

以下文章来源于知乎:算法邦
作者:算法邦
链接:https://mp.weixin.qq.com/s/-HAUnLMBv3mSHzNbmEHmlA
本文仅用于学术分享,如有侵权,请联系后台作删文处理

AI集群
由于目前只有3台A800 GPU服务器(共24卡),基于目前现有的一些AI框架和大模型,无法充分利用3台服务器。比如:OPT-66B一共有64层Transformer,当使用Alpa进行流水线并行时,通过流水线并行对模型进行切分,要么使用16卡,要么使用8卡,没法直接使用24卡,因此,GPU服务器最好是购买偶数台(如:2台、4台、8台)。
具体的硬件配置如下:



AI处理器(加速卡)
Tesla:A100(A800)、H100(H800)、A30、A40、V100、P100... GeForce:RTX 3090、RTX 4090 ... Quadro:RTX 6000、RTX 8000 ...
A100的Nvlink最大总网络带宽为600GB/s,而A800的Nvlink最大总网络带宽为400GB/s。 H100的Nvlink最大总网络带宽为900GB/s,而A800的Nvlink最大总网络带宽为400GB/s。
AMD:GPU MI300X Intel:Xeon Phi Google:TPU
华为:昇腾910(用于训练和推理),昇腾310(用于推理)。采用自家设计的达芬奇架构。 海光DCU:8100系列(深算一号),以GPGPU架构为基础。 寒武纪:思元370、思元590。 百度:昆仑芯,采用的是其自研XPU架构。 阿里:含光800。
大模型算法
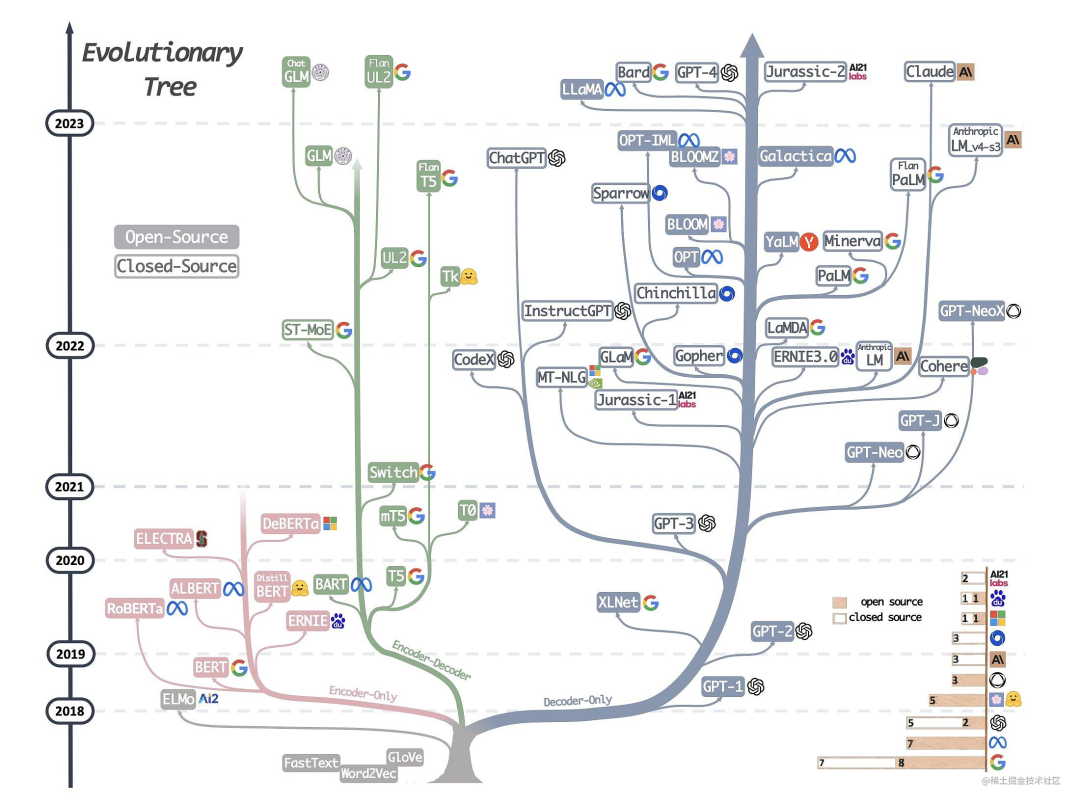
仅编码器架构(Encoder-only):自编码模型(破坏一个句子,然后让模型去预测或填补),更擅长理解类的任务,例如:文本分类、实体识别、关键信息抽取等。典型代表有:Bert、RoBERTa等。 仅解码器架构(Decoder-only):自回归模型(将解码器自己当前步的输出加入下一步的输入,解码器融合所有已经输入的向量来输出下一个向量,所以越往后的输出考虑了更多输入),更擅长生成类的任务,例如:文本生成。典型代表有:GPT系列、LLaMA、OPT、Bloom等。 编码器-解码器架构(Encoder-Decoder):序列到序列模型(编码器的输出作为解码器的输入),主要用于基于条件的生成任务,例如:翻译,概要等。典型代表有:T5、BART、GLM等。
大语言模型
ChatGLM-6B / ChatGLM2-6B :清华开源的中英双语的对话语言模型。目前,第二代ChatGLM在官网允许的情况下可以进行商用。
GLM-10B/130B :双语(中文和英文)双向稠密模型。
OPT-2.7B/13B/30B/66B :Meta开源的预训练语言模型。
LLaMA-7B/13B/30B/65B :Meta开源的基础大语言模型。
Alpaca(LLaMA-7B):斯坦福提出的一个强大的可复现的指令跟随模型,种子任务都是英语,收集的数据也都是英文,因此训练出来的模型未对中文优化。
BELLE(BLOOMZ-7B/LLaMA-7B/LLaMA-13B):本项目基于 Stanford Alpaca,针对中文做了优化,模型调优仅使用由ChatGPT生产的数据(不包含任何其他数据)。
Bloom-7B/13B/176B:可以处理46 种语言,包括法语、汉语、越南语、印度尼西亚语、加泰罗尼亚语、13 种印度语言(如印地语)和 20 种非洲语言。其中,Bloomz系列模型是基于 xP3 数据集微调。推荐用于英语的提示(prompting);Bloomz-mt系列模型是基于 xP3mt 数据集微调。推荐用于非英语的提示(prompting)。
Vicuna(7B/13B):由UC Berkeley、CMU、Stanford和 UC San Diego的研究人员创建的 Vicuna-13B,通过在 ShareGPT 收集的用户共享对话数据中微调 LLaMA 获得。其中,使用 GPT-4 进行评估,发现 Vicuna-13B 的性能在超过90%的情况下实现了与ChatGPT和Bard相匹敌的能力;同时,在 90% 情况下都优于 LLaMA 和 Alpaca 等其他模型。而训练 Vicuna-13B 的费用约为 300 美元。不仅如此,它还提供了一个用于训练、服务和评估基于大语言模型的聊天机器人的开放平台:FastChat。
Baize:白泽是在LLaMA上训练的。目前包括四种英语模型:白泽-7B、13B 、 30B(通用对话模型)以及一个垂直领域的白泽-医疗模型,供研究 / 非商业用途使用,并计划在未来发布中文的白泽模型。白泽的数据处理、训练模型、Demo 等全部代码已经开源。
LLMZoo:来自香港中文大学和深圳市大数据研究院团队推出的一系列大模型,如:Phoenix(凤凰) 和 Chimera等。
MOSS:由复旦 NLP 团队推出的 MOSS 大语言模型。
baichuan-7B:由百川智能推出的大模型,可进行商用。
CPM-Bee:百亿参数的开源中英文双语基座大模型,可进行商用。
20230325(当时官方还未开源训练代码,目前直接基于官方的训练代码即可): 前两天测试了BELLE,对中文的效果感觉还不错。具体的模型训练(预训练)方法可参考Hugingface Transformers的样例,SFT(指令精调)方法可参考Alpaca的训练代码。
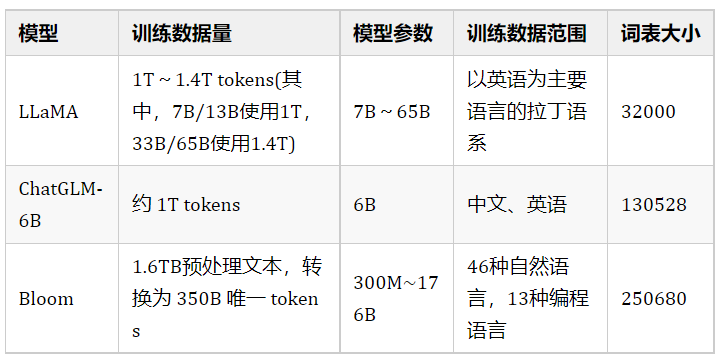
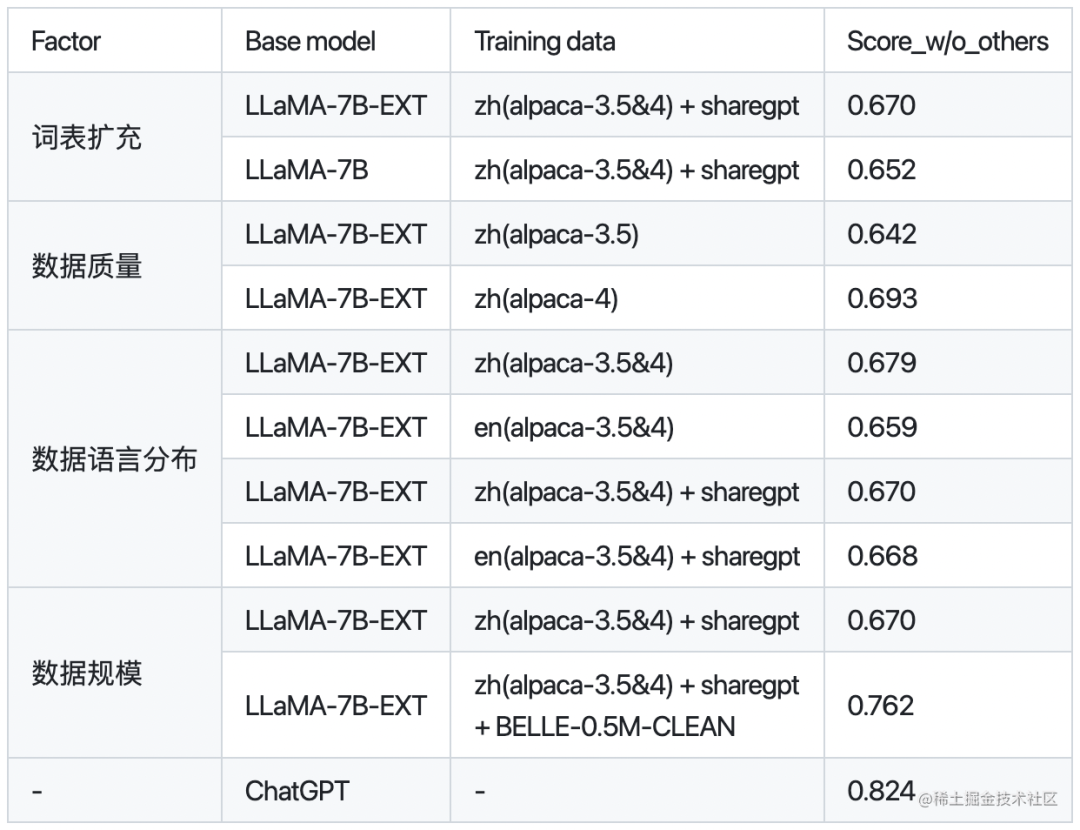
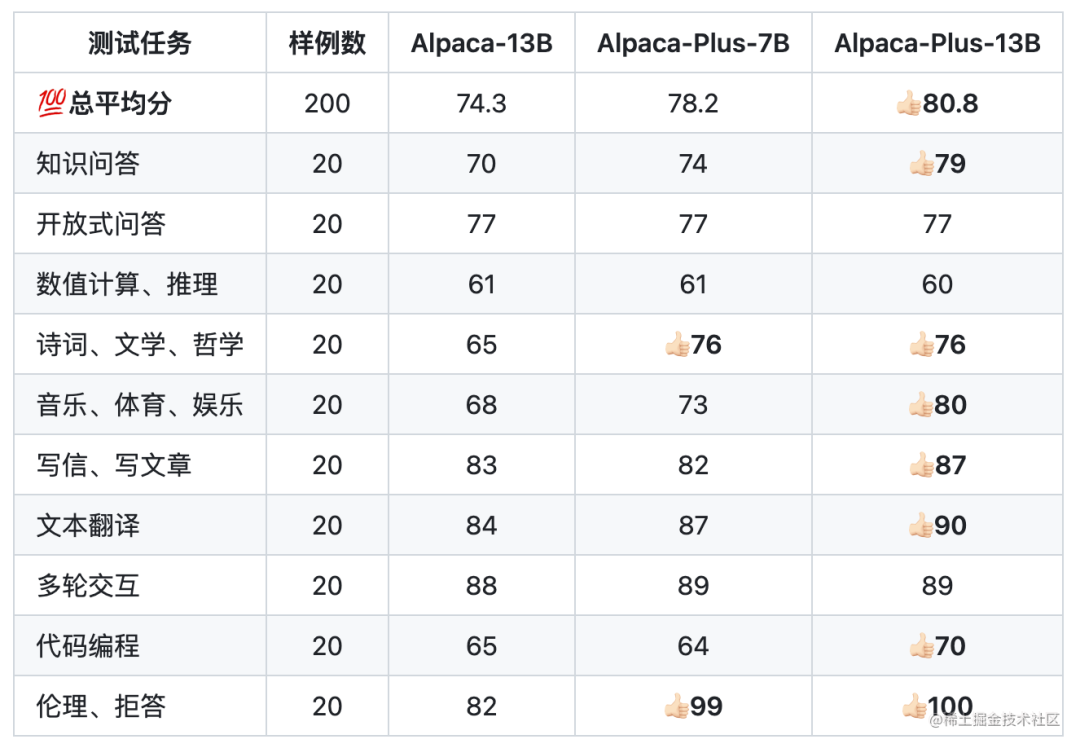
如果不扩充词表,对于中文效果怎么样?根据Vicuna官方的报告,经过Instruction Turing的Vicuna-13B已经有非常好的中文能力。 LLaMA需不需要扩充词表?根据Chinese-LLaMA-Alpaca和BELLE的报告,扩充中文词表,可以提升中文编解码效率以及模型的性能。但是扩词表,相当于从头初始化开始训练这些参数。如果想达到比较好的性能,需要比较大的算力和数据量。同时,Chinese-LLaMA-Alpaca也指出在进行第一阶段预训练(冻结transformer参数,仅训练embedding,在尽量不干扰原模型的情况下适配新增的中文词向量)时,模型收敛速度较慢。如果不是有特别充裕的时间和计算资源,建议跳过该阶段。因此,虽然扩词表看起来很诱人,但是实际操作起来,还是很有难度的。
多模态大模型
MiniGPT-4:沙特阿拉伯阿卜杜拉国王科技大学的研究团队开源。 LLaVA:由威斯康星大学麦迪逊分校,微软研究院和哥伦比亚大学共同出品。 VisualGLM-6B:开源的,支持图像、中文和英文的多模态对话语言模型,语言模型基于 ChatGLM-6B,具有 62 亿参数;图像部分通过训练 BLIP2-Qformer 构建起视觉模型与语言模型的桥梁,整体模型共78亿参数。 VisCPM:于CPM基础模型的中英双语多模态大模型。
领域大模型
金融领域大模型
轩辕:在BLOOM-176B的基础上针对中文通用领域和金融领域进行了针对性的预训练与微调。 Cornucopia(聚宝盆):开源了经过中文金融知识指令精调/指令微调(Instruct-tuning) 的LLaMA-7B模型。通过中文金融公开数据+爬取的金融数据构建指令数据集,并在此基础上对LLaMA进行了指令微调,提高了 LLaMA 在金融领域的问答效果。基于相同的数据,后期还会利用GPT3.5 API构建高质量的数据集,另在中文知识图谱-金融上进一步扩充高质量的指令数据集。 BBT-FinCUGE-Applications:开源了中文金融领域开源语料库BBT-FinCorpus,中文金融领域知识增强型预训练语言模型BBT-FinT5及中文金融领域自然语言处理评测基准CFLEB。
法律领域大模型
ChatLaw:由北京大学开源的大模型,主要有13B、33B。 LexiLaw:LexiLaw 是一个经过微调的中文法律大模型,它基于 ChatGLM-6B 架构,通过在法律领域的数据集上进行微调,使其在提供法律咨询和支持方面具备更高的性能和专业性。 LaWGPT:该系列模型在通用中文基座模型(如 Chinese-LLaMA、ChatGLM 等)的基础上扩充法律领域专有词表、大规模中文法律语料预训练,增强了大模型在法律领域的基础语义理解能力。在此基础上,构造法律领域对话问答数据集、中国司法考试数据集进行指令精调,提升了模型对法律内容的理解和执行能力。 Lawyer LLaMA:开源了一系列法律领域的指令微调数据和基于LLaMA训练的中文法律大模型的参数。Lawyer LLaMA 首先在大规模法律语料上进行了continual pretraining。在此基础上,借助ChatGPT收集了一批对中国国家统一法律职业资格考试客观题(以下简称法考)的分析和对法律咨询的回答,利用收集到的数据对模型进行指令微调,让模型习得将法律知识应用到具体场景中的能力。
医疗领域大模型
DoctorGLM:基于 ChatGLM-6B的中文问诊模型,通过中文医疗对话数据集进行微调,实现了包括lora、p-tuningv2等微调及部署。 BenTsao:源了经过中文医学指令精调/指令微调(Instruct-tuning) 的LLaMA-7B模型。通过医学知识图谱和GPT3.5 API构建了中文医学指令数据集,并在此基础上对LLaMA进行了指令微调,提高了LLaMA在医疗领域的问答效果。 BianQue:一个经过指令与多轮问询对话联合微调的医疗对话大模型,基于ClueAI/ChatYuan-large-v2作为底座,使用中文医疗问答指令与多轮问询对话混合数据集进行微调。 HuatuoGPT:开源了经过中文医学指令精调/指令微调(Instruct-tuning)的一个GPT-like模型。 Med-ChatGLM:基于中文医学知识的ChatGLM模型微调,微调数据与BenTsao相同。 QiZhenGPT:该项目利用启真医学知识库构建的中文医学指令数据集,并基于此在LLaMA-7B模型上进行指令精调,大幅提高了模型在中文医疗场景下效果,首先针对药品知识问答发布了评测数据集,后续计划优化疾病、手术、检验等方面的问答效果,并针对医患问答、病历自动生成等应用展开拓展。 XrayGLM:该项目为促进中文领域医学多模态大模型的研究发展,发布了XrayGLM数据集及模型,其在医学影像诊断和多轮交互对话上显示出了非凡的潜力。 MedicalGPT:训练医疗大模型,实现包括二次预训练、有监督微调、奖励建模、强化学习训练。发布中文医疗LoRA模型shibing624/ziya-llama-13b-medical-lora,基于Ziya-LLaMA-13B-v1模型,SFT微调了一版医疗模型,医疗问答效果有提升,发布微调后的LoRA权重。
教育领域大模型
桃李(Taoli):一个在国际中文教育领域数据上进行了额外训练的模型。项目基于目前国际中文教育领域流通的500余册国际中文教育教材与教辅书、汉语水平考试试题以及汉语学习者词典等,构建了国际中文教育资源库,构造了共计 88000 条的高质量国际中文教育问答数据集,并利用收集到的数据对模型进行指令微调,让模型习得将知识应用到具体场景中的能力。 EduChat:该项目华东师范大学计算机科学与技术学院的EduNLP团队研发,主要研究以预训练大模型为基底的教育对话大模型相关技术,融合多样化的教育垂直领域数据,辅以指令微调、价值观对齐等方法,提供教育场景下自动出题、作业批改、情感支持、课程辅导、高考咨询等丰富功能,服务于广大老师、学生和家长群体,助力实现因材施教、公平公正、富有温度的智能教育。
数学领域大模型
chatglm-maths:基于chatglm-6b微调/LORA/PPO/推理的数学题解题大模型, 样本为自动生成的整数/小数加减乘除运算, 可gpu/cpu部署,开源了训练数据集等。
RLHF(人工反馈强化学习)
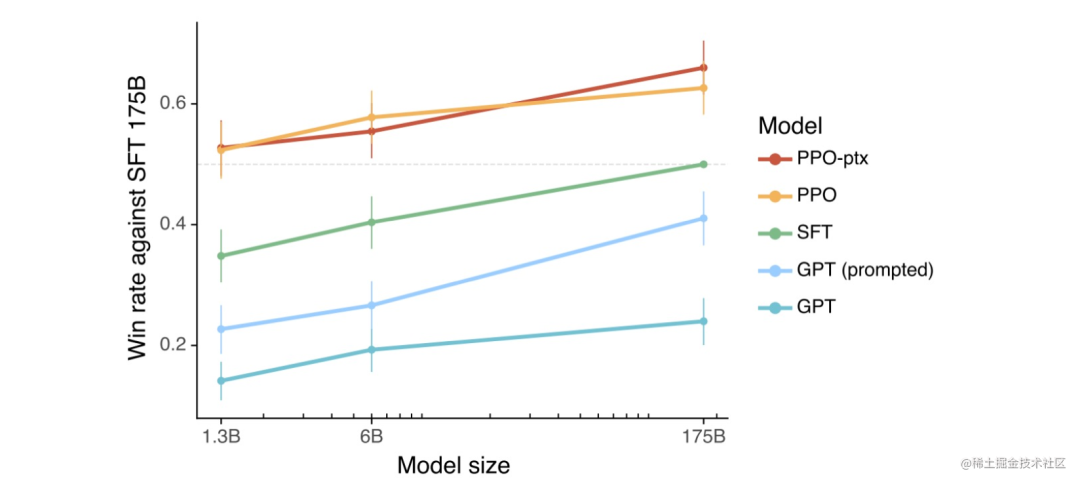
RLHF开源工具
DeepSpeed Chat:基于Opt系列模型进行示例。 ColossalChat:基于LLaMA系列模型进行示例。
分布式并行及显存优化技术
数据并行(如:PyTorch DDP) 模型/张量并行(如:Megatron-LM(1D)、Colossal-AI(2D、2.5D、3D)) 流水线并行(如:GPipe、PipeDream、PipeDream-2BW、PipeDream Flush(1F1B)) 多维混合并行(如:3D并行(数据并行、模型并行、流水线并行)) 自动并行(如:Alpa(自动算子内/算子间并行)) 优化器相关的并行(如:ZeRO(零冗余优化器,在执行的逻辑上是数据并行,但可以达到模型并行的显存优化效果)、PyTorch FSDP)
重计算(Recomputation):Activation checkpointing(Gradient checkpointing),本质上是一种用时间换空间的策略。 卸载(Offload)技术:一种用通信换显存的方法,简单来说就是让模型参数、激活值等在CPU内存和GPU显存之间左右横跳。如:ZeRO-Offload、ZeRO-Infinity等。 混合精度(BF16/FP16):降低训练显存的消耗,还能将训练速度提升2-4倍。 BF16 计算时可避免计算溢出,出现Inf case。 FP16 在输入数据超过65506 时,计算结果溢出,出现Inf case。
分布式训练框架
训练成本:不同的训练工具,训练同样的大模型,成本是不一样的。对于大模型,训练一次动辄上百万/千万美元的费用。合适的成本始终是正确的选择。 训练类型:是否支持数据并行、张量并行、流水线并行、多维混合并行、自动并行等 效率:将普通模型训练代码变为分布式训练所需编写代码的行数,我们希望越少越好。 灵活性:你选择的框架是否可以跨不同平台使用?
第一类:深度学习框架自带的分布式训练功能。如:TensorFlow、PyTorch、MindSpore、Oneflow、PaddlePaddle等。 第二类:基于现有的深度学习框架(如:PyTorch、Flax)进行扩展和优化,从而进行分布式训练。如:Megatron-LM(张量并行)、DeepSpeed(Zero-DP)、Colossal-AI(高维模型并行,如2D、2.5D、3D)、Alpa(自动并行)等
TPU + XLA + TensorFlow/JAX :由Google主导,由于TPU和自家云平台GCP深度绑定。 GPU + PyTorch + Megatron-LM + DeepSpeed :由NVIDIA、Meta、MicroSoft大厂加持,社区氛围活跃,也更受到大家欢迎。
参数高效微调(PEFT)技术
Prefix Tuning:与full fine-tuning更新所有参数的方式不同,该方法是在输入token之前构造一段任务相关的virtual tokens作为Prefix,然后训练的时候只更新Prefix部分的参数,而Transformer中的其他部分参数固定。该方法其实和构造Prompt类似,只是Prompt是人为构造的“显式”的提示,并且无法更新参数,而Prefix则是可以学习的“隐式”的提示。同时,为了防止直接更新Prefix的参数导致训练不稳定的情况,他们在Prefix层前面加了MLP结构(相当于将Prefix分解为更小维度的Input与MLP的组合后输出的结果),训练完成后,只保留Prefix的参数。 Prompt Tuning:该方法可以看作是Prefix Tuning的简化版本,只在输入层加入prompt tokens,并不需要加入MLP进行调整来解决难训练的问题。随着预训练模型参数量的增加,Prompt Tuning的方法会逼近fine-tuning的结果。 P-Tuning:该方法的提出主要是为了解决这样一个问题:大模型的Prompt构造方式严重影响下游任务的效果。P-Tuning将Prompt转换为可以学习的Embedding层,并用MLP+LSTM的方式来对prompt embedding进行一层处理。 P-Tuning v2:让Prompt Tuning能够在不同参数规模的预训练模型、针对不同下游任务的结果上都达到匹敌Fine-tuning的结果。相比Prompt Tuning和P-tuning的方法,P-Tuning v2方法在多层加入了Prompts tokens作为输入,带来两个方面的好处: 带来更多可学习的参数(从P-tuning和Prompt Tuning的0.1%增加到0.1%-3%),同时也足够参数高效。 加入到更深层结构中的Prompt能给模型预测带来更直接的影响。 Adapter Tuning:该方法设计了Adapter结构(首先是一个down-project层将高维度特征映射到低维特征,然后过一个非线形层之后,再用一个up-project结构将低维特征映射回原来的高维特征;同时也设计了skip-connection结构,确保了在最差的情况下能够退化为identity),并将其嵌入Transformer的结构里面,在训练时,固定住原来预训练模型的参数不变,只对新增的Adapter结构进行微调。同时为了保证训练的高效性(也就是尽可能少的引入更多参数)。 LoRA:在涉及到矩阵相乘的模块,引入A、B这样两个低秩矩阵模块去模拟full fine-tuning的过程,相当于只对语言模型中起关键作用的低秩本质维度进行更新。 QLoRA:使用一种新颖的高精度技术将预训练模型量化为 4 bit,然后添加一小组可学习的低秩适配器权重,这些权重通过量化权重的反向传播梯度进行微调。目前,训练速度较慢。 AdaLoRA:对LoRA的一种改进,它根据重要性评分动态分配参数预算给权重矩阵。
ChatGLM-Tuning :一种平价的chatgpt实现方案,基于清华的 ChatGLM-6B + LoRA 进行finetune。 Alpaca-Lora:使用低秩自适应(LoRA)复现斯坦福羊驼的结果。Stanford Alpaca 是在 LLaMA 整个模型上微调,而 Alpaca-Lora 则是利用 Lora 技术,在冻结原模型 LLaMA 参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。由于这些新增参数数量较少,这样不仅微调的成本显著下降,还能获得和全模型微调类似的效果。 BLOOM-LORA:由于LLaMA的限制,我们尝试使用Alpaca-Lora重新实现BLOOM-LoRA。
PEFT:Huggingface推出的PEFT库。 unify-parameter-efficient-tuning:一个参数高效迁移学习的统一框架。
推理速度会变慢 模型精度会变差
影响大模型性能的主要因素
衡量大模型水平
理解能力:提出一些需要深入理解文本的问题,看模型是否能准确回答。 语言生成能力:让模型生成一段有关特定主题的文章或故事,评估其生成的文本在结构、逻辑和语法等方面的质量。 知识面广度:请模型回答关于不同主题的问题,以测试其对不同领域的知识掌握程度。这可以是关于科学、历史、文学、体育或其他领域的问题。一个优秀的大语言模型应该可以回答各种领域的问题,并且准确性和深度都很高。 适应性:让模型处理各种不同类型的任务,例如:写作、翻译、编程等,看它是否能灵活应对。 长文本理解:提出一些需要处理长文本的问题,例如:提供一篇文章,让模型总结出文章的要点,或者请模型创作一个故事或一篇文章,让其有一个完整的情节,并且不要出现明显的逻辑矛盾或故事结构上的错误。一个好的大语言模型应该能够以一个连贯的方式讲述一个故事,让读者沉浸其中。 长文本生成:请模型创作一个故事或一篇文章,让其有一个完整的情节,并且不要出现明显的逻辑矛盾或故事结构上的错误。一个好的大语言模型应该能够以一个连贯的方式讲述一个故事,让读者沉浸其中。 多样性:提出一个问题,让模型给出多个不同的答案或解决方案,测试模型的创造力和多样性。 情感分析和推断:提供一段对话或文本,让模型分析其中的情感和态度,或者推断角色间的关系。 情感表达:请模型生成带有情感色彩的文本,如描述某个场景或事件的情感、描述一个人物的情感状态等。一个优秀的大语言模型应该能够准确地捕捉情感,将其表达出来。 逻辑推理能力:请模型回答需要进行推理或逻辑分析的问题,如概率或逻辑推理等。这可以帮助判断模型对推理和逻辑思考的能力,以及其在处理逻辑问题方面的准确性。例如:“所有的动物都会呼吸。狗是一种动物。那么狗会呼吸吗?” 问题解决能力:提出实际问题,例如:数学题、编程问题等,看模型是否能给出正确的解答。 道德和伦理:测试模型在处理有关道德和伦理问题时的表现,例如:“在什么情况下撒谎是可以接受的?” 对话和聊天:请模型进行对话,以测试其对自然语言处理的掌握程度和能力。一个优秀的大语言模型应该能够准确地回答问题,并且能够理解人类的语言表达方式。
由于评判聊天机器人聊得好不好这件事是非常主观的,因此,现有的方法很难对其进行衡量。 这些大模型在训练的时候就几乎把整个互联网的数据都扫了一个遍,因此,很难保证测试用的数据集没有被看到过。甚至更进一步,用测试集直接对模型进行「特训」,如此一来表现必然更好。 理论上我们可以和聊天机器人聊任何事情,但很多话题或者任务在现存的benchmark里面根本就不存在。
OpenAI evals:OpenAI的自动化评估脚本,核心思路就是通过写prompt模版来自动化评估。
PandaLM:其是直接训练了一个自动化打分模型,0,1,2三分制用模型对两个候选模型进行打分。
大模型推理加速
算法层面:蒸馏、量化 软件层面:计算图优化、模型编译 硬件层面:FP8(NVIDIA H系列GPU开始支持FP8,兼有fp16的稳定性和int8的速度)
FasterTransformer:英伟达推出的FasterTransformer不修改模型架构而是在计算加速层面优化 Transformer 的 encoder 和 decoder 模块。具体包括如下: 尽可能多地融合除了 GEMM 以外的操作 支持 FP16、INT8、FP8 移除 encoder 输入中无用的 padding 来减少计算开销 TurboTransformers:腾讯推出的 TurboTransformers 由 computation runtime 及 serving framework 组成。加速推理框架适用于 CPU 和 GPU,最重要的是,它可以无需预处理便可处理变长的输入序列。具体包括如下: 与 FasterTransformer 类似,它融合了除 GEMM 之外的操作以减少计算量 smart batching,对于一个 batch 内不同长度的序列,它也最小化了 zero-padding 开销 对 LayerNorm 和 Softmax 进行批处理,使它们更适合并行计算 引入了模型感知分配器,以确保在可变长度请求服务期间内存占用较小
AI 集群网络通信
通信硬件
共享内存,比如:CPU与CPU之间的通信可以通过共享内存。 PCIe,通常是CPU与GPU之间的通信,也可以用于GPU与GPU之间的通信。 NVLink(直连模式),通常是GPU与GPU之间的通信,也可以用于CPU与GPU之间的通信。
TCP/IP网络 RDMA:远程直接内存访问,目前主要有如下三种技术: InfiniBand iWarp RoCE v2
通信软件
Gloo:Facebook 开源的一套集体通信库,提供了对机器学习中有用的一些集合通信算法。 NCCL:英伟达基于 NVIDIA-GPU 的一套开源的集合通信库。 OpenMPI:一个开源 MPI(消息传递接口 )的实现,由学术,研究和行业合作伙伴联盟开发和维护。 HCCL:华为开发的网络通信库。
通信网络监控
nvbandwidth:用于测量 NVIDIA GPU 带宽的工具。 DCGM:一个用于收集telemetry数据和测量 NVIDIA GPU 运行状况。
大模型生态相关技术-新增
LLM 应用开发工具
langchain:一个用于构建基于大型语言模型(LLM)的应用程序的库。它可以帮助开发者将LLM 与其他计算或知识源结合起来,创建更强大的应用程序。 llama-index:一个将大语言模型和外部数据连接在一起的工具。 gpt-cache:LLM 语义缓存层(caching layer),它采用语义缓存(semantic cache)技术,能够存储 LLM 响应,从而显著减少检索数据所需的时间、降低 API 调用开销、提升应用可扩展性。
向量数据库
Pinecone Milvus Vespa Weaviate
经验与教训
对于同一模型,选择不同的训练框架,对于资源的消耗情况可能存在显著差异(比如使用Huggingface Transformers和DeepSpeed训练OPT-30相对于使用Alpa对于资源的消耗会低不少)。 进行大模型模型训练时,先使用小规模模型(如:OPT-125m/2.7b)进行尝试,然后再进行大规模模型(如:OPT-13b/30b...)的尝试,便于出现问题时进行排查。目前来看,业界也是基于相对较小规模参数的模型(6B/7B/13B)进行的优化,同时,13B模型经过指令精调之后的模型效果已经能够到达GPT4的90%的效果。 对于一些国产AI加速卡,目前来说,坑还比较多,如果时间不是时间非常充裕,还是尽量选择Nvidia的AI加速卡。
针对已有的环境进行分布式训练环境搭建时,一定要注意之前环境的python、pip、virtualenv、setuptools的版本。不然创建的虚拟环境即使指定对了Python版本,也可能会遇到很多安装依赖库的问题(GPU服务器能够访问外网的情况下,建议使用Docker相对来说更方便)。 遇到需要升级GLIBC等底层库需要升级的提示时,一定要慎重,不要轻易升级,否则,可能会造成系统宕机或很多命令无法操作等情况。
END
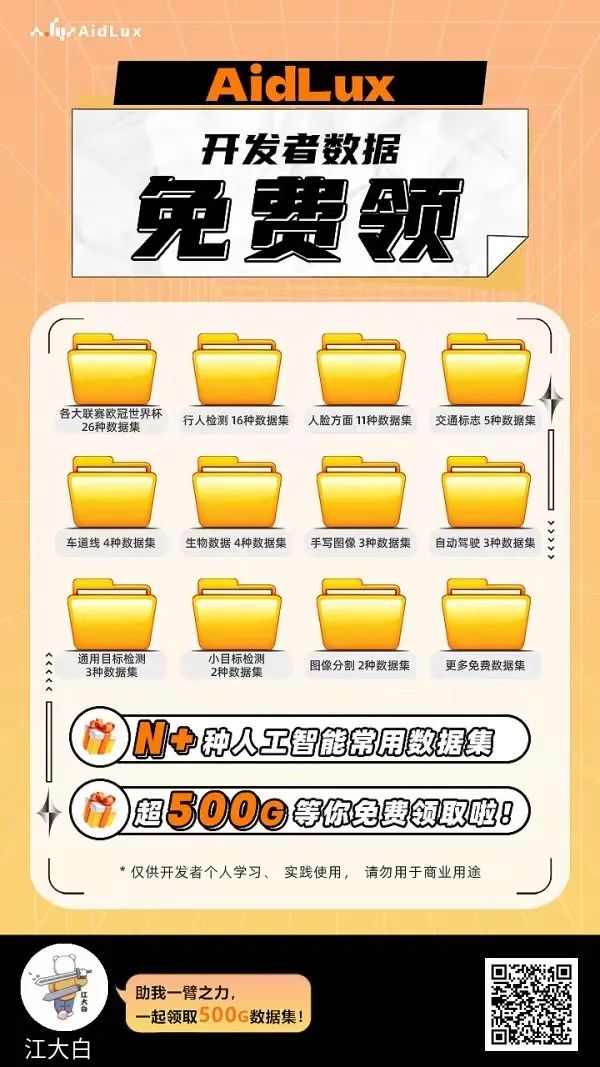
推荐阅读

AIHIA | AI人才创新发展联盟2023年盟友招募
AIHIA | AI人才创新发展联盟2023年盟友招募

AI融资 | 智能物联网公司阿加犀获得高通5000W融资
AI融资 | 智能物联网公司阿加犀获得高通5000W融资

Yolov5应用 | 家庭安防告警系统全流程及代码讲解

江大白 | 这些年从0转行AI行业的一些感悟
Yolov5应用 | 家庭安防告警系统全流程及代码讲解
江大白 | 这些年从0转行AI行业的一些感悟

《AI未来星球》陪伴你在AI行业成长的社群,各项福利重磅开放:
(1)198元《31节课入门人工智能》视频课程;
(2)大白花费近万元购买的各类数据集;
(3)每月自习活动,每月17日星球会员日,各类奖品送不停;
(4)加入《AI未来星球》内部微信群;
还有各类直播时分享的文件、研究报告,一起扫码加入吧!


大家一起加油! 
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢