特征下的Attention/FFN。 位置信息的花式编码述求。比如RoPE,以及DINO中的这个解码端position操作。
若IR层级的Buffer建模能从tensor颗粒度直线跨越到item颗粒度,那么一方面,跨特征空间切换所引入的reorder(permute)和shuffle(grid_sample/gather)操作将能被更好的刻画,从而拥有了进一步挖掘其与前继与后继的eltwise/gemm节点融合的空间,另一方面,花式位置编码(RoPE等)计算子图中各Buffer间的集合和依赖关系也将被更好的建模,从而使整个子图从multipass转换为1pass成为可能。这些性能收益的叠加很可能成为最终性能对标时的胜负手。
更高扩展性的软件栈
Transformer算法的这些特性对软件栈的支持性上也有一定的影响:
各模态Transformer引入的特殊算子中,除了shuffle类操作,绝大多数workload(高维张量运算,高维Permute,非等分Split等)都是编译软件栈的权责范畴,由它将这些负载平凡化并完成硬件适配。 虽然除了多模态之外的workload并没有对动态Shape存在强烈诉求,但鉴于多模态模型所展示的巨大潜力,编译软件栈还是有必要提前布局动态Shape,并做好合理的版本规划。
而这些在CNN时代可能压根没被纳入测试用例,甚至是功能清单。显然,这是AI芯片编译软件栈的可扩展性提出了更高的要求。设计上的考量维度太多,但测试这个方面,我倒是觉得到了上马Fuzz的阶段了,顺带推一手之前的文章。
深度学习测试漫谈:https://zhuanlan.zhihu.com/p/630202674
也许能从后续的SDK版本更迭和release note中窥探一下各家的应对情况(笑)。
写在最后
写完才发现,居然把语音篇忘了。好在扫完全文发现,似乎没对文章主线造成影响,那就以后再更吧。 软硬件协同是一个庞大的议题,本文所讨论的也只是其中的一小部分,希望能引发更多的讨论和思考,和大家共同成长。
推荐阅读

AIHIA | AI人才创新发展联盟2023年盟友招募
AIHIA | AI人才创新发展联盟2023年盟友招募

AI融资 | 智能物联网公司阿加犀获得高通5000W融资
AI融资 | 智能物联网公司阿加犀获得高通5000W融资

Yolov5应用 | 家庭安防告警系统全流程及代码讲解

江大白 | 这些年从0转行AI行业的一些感悟
Yolov5应用 | 家庭安防告警系统全流程及代码讲解
江大白 | 这些年从0转行AI行业的一些感悟

《AI未来星球》陪伴你在AI行业成长的社群,各项福利重磅开放:
(1)198元《31节课入门人工智能》视频课程;
(2)大白花费近万元购买的各类数据集;
(3)每月自习活动,每月17日星球会员日,各类奖品送不停;
(4)加入《AI未来星球》内部微信群;
还有各类直播时分享的文件、研究报告,一起扫码加入吧!


大家一起加油! 
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢